

この記事は、インテル® デベロッパー・ゾーンに公開されている「Direct3D 12 Overview Part 6: Command Lists」(https://software.intel.com/en-us/blogs/2014/08/22/direct3d-12-overview-part-6-command-lists) の日本語参考訳です。
これまで、バンドル、PSO、記述子ヒープ&テーブルを通して、D3D 12 がどのように CPU の効率を改善し、開発者により多くの制御を与えるかを見てきました。PSO と記述子モデルは、順番に共通して繰り返されるコマンドで使用されるバンドルを可能にします。シンプルな “ハードウェアに近い” アプローチは、オーバーヘッドを軽減し、”コンソール API の効率とパフォーマンス” のため CPU をより効率良く利用ことを可能にします。パート 1 では、PC ゲームの世界では、他のスレッドが OS や システムタスクのみを処理する間、しばしばスレッド 0 が大部分の処理することを説明しました。複数のコアやスレッドを効率良く利用するのは、ゲームの世界では困難です。多くの場合、ゲームをマルチスレッド化する作業は労力とリソースの両面でコストがかかります。マイクロソフトは、D3D12 によってこの状況を変えようとしています。
コマンド生成の並列処理:
この D3D 12 概要シリーズでは、これまで何度かコマンド実行の遅延について触れてきました。実際にコマンドがキューに投入されて後で実行される場合、ゲームは各コマンドが即座に実行されると想定します。この機能は、D3D 12 でも残されていますが、ゲームからは透過になっています。もはや即時実行コンテキストは無く、すべては遅延実行コンテキストとなっています。そのため、スレッドはコマンドキューと呼ばれる API オブジェクトに送られるコマンドのリストを完成するため、並列にコマンドを生成することができます。GPU は、コマンドキューを介して送信されるまでコマンドを実行しません。キューは、順番に並んだコマンドであり、コマンドリストはコマンドの記録です。コマンドリストは、バンドルとは異なるのでしょうか? コマンドリストは、コマンドを一度だけ生成する用途に設計および最適化されており、スレッドは同時にコマンドを生成することができます。コマンドリストは一度だけ使用され、開発者はメモリーからリストを削除したり、その場所に新しいリストを記録することができます。バンドルは、単独のフレームもしくはフレーム間で繰り返し再利用される描画コマンド向けに設計されています。
コマンドの並列処理は、D3D 11 で試みられ、遅延コンテキストと呼ばれていました。しかし、オーバーヘッドが原因で D3D 開発チームはパフォーマンスの目標を達成できませんでした。さらなる解析によって、CPU コア間のスケーリングが乏しいことにより、シリアル・オーバーヘッドが多くある場所が特定されました。シリアル・オーバーヘッドの一部は、D3D 12 における CPU の効率化設計で排除されています。
リストとキュー:
描画コマンドのリストを生成する 2 つのスレッドを考えてみます。1 つのスレッドのコマンド・シーケンスは、一方の前に実行します。ハザードがある場合、それは 1 つのスレッドがテクスチャーなどのリソースを使用し、もう一方のスレッドが描画ターゲットとしてリソースを使用しているような状態です。ドライバーは、コヒーレント・データを確認し、描画時にリソースの利用状況を見てハザードを解決する必要があります。このハザード追跡は、D3D 11 ではシリアル化されたオーバーヘッドの領域であり、D3D 12 ではハザード追跡はドライバーではなくゲーム自身に責任があります。
D3D 11 は、任意の数のコンテキストの遅延を許しますが、それにはコストが伴います。ドライバーは、リソースごとの状態を追跡します。そのため、遅延コンテキスト用の記録コマンドを開始する際に、ドライバーは全てのリソースで使用されるメモリーを割り当てる必要があります。遅延コンテキストが生成されている間このメモリーは保持され、終了した時すべての追跡されたオブジェクトはメモリーから削除されなければいけません。D3D 12 では、API レベルでゲームが並列にコマンドリストの最大数を宣言するため、明らかにかなりのオーバーヘッドになります。ドライバーは、前もってコヒーレントな 1 つのメモリーにすべての追跡オブジェクトを設定して割り当てることができます。
