

この記事は、インテルのウェブサイトで公開されている「Optimizing SLMs on Intel® Xeon® Processors: A llama.cpp Performance Study」を iSUS で翻訳した日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
小規模言語モデル (SLM) は、大規模言語モデルと比較して効率とパフォーマンスが高いことから、近年注目を集めています。これは、エッジサーバーやオフライン・エージェントなど、GPU 上に大規模言語モデル (LLM) をデプロイすることが現実的でない状況において特に重要です。
この記事では、GPT 生成統合フォーマット(GGUF)の量子化 SLM を使用して、応答性の高い CPU 向けのアプリケーションを実行する方法を紹介します。モデルの処理には、Python バインディングを備えた C/C++ LLM 推論フレームワークである llama.cpp を使用しています。これは、CPU パフォーマンス向けに単一命令複数データ (SIMD) 命令で最適化されています。ここでの lama.cpp の調査を通じて、ベースモデル、タスク、およびハードウェアにおいて、最高のスループットと並列効率を実現する量子化手法を特定します。
llama.cpp のビルド
要件: 計算負荷の高いワークロード向けに最適化されたパフォーマンス・コアを搭載したインテル® Xeon® 6 プロセッサーの Google Cloud インスタンスを使用しました。結果を再現する場合、console.cloud.google.com にアクセスし、課金設定を行って“Compute Engine”に移動してください。次に、左側のパネルからブートディスクのサイズを増やし、“Create instance”をクリックして仮想マシン (VM) を構成します。構成の詳細はこの記事の末尾に記載しています。(1)
まず、llama.cpp をローカル環境でビルドする手順を確認します。
ステップ 1: ターミナルを開き、システムパッケージを更新してアップグレードします。
| sudo apt update && sudo apt upgrade -y |
ステップ 2: 必要なツールとライブラリーをインストールします。
| sudo apt install git g++ cmake ninja-build libcurl4-openssl-dev -y |
ステップ 3: インテル® oneAPI ベース・ツールキットのオフライン・インストーラーをダウンロードし、以下の行をファイル名に合わせて変更して実行します。このツールキットには、業界をリードする C++ コンパイラーをはじめ、多様なアーキテクチャーに対応した高性能なデータ中心型アプリケーション開発に必要なライブラリーが含まれています。
| chmod +x intel-oneapi-base-toolkit-<version>.sh sudo ./intel-oneapi-base-toolkit-<version>.sh |
ステップ 4: インテル® oneAPI に必要な環境変数を初期化し、コンパイラーとライブラリーが開発セッションに合わせて正しく構成されていることを確認します。
注: 新しいセッションごとにこの手順を繰り返す必要があります。
