

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「3D Vector Normalization Using 256-Bit Intel® Advanced Vector Extensions (Intel® AVX)」(http://software.intel.com/en-us/articles/3d-vector-normalization-using-256-bit-intel-advanced-vector-extensions-intel-avx/) の日本語参考訳です。
目標
8 要素幅の SIMD 処理により、パックド 3D データを一度に転置して幾何学計算のパフォーマンスを向上させる方法を紹介します。
抄録
この記事は、256 ビットのインテル® アドバンスド・ベクトル・エクステンション (インテル® AVX) を利用して 3D ベクトルの配列を正規化する方法を説明したものです。ここでは、8 要素幅までの SIMD 処理でデータを AOS と SOA 間で一度に変換するシャッフルアプローチを紹介します。8×3 から 3×8 への転置は 5 シャッフルで実行でき、3×8 から 8×3 に戻すには 6 シャッフルかかります。正規化計算においてワイドな SIMD を使用することで、128 ビットで 2.3 倍、256 ビットで 2.9 倍の高速化が達成できました。SOA 処理を行うためのラウンドトリップのコストは 11 命令と非常に少なく、計算への影響はほとんどありませんでした。
はじめに
多くのインタラクティブなアプリケーションは、CPU 上でいくつかの形式で非常に多くの幾何学処理を行います。この処理には SOA (structure of array) メモリー形式が最も効率的ですが、一部のアプリケーションではこの形式でデータを格納することは現実的ではありません。3D アプリケーションで一般的なデータ構造である、3D ベクトルの規則的配列を処理するコードは、パフォーマンスに大きな影響を与えることが知られています。
一般的な例として、3D 法線ベクトルの配列をすべて単位ベクトルで表す例があります。この記事では、この例から始めて、第 2 世代インテル® Core™ プロセッサー・ファミリー (開発コード名 Sandy Bridge) の新しいマイクロアーキテクチャーの一部であるインテル® アドバンスド・ベクトル・エクステンション (インテル® AVX) の新しい 256 ビット命令を含む、x86 プロセッサーの機能を活用するようにコードを最適化します。
最適化するループの C コードを次に示します。
void Normalize(float V[][3],int N)
{
for(int i=0;i != N;i++)
{
float *v=V[i];
float invmag = 1.0f/sqrtf(v[0]*v[0]+v[1]*v[1]+v[2]*v[2]);
v[0] *= invmag;
v[1] *= invmag;
v[2] *= invmag;
}
}
実際には、これらのルーチンは C++ 3D ベクトルクラスと多重定義した演算子を使用して実装されますが、根本的な処理とデータ形式は同じです。
4 要素の 32 ビット単精度浮動小数点による SIMD 処理は、2001 年にインテル® ストリーミング SIMD 拡張命令 2 (SSE2) が登場してから広く利用されるようになりました。128 ビットのレジスター幅は 4D データに適しているため、多くの 3D インタラクティブ・アプリケーションはホモジニアス・ベクトルを使用するか、追加で 32 ビットをパディングした 3D ベクトルを使用します。単純に SIMD 処理を利用する方法では、ほかのパフォーマンス・ボトルネックにより、性能が 4 倍になることはまずありません。この形式の SIMD を正規化の例に適用した場合、128 ビット・レジスターの 4 要素のうち 3 つしか使用しません。乗算は並列に実行できますが、二乗の合計や平方根の逆数の計算で SIMD を利用するメリットはありません。
最も重要な点は、このプログラミング・パターンは 8 つの浮動小数点の並列演算をサポートしている 256 ビットのインテル® アドバンスド・ベクトル・エクステンション (インテル® AVX) のような、よりワイドな SIMD にスケールアップできないことです。
