
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Scheduling Overhead in Intel® Threading Building Blocks (Intel® TBB) Apps」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、インテル® スレッディング・ビルディング・ブロック (インテル® TBB) アプリケーションのスケジュール・オーバーヘッドを検出して修正する方法を説明します。
コンテンツ・エキスパート: Dmitry Prohorov (英語)
スケジュール・オーバーヘッドは、細粒度の作業チャンクをスレッド間で動的に分散する場合に発生する典型的な問題です。スケジュール・オーバーヘッドが発生している場合、ワーカースレッドに作業を割り当てるためスケジューラーが費やす時間と、ワーカースレッドが新しい作業の待機に費やす時間が長くなると、並列処理の効率が低下し、極端なケースでは、プログラムのスレッド化したバージョンのほうがシーケンシャル・バージョンよりも遅くなります。ほとんどのインテル® TBB 構文は、オーバーヘッドを回避するためチャンク数をデフォルトの粒度よりも大きくする、デフォルトの自動パーティショナーを使用します。意図的にまたは parallel_deterministic_reduce などの構文を使用して単純なパーティショナーを使用する場合、単純なパーティショナーは最大で 1 反復のデフォルトの粒度と等しいチャンクサイズに作業を分割するため、粒度を調整する必要があります。インテル® VTune™ Amplifier は、インテル® TBB アプリケーションのスケジュール・オーバーヘッドの検出を支援し、粒度を大きくしてオーバーヘッドによる速度低下を回避するためのアドバイスを提供します。
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: インテル® TBB の parallel_deterministic_reduce テンプレート関数を使用してベクトル要素の合計を計算するサンプル・アプリケーション
- コンパイラー: インテル® コンパイラーまたは GNU* コンパイラー。次のコンパイラー/リンカーオプションを指定します。
-I <tbb_install_dir>/include -g -O2 -std=c++11 -o vector-reduce vector-reduce.cpp -L <tbb_install_dir>/lib/intel64/gcc4.7 -ltbb
- パフォーマンス解析ツール: インテル® VTune™ Amplifier 2019: スレッド解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- オペレーティング・システム: Ubuntu* 16.04 LTS
- CPU: インテル® Xeon® プロセッサー E5-2699 v4 @ 2.20GHz
ベースラインを作成する
サンプルコードの初期バージョンは、デフォルトの粒度で parallel_deterministic_reduce を使用します (行 17-23)。
#include <stdlib.h>
#include "tbb/tbb.h"
static const size_t SIZE = 50*1000*1000;
double v[SIZE];
using namespace tbb;
void VectorInit( double *v, size_t n )
{
parallel_for( size_t( 0 ), n, size_t( 1 ), [=](size_t i){ v[i] = i * 2; } );
}
double VectorReduction( double *v, size_t n )
{
return parallel_deterministic_reduce(
blocked_range<double*>( v, v + n ),
0.f,
[](const blocked_range<double*>& r, double value)->double {
return std::accumulate(r.begin(), r.end(), value);
},
std::plus<double>()
);
}
int main(int argc, char *argv[])
{
task_scheduler_init( task_scheduler_init::automatic );
VectorInit( v, SIZE );
double sum;
for (int i=0; i<100; i++)