| source /opt/intel/oneapi/setvars.sh |
ステップ 5: llama.cpp リポジトリーのクローンを作成します。
| git clone https://github.com/ggml-org/llama.cpp cd llama.cpp |
ステップ 6: パフォーマンスを最適化するため、インテルのコンパイラーと数学ライブラリーを使用してプロジェクトを設定します。
| cmake -B build -G Ninja -DGGML_BLAS=ON -DGGML_BLAS_VENDOR=Intel10_64lp -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx -DGGML_NATIVE=ON cmake –build build –config Release |
GGUF モデルの準備
Llama.cpp は .gguf 形式のモデルを想定しています。このバイナリーファイル形式には、モデルの重み、トークナイザー、アーキテクチャー、語彙サイズ、および他のメタデータが含まれます。ggml-org/gguf-my-repo ツールを使用してモデルの重みを GGUF 形式に変換/量子化するか、Hugging Face から GGUF ファイルを含むモデルをダウンロードできます。あるいは、以下のように llama.cpp を使用してモデルを変換できます。
ステップ 1: Python 仮想環境を作成してアクティブ化します。
| sudo apt install python3.13-venv -y python3 -m venv env source env/bin/activate |
ステップ 2: llama.cpp ディレクトリーに移動して、次の要件をインストールしてください。
| pip install -r ./requirements/requirements-convert_hf_to_gguf.txt pip install transformers torch sentencepiece |
ステップ 3: Hugging Face からモデルをダウンロードします。
注: モデルが制限されている場合は、Hugging Face モデルカードを通じてモデルの利用規約に同意する必要があります。次に、hf auth login を実行し、Hugging Face の読み取りトークンを入力してから、モデルのダウンロードに進みます。
| hf download <Huggingface_model_name> |
デフォルトでは、ファイルは Hugging Face のローカルキャッシュ (~/.cache/huggingface) にキャッシュされます。–local-dir フラグを使用してこの動作を変更できます。
ステップ 4: GGUF ファイルを整理するため models ディレクトリーを作成し、convert_hf_to_gguf.py Python スクリプトを実行します。
| python3 convert_hf_to_gguf.py <path_to_huggingface_model> –outfile ~/models/<model_name>.gguf |
モデル、タスク、ハードウェアに最適な量子化方法を選択