SIMD を利用する別のアプローチとして、一度にループの 8 つの反復を処理する、つまり一度に 8 つのベクトルを正規化する方法があります。この方法では、8 つのベクトルすべての X、Y、Z コンポーネントを順にレジスターに収まるようにデータを再配置する必要があります。この方法でデータが SOA (structure of arrays) で格納されていれば、レジスターは容易にロードできます。しかし、一部のアプリケーションではデータの格納領域がパックドシーケンスである AOS (array of structures) になっています。このため、8 要素幅の SIMD 処理を行うには、データを一度に転置し、計算を行い、データを元に戻す必要があります。
この記事では、x86 でシャッフルを使用してデータを変換する方法とその結果を紹介します。また、最適化されたシリアル実装とシャッフル転置の実装についても紹介します。この結果では、3D ベクトルの AOS 配列の正規化にインテル® AVX を使用した場合のスピードアップが分かります。
128 ビットと 256 ビットの AOS から SOA へのシャッフル
1 次キャッシュからレジスターにデータを移動する最も効率的な方法は、一度に 128 ビット (またはそれ以上) をロードすることです。このストライドは 3D のパックド配列とは異なります。しかし、128 ビット・アライメントのパターンは 4 つ目のベクトル (または 12 float) ごとに繰り返されます。このため、3 つのアラインされた 128 ビットのロードにより、次の 4 つの 3D ベクトルが 3 つの 128 ビット・レジスターに格納されます。
ベクトル要素の順序は 3 つのロード直後はあまり役立ちません。次に、X、Y、Z を個別のレジスターにグループ化して、4 つの 3D ベクトルのデータを利用可能な形式にする必要があります。次の図は、5 つのインテル® AVX の 128 ビット・シャッフルを使用した 4×3 から 3×4 への転置を示しています。
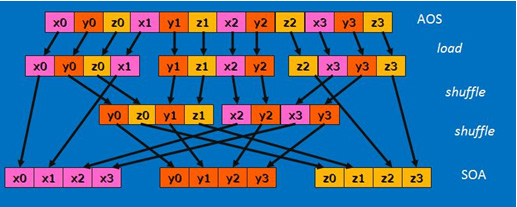
データが SOA 形式になり、計算はシリアル実装と同じステップで完了しますが、ここでは一度に 4 つのベクトルを正規化するインテル® AVX 命令を使用しています。
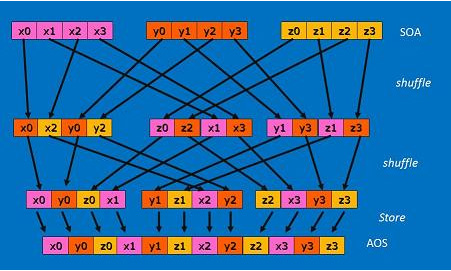
計算結果は SOA 形式なので、AOS 形式に戻す必要があります。この転置処理は可換ではありません。つまり、SOA から AOS に同じコードで戻すことはできません。実際、元に戻すには 1 シャッフル余分にかかります。使用した方法は次の図を参照してください。
これまで、4 float または 128 ビット SIMD について説明しましたが、256 ビット・レジスターとインテル® AVX 命令を使用することで 8×3 まで処理を拡張できます。シャッフル時、256 ビットのインテル® AVX には 128 ビットのレーンが 2 つあることに注目します。つまり、インテル® AVX では 2 レーンの 4 要素 SIMD ユニットを利用できるということです。
前の例のように、最初に 12 float を 3 つの 128 ビット・レジスター (実際には 3 つの 256 ビット・レジスターの下半分) にロードします。そして、次の 12 float (または次の 4 つの 3D ベクトル) を同じ 3 つの 256 ビット・レジスターの上半分にロードします。次に、256 ビット・バージョンの命令/組み込み関数を使用して、全く同じ方法でシャッフル計算を実装します。
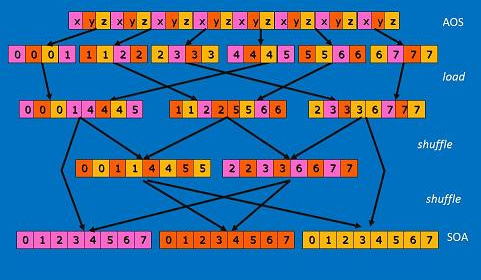
256 ビットでの AOS への変換 (6 シャッフル) と格納も同様に上記の 128 ビット・バージョンの拡張です。データを SOA に転置して戻す方法を使用して、3D ベクトルの配列を正規化します。
テストと結果
テストでは、インテル® AVX 対応のマイクロアーキテクチャー (開発コード名 Sandy Bridge) を搭載したインテル® プロセッサー・ベースのシステムの 1 つのコアを使用しました。命令コストに注目するため、L1 キャッシュには 1024 の 3D ベクトルのデータが格納されました。データセット全体を処理する総サイクル数を測定するため、RDTSC 命令がループの前後で呼び出されました。下記の表は、128 ビットと 256 ビットでデータを処理したときのスループットを、処理されたベクトルあたりの CPU サイクル数で示しています。さまざまな正規化の実装に加えて、個々のステップのコストを測定する部分を削除してループを測定しています。
以下の表は、SIMD 128 ビット (4 float) と 256 ビット (8 float) で 3D データを AOS から SOA、および SOA から AOS に変換した場合のラウンドトリップの 3D ベクトルあたりのコストを示しています。