D3D 11 では、ダイナミック・バッファー (コンテキスト、バーテックスなど) を使用するのが一般的でしたが、シーンの背景には、廃棄されたそれぞれのバッファーに複数のメモリーインスタンスの追跡が存在します。2 つのコマンドリストが同時に生成され、MapDiscard を呼びだすと想定します。一旦リストが送出されると、ドライバーは廃棄したバッファーの情報を補正するため、2 番目のコマンドリストにパッチを適用する必要があります。前述のハザードの例のように、これには多くのオーバーヘッドがかかります。D3D 12 は、ゲームにリネーム制御を可能とするため、ダイナミック・バッファーは必要ありません。ゲームが最粒度の制御を行うことに代わって、必要に応じて独自のアロケーターやサブ分割バッファーを構築できます。コマンドは、メモリー内の明示的なポイントを指すことができます。
パート 3 で述べたように、D3D 11 ではランタイムとドライバーがリソースの有効期間を追跡します。そのため、多くのリソースカウントと追跡が必要となり、それらは送出時にすべてが解決されていなければいけません。D3D 12 において、ゲームにリソース有効期間とハザードの制御が与えられ、より CPU を効率良く使用するためシリアル・オーバーヘッドが排除されました。これら 4 つの領域を最適化した後、D3D 12 における並列コマンド生成はより効率化され、CPU の並列性を改善することができます。これらの変更に加え、D3D 開発チームは新しいドライバーモデルである WDDM 2.0 を構築しています。WDDM 2.0 は、コマンドリストの送出コストを軽減するさらなる最適化機能を持っています。
コマンドキューの流れ:
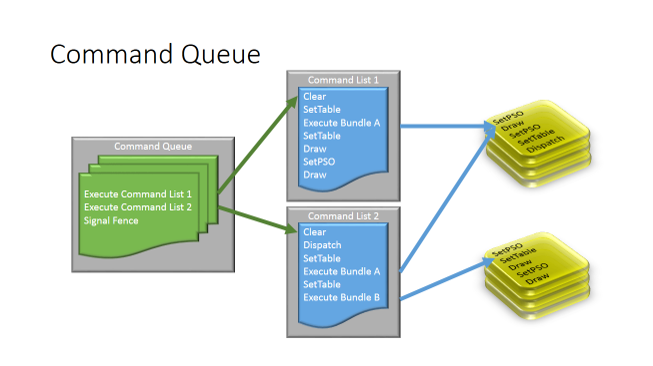
上記はパート 5 で紹介したバンドルの図ですが、ここではマルチスレッド化が行われています。左側はコマンドキューで、これは GPU に送出するイベント・シーケンスです。真ん中には、並列に生成された 2 つのコマンドリストがあります。右側には、このシナリオを開始する前に記録された 2 つのバンドルがあります。コマンドリストから始まり、ここではシーンの異なる領域に対して並列に 2 つのコマンドリストを生成できるようになりました。コマンドリスト 1 が記録を完了ると、GPU が実行を開始できるようコマンドキューに送出されます。したがって、コマンドキュー制御フローを開始し、並列にコマンドリスト 2 はスレッド 2 で記録を開始します。GPU がコマンドリスト 1 を実行する間、スレッド 2 はコマンドリスト 2 の生成を完了し、コマンドキューへ送出します。コマンドキューがコマンドリスト 1 の実行を終えると、シリアル順にコマンドリスト 2 を継続します。コマンドキューには、GPU がコマンドを実行するのに必要なシリアル順序で格納されています。GPU が、コマンドリスト 1 の実行を完了する前にコマンドリスト 2 が生成され、コマンドキューに送出されても、コマンドリスト 1 が完了するまでは実行されません。ご覧いただいたように、D3D 12 は、API とドライバーでコアとスレッドを使用し、全体の流れに渡って効率良い並列処理を提供しています。少ないオーバーヘッドで効率良く処理することで、より多くの処理を短い時間で完了できます。
次のパート 7 では、ダイナミック・ヒープについて説明します。
図とコード例は、BUILD 2014 のプレゼンテーションから抜粋しました。マイクロソフトの D3D 開発リードである Max McCullen によるプレゼンテーションから抜粋したものです。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