量子化は、非可逆圧縮と見なすことができます。これは、モデルの重み (場合によっては活性化関数) の精度を下げ、モデルのサイズを縮小することで、推論を高速化する技術です。llama.cpp は、モデルを量子化するツールと、パープレキシティー (ppl) におけるさまざまな量子化の精度損失を測定するツールの両方を提供します。ここでは、llama.cpp を使用してモデルを量子化する方法を示します。利用可能なパラメーターと引数の詳細については、readme ファイルを参照してください。
前のセクションで説明した GGUF モデルを Q8_0 精度に量子化するには、以下を実行します:
| cd ~/llama.cpp/build/bin/ ./llama-quantize ~/models/<model_name>.gguf ~/models/<model_name>-Q8_0.gguf Q8_0 |
–help フラグを使用すると、llama.cpp ビルドでサポートされているすべての量子化の一覧が表示されます。モデルを低精度に量子化すると、モデルのサイズは小さくなり、パープレキシティーが高くなりますが、推論速度の向上を期待できます。しかし、それは事実でしょうか? また、許容できる精度の量子化モデルがいくつかある場合、どのモデルがハードウェアで「最適」に動作するかどのように判断できるでしょう? この疑問は、このセクションと次のセクションで、llama-batched-bench と呼ばれる別の llama.cpp ツールを使用して解明していきます。
実験を始めるにあたり、Llama-3.2-3B-Instruct、gemma-3-4b-it、および Qwen3-8B の 3 つのモデルを、ダウンロードしてそれぞれ精度 F16、BF16、Q8_0、Q4_K_M、Q2_K で量子化します。
llama.cpp のビルド手順 4 で説明したように、セッション内でインテル® oneAPI 環境変数が正しく設定されていることを確認し、次のようにベンチマーク・スクリプトを実行します:
| cd ~/llama.cpp/build/bin ./llama-batched-bench -m ~/models/<model_name>.gguf -c 0 -npp 256 -ntg 256 -npl 1,4,8,16 -t $(nproc) |
これにより、S_PP (プロンプト処理速度、トークン/秒)、S_TG (トークン生成速度、トークン/秒)、および S (合計速度、トークン/秒) を含む測定値の表が生成されます。
パラメーター c はコンテキストのサイズを指定し、引数 0 は「モデルからロード」を意味します。t を nproc に設定すると、すべての CPU スレッドを使用できるようになります。パラメーター npl (並列プロンプト数)、npp (バッチあたりのプロンプト数)、ntg (バッチあたりのトークン数) の値は使用例によって異なります。例えば、テキスト要約では、npp には 1024、ntg には 256 をそれぞれ試してみてください。
以下のグラフは、ハイパースレッディングを使用せずに、48-vCPU マシンで npp と ntg の両方を 256 に設定した場合のベンチマーク結果を示しています。
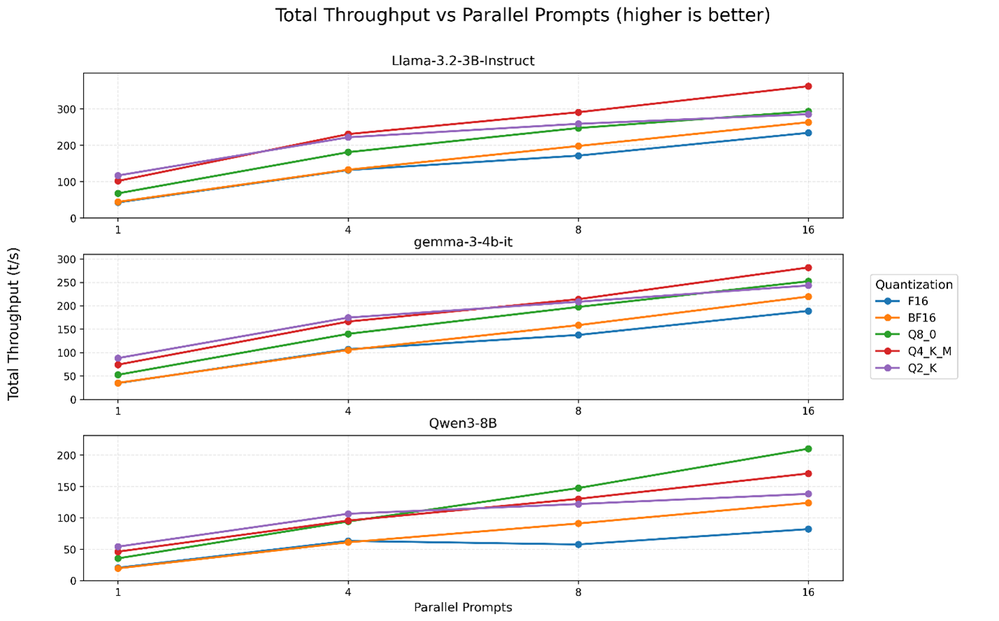