| 転置のみのラウンドトリップ | 処理されたベクトルあたりのサイクル数 | 説明 |
| shuf_trans128: | 3.0 | 128 ビット AOS->SOA->AOS (シャッフル使用) |
| shuf_trans256: | 1.5 | 256 ビットで転置して元に戻した場合 |
表の値は 3D ベクトルあたりのサイクル数です。ループ反復ごとに転置されているベクトルが 1 つ以上あることに注意してください。どちらの場合も、ループごとに 11 シャッフルが行われるため、ループ反復は 12 サイクルかかります。パックド AOS から SOA、および逆のラウンドトリップ変換を行った場合のベクトルあたりのコストは 3 サイクル以下でした。
次のテストでは、転置が必要ない場合のコストを測定するために、データが SOA 形式になっている (つまり、X、Y、Z がそれぞれ 3 つの別の配列になっている) 別のデータ構造を使用します。以下の表は、SOA 形式になっている 3D ベクトルを正規化するコストを示しています。
| SIMD 計算のみのテスト | 正規化されたベクトルあたりのサイクル数 | 説明 |
| norm_soa_data4: | 1.8 | 128 ビット組み込み関数を SOA データに使用 |
| norm_soa_data8: | 1.1 | 256 ビット組み込み関数を SOA データに使用 |
結果は、あらかじめ SOA 形式になっているデータに 128 ビットと 256 ビットの SIMD 正規化を実装したときのコストを示したものです。データをシャッフルするコストがかかっていないため、この結果だけを見て AOS データの正規化にかかる時間が短いと考えるのは禁物です。これは参考のために示した値で、ループの数値計算部分の絶対的なパフォーマンスの限界を示しているものです。
正規化では精度の低い数を使用していることに注意してください。平方根の逆数の近似値を求めるアセンブリー・ルーチンの結果にはニュートン・ラフソン法が使用されていません。照明計算のメッシュ法線生成のような一部のアプリケーションでは精度が低くても十分であると考えられます。この一連のテストの目的は、非常に小さな計算で転置を一度に行う方法の潜在的な利点を評価することです。
以下の表は、3D ベクトルの規則的配列 (AOS データセット) を正規化するコストを示しています。
| 3D ベクトルの正規化 | 正規化されたベクトルあたりのサイクル数 | 説明 |
| x87: | 45.0 | シリアル関数 (インテル® SSE およびインテル® AVX なし) |
| arch_optim: | 24.3 | シリアル正規化 (SIMD なし、-arch 最適化を使用) |
| rsqrt_ss: | 8.0 | シリアルベクトル正規化 (RSQRT アセンブリーを使用) |
| mask_trans: | 9.4 | AOS->SOA->AOS (4×3 転置のマスキングを使用) |
| shuf_trans4: | 3.5 | 4 float (128 ビット) SOA AOS 変換 (シャッフルを使用) |
| shuf_trans8: | 2.7 | 8 float (256 ビット) 8×3 転置 (シャッフルを使用) |
結果は、さまざまな実装を示したものです。公正な比較を行うために、アセンブリー命令を使用して、より低い精度で、ループあたり平均 8 サイクルまたはベクトル正規化あたり平均 8 サイクルの、最適化されているシリアル実装を記述しました。さらに、マスクとビット単位の論理演算を使用して転置を行う、別の 128 ビット AOS->SOA->AOS プログラミング・パターンとも比較しました。現在のハードウェアでは、この方法はシリアル実装よりも遅くなります。
インテル® AVX の 256 ビット SIMD を使用すると、3D ベクトルの規則的配列は 2.7 サイクルで正規化されます。つまり、シャッフルを使用した SIMD 実装は最適なシリアル実装よりも優れていることになります。このコストは以前の 2 つの表の計算とシャッフルを合計したものではないことに注意してください。インテルの x86 CPU には、シャッフル、乗算、加算、移動を処理するための独立した実行ポートがあります。全体的に見て、SOA をシャッフルベースで転置する方法を実装することで、かなりのスピードアップが達成できます。
| SIMD 実装 | 最適なシリアル実装 | 128 ビット | 256 ビット |
| スピードアップ | 1 (基準) | 2.3 | 2.9 |
