
この記事は、The Parallel Universe Magazine 49 号に掲載されている「Free Your Software from Vendor Lock-in Using SYCL and oneAPI」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

アクセラレーターの利用は年々増加しており、特にソフトウェア開発者は GPU を活用し、さまざまな HPC やAI アルゴリズムを高度に並列化されたシステムで実行しています。MarketsandMarkets の調査 (英語) によると、データセンター・アクセラレーター市場は、2021 年の 137 億ドルから 2026 年には 653 億ドルに成長すると予測されています。
過去 10 年ほどの間、ソフトウェア開発者は、本来グラフィックス処理用に設計され、現在では AI やマシンラーニングを含む幅広い分野で使用されている GPU を利用する高度な並列ソフトウェアを記述するため、主に CUDA* に依存してきました。ソフトウェア開発者にとって、CUDA* は独自のプログラミング・インターフェイスであり、NVIDIA のプロセッサー上でしか使用できないことが課題でした。このため、開発者は単一ベンダーに縛られ、最新のプロセッサー・アーキテクチャーでのイノベーションが制限されてきました。
市場は変化しており、インテル (特に近日発売予定のインテル® Iris® Xe GPU) や、RISC-V* 命令セット・アーキテクチャーを利用した新しい特殊プロセッサーなど、幅広いプロセッサー・ベンダーからの選択肢が増えています。ソフトウェア開発者は、既存のプロセッサーを最大限に活用するだけでなく、この爆発的に増加する新しいアーキテクチャーやイノベーションに適応し、活用する必要がありますが、さまざまなベンダーの新しいプロセッサーごとに新しいコードを記述することなく、これを実現する方法はあるのでしょうか?
SYCL* と oneAPI は柔軟で非独占的な代替手段を提供します。SYCL* は、高度に並列化されたプロセッサー・ターゲット上で動作するソフトウェアを記述する、業界で定義されたロイヤルティー・フリーでオープンスタンダードのインターフェイスです。SYCL* はすでに広く採用されており、世界最速のスーパーコンピューターのいくつかでパフォーマンスの移植に使用されています。米国のアルゴンヌ国立研究所、ローレンス・バークレー国立研究所、オークリッジ国立研究所では、研究者が SYCL* を使用して、それぞれのスーパーコンピューター ― Aurora (インテル® GPU を使用)、Perlmutter、Polaris、Summit (NVIDIA* GPU を使用)、Frontier (AMD* GPU を使用) ― で実行可能なソフトウェアを記述し、最高のパフォーマンスを達成しています。ヨーロッパでは、Lumi スーパーコンピューター・チームが、ヨーロッパ大陸の既存および将来のマシンでパフォーマンスを移植するため、主要なプログラミング・モデルとして SYCL* を選択しています。また、ほかの政府機関や民間企業では、マルチベンダーのシステムに複雑なソフトウェアを導入するため SYCL* を採用しています。
SYCL* は、アクセラレーター・アーキテクチャー向けのオープンで標準ベースのプログラミング環境であるoneAPI の中核をなしています。oneAPI は、一般的なライブラリーとフレームワークを定義し実装することで、高度な並列ソフトウェアをさまざまなアーキテクチャーで実行し、ハイパフォーマンスと移植性を実現できるようにします。oneAPI には、高度に最適化されたアプリケーションの記述に必要なビルディング・ブロックと、一般的な数学およびニューラル・ネットワーク・アルゴリズムのライブラリーが含まれています。これにより、ソフトウェア開発者は、HPC および AI アプリケーションの作成に必要なすべてを手に入れることができます。
SYCL* は素晴らしいけれども、すべてのコードを CUDA* から SYCL* へ移行するのは難しいのではないか、と考える方もいらっしゃるでしょう。それがどれほど簡単かを示すため、N 体シミュレーション・プロジェクトを CUDA* から SYCL* に移行する方法を説明します。
N 体シミュレーションは、定義された一連の方程式を使用して、架空の銀河における重力相互作用を示すために使用されます (図 1)。このプロジェクトは、Sarah Le Luron 氏が C++ で記述した既存のオープンソースの N 体シミュレーションをベースにしています。このコードは、NVIDIA* GPU 上でシミュレーション計算の一部を並列に実行するカーネルを実装しており、CPU で実行する場合と比べて実行時間を短縮します。

図 1. 架空の銀河の N 体シミュレーション
このカーネルコードを SYCL* に移行するにはどうしたらよいのでしょうか? このプロジェクトではカーネルが 1 つですが、ほかのアプリケーションでは、コードベースに何百もの CUDA* カーネルがある可能性があります。
次のステップにより、手間のかかる作業の多くを排除し、開発時間を大幅に短縮できます。 最初のステップでは、最近オープンソース化された、CUDA* を SYCL* へ移行する半自動化ツールである SYCLomatic (英語) を使用します。このツールは、1 つまたは複数の CUDA* ソースファイルを SYCL* ソースコードに移行します。変換するソースファイルを指定するだけで、移行されたコードを含む C++ ソースファイルが生成されます。図 2 は、intercept-build スクリプトを使用したこの手順がいかに簡単であるかを示しています。このスクリプトは、コマンドとフラグを追跡して JSON ファイルに保存します。これは、複数のソースファイルを持つプロジェクトで便利です。移行するソースファイルを指定すると、SYCLomatic ツールは SYCL* コードファイル一式と、移行を単純化するいくつかのヘルパークラスや関数を生成します。
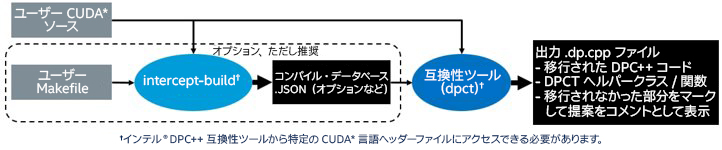
図 2. SYCLomatic のワークフロー
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