図 1: バッチサイズが小さい (≤4) 場合、F16 と BF16 は同様の性能を示し、Q2_K の方が高速です。バッチサイズが大きい場合、3B/4B モデルでは Q4_K_M が最速で、8B では Q8_0 がピークとなります。
バッチサイズが 4 以下の場合、F16 と BF16 はほぼ同じスループットを示しますが、Q2_K はさらに優れたパフォーマンスを発揮します。バッチサイズが大きい場合、3B および 4B モデルでは Q4_K_M が最大のスループットを実現しますが、8B モデルでは Q8_0 の精度で最大のスループットに達します。
並列プロンプトの数が増えるにつれて、量子化レベル間でパフォーマンスが変化する理由を理解するには、2 つの主要な推論上の制約を考慮すると分かり易くなります: (1) システムがメモリー階層 (DRAM → キャッシュ → コア) を通してモデルの重みをどれだけ速く移動できるか、そして (2) それらの重みが利用可能になった後に CPU がどれだけの演算スループットを維持できるか。
並列度が低い場合、デコード処理はしばしば重みストリーミング型のワークロードと同様の挙動を示します。CPU は DRAM から大きな重み行列を繰り返し取得するため、全体のスループットは生の計算能力ではなく、メモリー・トラフィックとメモリー・レイテンシーによって制限されることがあります。この方式では、より小さな重みフォーマットを使用することで、トークンごとに読み取られるバイト数を減らし、スループットを向上できます。重みを小さな形式 (例えば 2 ビット) に圧縮すると、8 ビットや 16 ビットの重みと比較してメモリー・トラフィックを大幅に削減できます。これらの形式では追加の展開処理やブロックごとのスケーリングが必要になりますが、メモリー移動の削減効果は、低並列度における追加の計算量を上回る可能性があります。FP16 と BF16 では重みごとに 16 ビットを格納するため、ボトルネックが主に 16 ビットの重みの移動である場合、両者はよく似た挙動を示します (ただし、カーネルパスや ISA サポートの違いにより、実際には性能差が生じることがあります)。
並列プロンプトの数を増やすと、同じ行列乗算内の多くのシーケンスで各重み値が再利用されるため、ワークロードの計算負荷が高くなります。これにより、算術演算の負荷が高まり、ボトルネックが「重みの取得」から「行列乗算の実行」へと移行します。そのような計算負荷の高い状況下では、過度な圧縮に伴うオーバーヘッドがより大きな問題となります。量子化されたカーネルは、ドット積 / GEMM パスで 2 ビット / 4 ビットデータを使用するため、低ビット値をアンパックし、ブロックごとのスケール (および関連する管理処理) を適用する必要があります。並列度が高い場合、逆量子化処理はメインの行列乗算と実行リソースが競合し、圧縮 (例えば、Q2_K) の利点を制限したり、逆に利点を損なう可能性があります。対照的に、INT8 スタイルの量子化 (例: Q8_0) は通常、x86 アクセラレーションと上手く適合します。llama.cpp が INT8 に適したパス (利用可能な場合はインテル® AVX-512 ベクトル・ニューラルネットワーク命令 (VNNI) およびインテル® アドバンスト・マトリックス・エクステンション (インテル® AMX) INT8 など) を使用する場合、コアとなるドット積は効率良く実行でき、相対的な「アンパック/スケーリング」のペナルティーは小さくなります。