まとめ
利用可能なアーキテクチャー/命令を使用するコンパイラー・オプションの設定、実装内でより高速な命令への変更、SIMD の利用など、シンプルな C/C++ 実装のコードのパフォーマンスを向上させるために開発者が利用できる方法は数多くあります。チューニングされていないリリースモードでのコンパイルから、インテル® AVX の 256 ビット・バージョンを使用する方法では、パフォーマンスが 1 桁以上向上しています。
すでに SOA 形式になっているデータ構造を処理する方法は確かに最も効率的ですが、この方法が多くのアプリケーションで常に利用できるとは限りません。SOA と AOS 間で 3D データを一度にシャッフルする方法は、インテル® プロセッサーをより効率的に利用して 3D アプリケーションを高速化するために、試す価値のある方法です。この例におけるベクトルあたりの計算量は非常に少ないものです。最内ループでより多くの計算を行う必要がある場合、この方法を利用することで大幅なスピードアップを達成できるでしょう。
著者紹介
Stan Melax は、90 年代の初めに University of Alberta でコンピューター・サイエンスの学士号と修士号を取得しています。これまで、BioWare、EA、Ageia を含むゲーム業界に長く従事してきました。現在は、インテルのグラフィックス・ソフトウェア・エンジニアとして、開発者がより高速なコードを記述し、より優れたアプリケーションを作成できるように支援しています。
付録: 転置ソースコード
AOS から SOA (128 ビット)
AOS から SOA への変換に 128 ビットのインテル® アドバンスド・ベクトル・エクステンション (インテル® AVX) 組み込み関数を使用した C ソースコード:
float *p; // 最初のベクトルのアドレス __m128 x0y0z0x1 = _mm_load_ps(p+0); __m128 y1z1x2y2 = _mm_load_ps(p+4); __m128 z2x3y3z3 = _mm_load_ps(p+8); __m128 x2y2x3y3 = _mm_shuffle_ps(y1z1x2y2,z2x3y3z3,_MM_SHUFFLE( 2,1,3,2)); __m128 y0z0y1z1 = _mm_shuffle_ps(x0y0z0x1,y1z1x2y2,_MM_SHUFFLE( 1,0,2,1)); __m128 x = _mm_shuffle_ps(x0y0z0x1,x2y2x3y3,_MM_SHUFFLE( 2,0,3,0)); // x0x1x2x3 __m128 y = _mm_shuffle_ps(y0z0y1z1,x2y2x3y3,_MM_SHUFFLE( 3,1,2,0)); // y0y1y2y3 __m128 z = _mm_shuffle_ps(y0z0y1z1,z2x3y3z3,_MM_SHUFFLE( 3,0,3,1)); // z0z1z2z3
出力は __m128 レジスター x、y、z に格納されます。
SOA から AOS (128 ビット)
SOA から AOS の変換に 128 ビットのインテル® アドバンスド・ベクトル・エクステンション (インテル® AVX) 組み込み関数を使用した C ソースコード:
__m128 x,y,z; // SOA データの開始 __m128 x0x2y0y2 = _mm_shuffle_ps(x,y, _MM_SHUFFLE(2,0,2,0)); __m128 y1y3z1z3 = _mm_shuffle_ps(y,z, _MM_SHUFFLE(3,1,3,1)); __m128 z0z2x1x3 = _mm_shuffle_ps(z,x, _MM_SHUFFLE(3,1,2,0)); __m128 rx0y0z0x1= _mm_shuffle_ps(x0x2y0y2,z0z2x1x3, _MM_SHUFFLE(2,0,2,0)); __m128 ry1z1x2y2= _mm_shuffle_ps(y1y3z1z3,x0x2y0y2, _MM_SHUFFLE(3,1,2,0)); __m128 rz2x3y3z3= _mm_shuffle_ps(z0z2x1x3,y1y3z1z3, _MM_SHUFFLE(3,1,3,1)); _mm_store_ps(p+0, rx0y0z0x1 ); _mm_store_ps(p+4, ry1z1x2y2 ); _mm_store_ps(p+8, rz2x3y3z3 );
4 つのベクトルのデータを含むレジスター x、y、z はシャッフルされ、ポインター p から開始するパックド配列に格納されます。