8B モデルは、生成されるトークンあたり、3B/4B モデルよりも多くの行列乗算処理を行うため、並列処理が増加するにつれて、計算能力がボトルネックとなる領域に早く移行します。そのような状況では、INT8 形式の効率的な実行により、余分な逆量子化がボトルネックとなる 4 ビットや 2 ビット形式の帯域幅節約効果を上回る可能性があります。そのため、8B モデルは高並列度構成では Q8_0 を優先し、低ビット形式は低並列度の構成に優位性があります。
インテル® Xeon® 6 プロセッサーのスケーラブルなメモリー・アーキテクチャー (最大 12 チャネルに対応) は、ボトルネックを生じることなくこれらの量子化をサポートする帯域幅を提供します。これは、より大規模なモデルやバッチサイズにスケールアップする場合は重要です。Google Cloud では標準 DDR5 が使用されますが、オンプレミス環境では MRDIMM をサポートする P コアを搭載するインテル® Xeon® 6 プロセッサーを利用できます。これにより、標準の DDR5 よりも 37% 高いメモリー帯域幅を実現し、大規模な AI および HPC 推論ワークロードをさらに高速化できます。
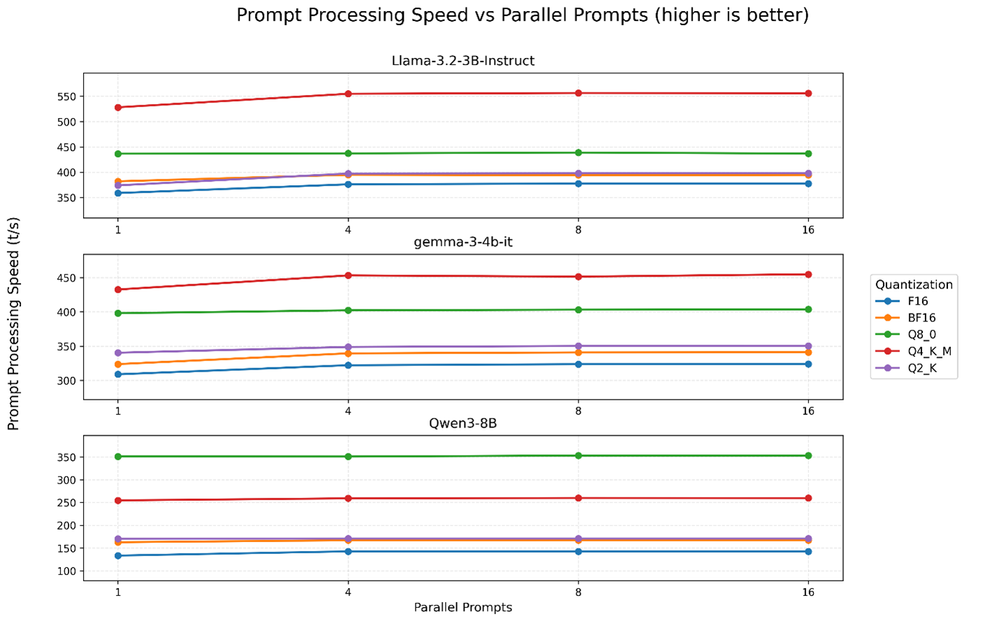
図 2: プロンプト処理速度は、すべてのモデルにおいて、並列プロンプト間でほぼ一定に保たれます。Q4_K_M は、3B / 4B モデルで最高速度を実現します。8B モデルは最もばらつきが大きく、Q8_0 が他の量子化よりも優れた性能を示しています。
推論とは、プロンプト処理 (事前入力) フェーズとトークン生成 (デコード) フェーズのバランスを取ることです。プロンプト処理は、プロンプトシーケンスを取り込んで KV キャッシュを構築する、計算負荷の高いステップであり、構築された KV キャッシュはデコードフェーズで使用されます。トークン生成 (トークンごとに処理を進行) とは異なり、プリフィルは多数のプロンプトトークンを一度に処理し (例えば、256 トークンのプロンプト)、すべてのレイヤーで大規模な行列乗算を実行します。プロンプトが 1 つだけであっても、これらの処理は通常、CPU の計算パイプラインを常に稼働させるのに十分な大きさであるため、並列プロンプトの数を増やしても、プリフィル処理が「プロンプトごとに速くなる」とは限りません。その代わり、並列プロンプトを増やすことで全体のワーク量が増加し、システムの計算リソースとメモリーリソースが飽和状態になると、プリフィル時間の増加やスループット・トレイの発生につながる傾向があります。
プリフィルは計算負荷が高いため、高度に圧縮された形式では、大規模な行列乗算では、追加のアンパック処理やブロックごとのスケーリングのオーバーヘッドが発生する可能性があります。このオーバーヘッドによってプリフィルフェーズが延長され、定常状態のデコードへの移行が遅れ、並列度が高い場合のエンドツーエンドの実効スループットが低下する可能性があります。これは、プロンプト処理と並列プロンプトのグラフで見られる挙動と一致しています。
総スループットは、すべてのトークン数と総処理時間の比率として定義されます。ここでの実験では npp=ntg と設定しているため、これは総スループットがプロンプト処理速度とトークン生成速度の調和平均であることを意味します:
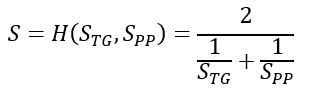
しかし、図 2 に示すように、プロンプト処理速度は並列プロンプト間でほぼ一定であるため、総スループット S は主にトークン生成速度 S_TG の関数となります。S_PP ≫ S_TG の場合、S ≈ 2S_TG となり、これが総スループット曲線の一部の形状 (図 1) がトークン生成曲線 (図 3) と類似している理由です。
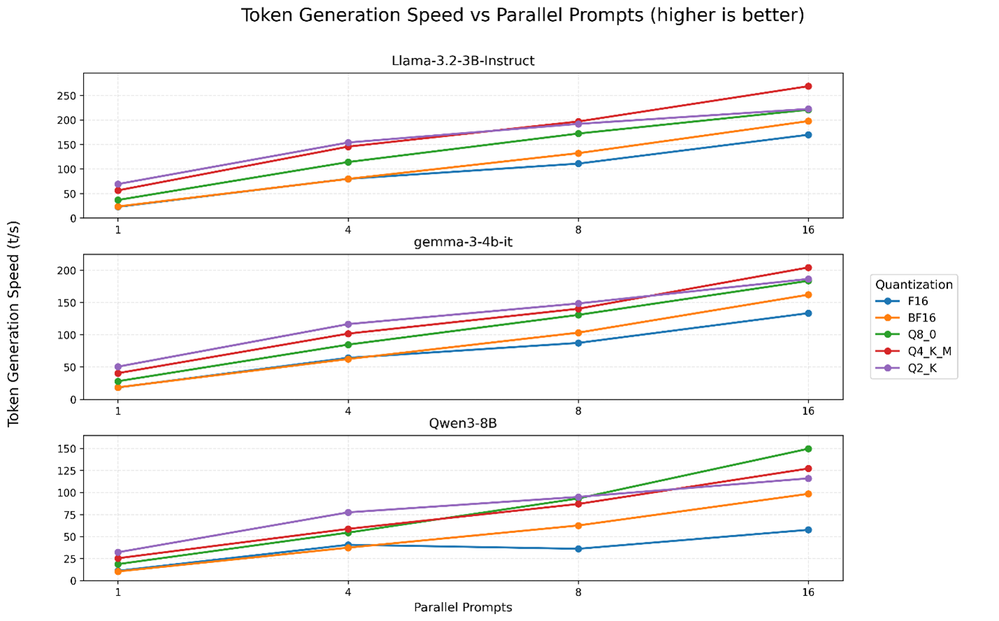
図 3: トークン生成速度は、すべての量子化において、並列プロンプト数の増加に伴って大幅に上昇します。プロンプト処理速度は一定であるため (図2)、トークン生成が総スループットの主要な決定要因となります (図1)。
インテル® Xeon® 6 プロセッサーにおけるインテル® AVX-512 のサポートにより、llama.cpp の SIMD 最適化が可能になります。これは特に量子化推論における行列演算に効果的です。SIMD 演算に上手く適合する Q8_0 および Q4_K_M 量子化が、大規模処理では F16 / BF16 よりも優れたパフォーマンスを発揮することに注目してください。バッチサイズが大きい場合、強力なインテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) およびインテル® アドバンスト・マトリクス・エクステンション (インテル® AMX) アクセラレーターに適切にマッピングされる量子化により、逆量子化による無駄な処理サイクルを回避できます。
スピードアップと並列効率
次に、スピードアップと並列処理の効率性について考えます。スピードアップとは、k 個のスレッドで実行するのにかかる時間を n 個のスレッドで実行するのにかかる時間で割った比率です (n > k)。例えば、2.0 のスピードアップとは、プログラムがベースラインよりも 2 倍速く実行されることを意味します。スレッド数を変化させた場合のスピードアップを調べることで、この実験でのスケーラビリティーが明らかになります。並列効率は、ベースラインと比較してスレッド数が増加することで観測されるスピードアップとして定義されます。バッチサイズを 8 に固定し、Q8_0 モデルと Q4_K_M モデルを使用して、次のコマンドを実行してみます。
| for threads in 4 8 12 16 20 24; do ./llama-batched-bench -m ~/models/<model_name>.gguf -c 0 -npp 256 -ntg 256 -npl 8 -t $threads >> ~/outputs/<file_name>.txt done |
これにより、計算速度の向上と並列効率の基準として 4 つのスレッドを使用することができます。以下に、スループット向上率と並列処理効率の結果を示します。
| モデル | Q8_0 スピードアップ | Q4_K_M スピードアップ |
| Llama-3.2-3B-Instruct | 4.36x (73%) | 4.15x (69%) |