AOS から SOA (256 ビット)
AOS から SOA の変換に 256 ビットのインテル® アドバンスド・ベクトル・エクステンション (インテル® AVX) 組み込み関数を使用した C ソースコード:
float *p; // 最初のベクトルのアドレス __m128 *m = (__m128*) p; __m256 m03; __m256 m14; __m256 m25; m03 = _mm256_castps128_ps256(m[0]); // 下半分のロード m14 = _mm256_castps128_ps256(m[1]); m25 = _mm256_castps128_ps256(m[2]); m03 = _mm256_insertf128_ps(m03 ,m[3],1); // 上半分のロード m14 = _mm256_insertf128_ps(m14 ,m[4],1); m25 = _mm256_insertf128_ps(m25 ,m[5],1); __m256 xy = _mm256_shuffle_ps(m14, m25, _MM_SHUFFLE( 2,1,3,2)); // x と y の上部分 __m256 yz = _mm256_shuffle_ps(m03, m14, _MM_SHUFFLE( 1,0,2,1)); // y と z の下部分 __m256 x = _mm256_shuffle_ps(m03, xy , _MM_SHUFFLE( 2,0,3,0)); __m256 y = _mm256_shuffle_ps(yz , xy , _MM_SHUFFLE( 3,1,2,0)); __m256 z = _mm256_shuffle_ps(yz , m25, _MM_SHUFFLE( 3,0,3,1));
8 つの 3D ベクトルがアドレス p からロードされます。出力は __m256 レジスター x、y、z に格納されます。変に見えるかもしれませんが、これは 128 ビット・バージョンの自然な拡張です。
SOA から AOS (256 ビット)
SOA から AOS の変換に 256 ビットのインテル® アドバンスド・ベクトル・エクステンション (インテル® AVX) 組み込み関数を使用した C ソースコード:
__m256 x,y,z; // SOA データの開始 float *p; // 出力ポインター __m128 *m = (__m128*) p; __m256 rxy = _mm256_shuffle_ps(x,y, _MM_SHUFFLE(2,0,2,0)); __m256 ryz = _mm256_shuffle_ps(y,z, _MM_SHUFFLE(3,1,3,1)); __m256 rzx = _mm256_shuffle_ps(z,x, _MM_SHUFFLE(3,1,2,0)); __m256 r03 = _mm256_shuffle_ps(rxy, rzx, _MM_SHUFFLE(2,0,2,0)); __m256 r14 = _mm256_shuffle_ps(ryz, rxy, _MM_SHUFFLE(3,1,2,0)); __m256 r25 = _mm256_shuffle_ps(rzx, ryz, _MM_SHUFFLE(3,1,3,1)); m[0] = _mm256_castps256_ps128( r03 ); m[1] = _mm256_castps256_ps128( r14 ); m[2] = _mm256_castps256_ps128( r25 ); m[3] = _mm256_extractf128_ps( r03 ,1); m[4] = _mm256_extractf128_ps( r14 ,1); m[5] = _mm256_extractf128_ps( r25 ,1);
8 つの 3D ベクトルのデータを含むレジスター x、y、z はシャッフルされ、ポインター p から開始するパックド配列に格納されます。
インテル® ソフトウェア製品のパフォーマンス/最適化に関する詳細は、最適化に関する注意事項 (英語) を参照してください。
編集部追加
本記事で紹介したようなスピードアップの確認、またはチューニングすべき箇所の特定は、ツールを用いて正しく行うべきです。誤ったパフォーマンスの理解は、開発期間を浪費し、無駄なコストを投じることになるでしょう。インテル社が提供するパフォーマンス解析ツールである、インテル® VTune Amplifier XE を是非とも1度お試しいただければと思います。評価版のダウンロード、お問い合わせはエクセルソフト株式会社まで。