| gemma-3-4b-it | 4.03x (67%) | 3.63% (61%) |
| Qwen3-8B | 3.22x (54%) | 3.65% (61%) |
表 1: 4 スレッドから 24 スレッドへの変更により、全体の処理速度が向上しました。小型モデルは大型モデルよりもスレッド処理との相性が良い傾向があります。

図 4: スレッド数が増加するにつれて、速度向上効果は徐々に小さくなります。これは、速度向上曲線が凹状になっていることからも分かります。
3B モデルの 4 スレッドから 24 スレッドまでの並列効率が 73% であることは、インテル® Xeon® 6 コアが強力なスループットのスケーリングを維持していることを示しており、CPU あたりの SLM 推論回数を増やし、サービス提供コスト効率を向上させます。
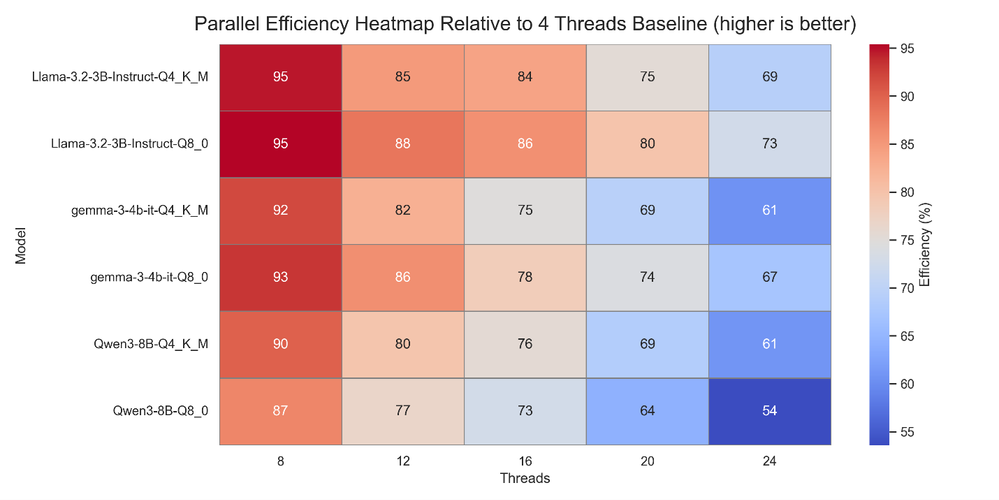
図 5: スループットに関しては、3b/4B モデルは Q8_0 ではより高い効率を維持する一方、8B モデルは Q4_K_M 量子化からさらに大きな恩恵を受けます。
全てのモデルにおいて、トークン生成よりもプロンプト処理の方が並列処理に適しています。トークン生成時の 4.10 倍と比較して、最大 5.13 倍の高速化を実現しており、インテル® Xeon® 6 プロセッサーの P コア・アーキテクチャーと、高度に並列化されたワークロードを維持する能力が際立っています。
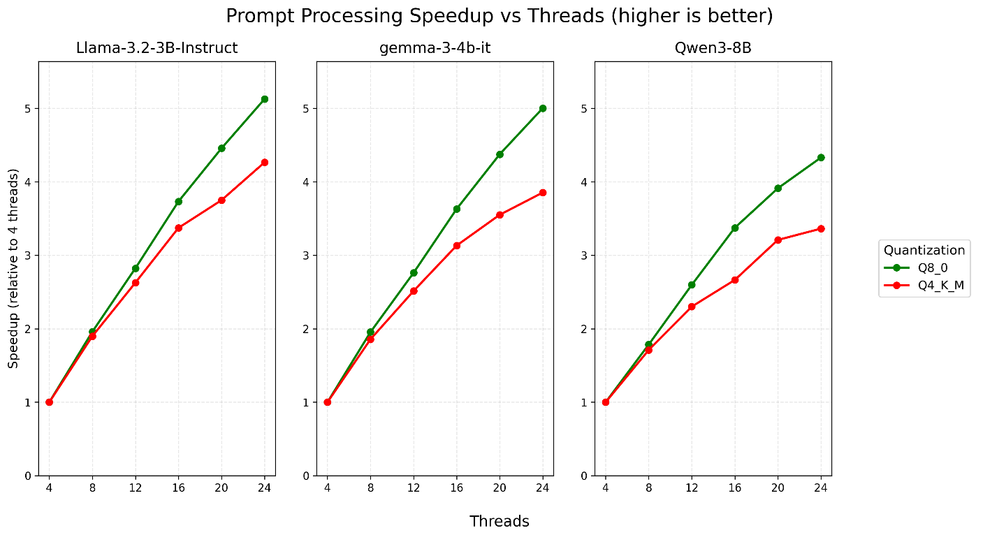
図 6: プロンプト処理のため、3 つのモデル (3B/4B/8B) すべてにおいて、Q4_K_M よりも Q8_0 の方が効率良くスケーリングし、16 スレッドまでほぼ直線的に速度が向上しています。
まとめ
モデルを提供する最適な構成を選択する際には、スループットとスレッドスケーリングの両方を考慮することが重要です。最適な設定は利用する環境によって異なります。コア数の少ない環境では、生のスループットを最大化する量子化を使用し、スレッド数の多い環境では、並列処理効率の高い量子化を使用してください。これらのメトリックのバランスを取ることで、CPU あたりの実効スループットが最大化され、推論あたりのコストが削減されます。
Llama.cpp を使用して SLM 搭載エージェントにサービスを提供
タスクに最適な SLM とスレッド数を決定する方法について説明したので、次に llama.cpp と OpenAI Agents SDK を使用して、簡単なエージェントをローカルで実行する方法を見ていきましょう。
ステップ 1: llama.cpp サーバーを開始します。
| ./llama-server -m ~/models/<model_name>.gguf -t 12 –port 8080 |
ステップ 2: 新しいターミナルを開き、OpenAI Agents ライブラリーをインストールします。
| pip install openai-agents |
ステップ 3: 以下の Python コードを demo.py として保存し、python3 demo.py で実行します。
| from agents import Agent, Runner, OpenAIChatCompletionsModel from openai import AsyncOpenAI client = AsyncOpenAI(base_url=”http://localhost:8080/v1“, api_key=”any string”) local_model = OpenAIChatCompletionsModel(model=”SLM”, openai_client=client) agent = Agent(name=”Assistant”, instructions=”You are a helpful assistant”, model=local_model) result = Runner.run_sync(agent, “Write a haiku about recursion in programming.”) print(result.final_output) |
以下のような出力が得られるはずです:
Code calls itself on,
A mirrored, nested dance flows,
Logic finds its way.
まとめ
インテル® Xeon® 6 プロセッサーは、インテル® AVX-512 とインテル® AMX アクセラレーション、スケーラブルなスレッド処理、そしてメモリー帯域幅を組み合わせることで、GPU を使用することなく応答性の高い AI エクスペリエンスを実現し、SLM (ソフトウェア・ライフサイクル管理) の導入に最適な基盤を提供します。ベンチマークテストの結果が示すように、モデルサイズ、量子化、スレッド数を慎重に選択することで、CPU 単体でも高いスループットを達成できます。
インテル® Xeon® 6 プロセッサーが AI パフォーマンスをどのように変革できるかご覧ください。
謝辞
初期草稿に有益な議論とフィードバックを提供してくれた Benjamin Odom、Abirami Prabhakaran、および Sheik Mohamed Imran に感謝します。
(1) 設定: 1-instance c4-highmem-48-lssd: インテル® Xeon® 6985P-C 48 vCPU、(HT オフ、合計 372 GB メモリー、Google Compute Engine Virtual、Debian 13, 6.12.57-1-cloud-amd64 (x86_64)、llama.cpp リリース b7054、インテル® oneAPI ベース・ツールキット・バージョン 2025.3.0.375。2025 年 11 月インテルによる検証。
法務上の注意書き
性能は、使用状況、構成、その他の要因によって異なります。詳細については、パフォーマンス・インデックス・サイトを参照してください。
性能の測定結果はシステム構成の日付時点のテストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。詳細については参考資料を参照してください。絶対的なセキュリティーを提供できるコンピューター・システムはありません。
コスト対効果は異なる場合があります。
インテルのテクノロジーを使用するには、対応したハードウェア、ソフトウェア、またはサービスの有効化が必要となる場合があります。
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