sum = VectorReduction( v, SIZE );
return 0;
}
統計解析向けに大きく測定可能な計算処理にするため、行 35 のループでベクトル合計計算を繰り返しています。
コンパイルしたアプリケーションの実行には約 9 秒かかりました。これが、以降の最適化で使用するパフォーマンスのベースラインとなります。
スレッド解析を実行する
アプリケーションのスレッド並列性とスケジュール・オーバーヘッドに費やされた時間を予測するには、並行性解析を実行します。
- ツールバーの
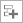 [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: vector-reduce) を指定します。
[New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: vector-reduce) を指定します。
- [Create Project (プロジェクトの作成)] をクリックします。
[Configure Analysis (解析の設定)] ウィンドウが表示されます。
- [WHERE (どこを)] ペインで、[Local Host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [WHAT (何を)] ペインで、[Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、解析するアプリケーションを指定します。
- [HOW (どのように)] ペインで、[…] ボタンをクリックして [Parallelism (並列性)] > [Threading (スレッド化)] を選択します。
 [Start (開始)] ボタンをクリックします。
[Start (開始)] ボタンをクリックします。
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
注
スレッド解析はインストルメンテーション・ベースでスタックのスティッチを使用するため、収集オーバーヘッドにより、インストルメントされたアプリケーションの経過時間はオリジナルのアプリケーションの実行よりも長くなります。
スケジュール・オーバーヘッドを特定する
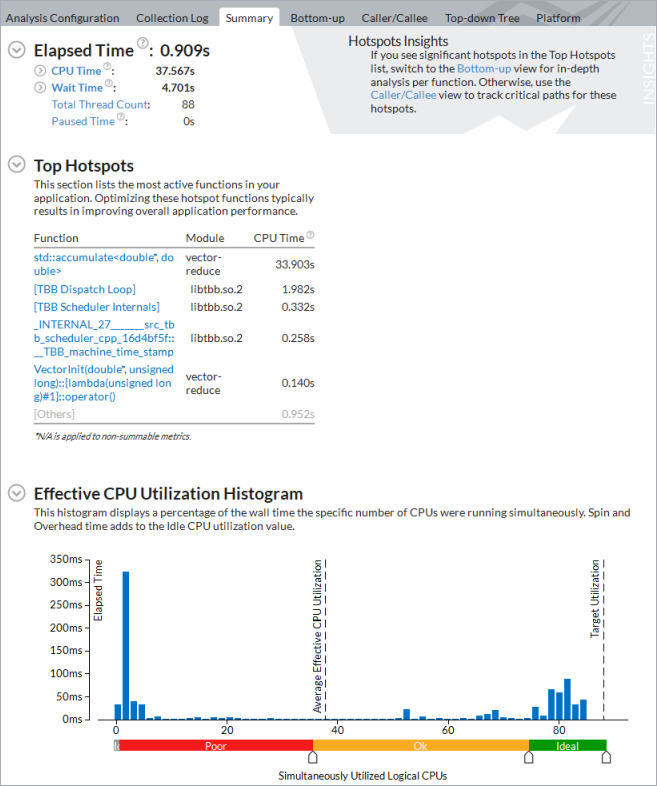
アプリケーション・レベルの統計が表示される [Summary (サマリー)] ビューから解析を始めます。
[Effective CPU Utilization Histogram (効率良い CPU 利用率の分布図)] は、アプリケーションが利用可能な 88 コアのうち平均で約 3 コアしか使用していないことを示しています。
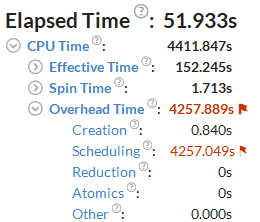
フラグが付いた [Overhead Time (オーバーヘッド時間)] メトリックと [Scheduling (スケジューリング)]) サブメトリックは、調査すべき非効率的なスレッド化の問題を示しています。
[Top Hotspots (上位 hotspot)] セクションから [TBB Dispatch Loop] が最も時間を費やしている関数であることが分ります。関数に関連するフラグのヒントは、並列処理の粒度を大きくして対応すべきスケジュール・オーバーヘッドに関する情報を示しています。
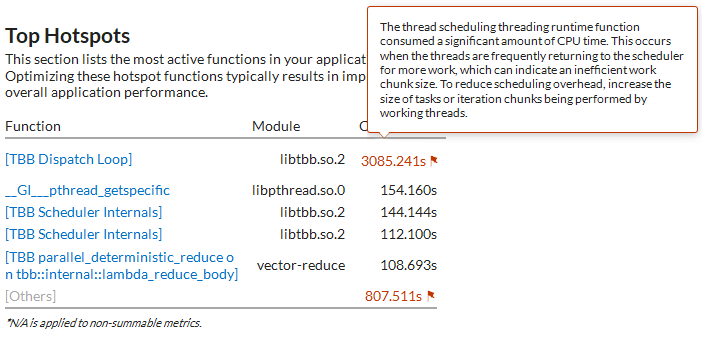
サンプル・アプリケーションには、ベクトル要素の合計を計算する 2 つのインテル® TBB 構文 parallel_for の初期化と parallel_deterministic_reduce が含まれています。[Caller/Callee (呼び出し元/呼び出し先)] データビューを使用して、どちらのインテル® TBB 構文でオーバーヘッドが発生しているか確認します。[CPU Time: Total (CPU 時間: 合計)] > [Overhead Time (オーバーヘッド時間)] カラムを展開して、[Scheduling (スケジューリング)] カラムでグリッドをソートします。[Function (関数)] リストでインテル® TBB の並列構文を含む最初の行を見つけます。

この行は、スケジュール・オーバーヘッドが最も大きい VectorReduction 関数の parallel_deterministic_reduce 構文をポイントしています。この構文の並列処理でオーバーヘッドを排除できるように、作業チャンクをより粗粒度にします。
注
アプリケーションの実行中にインバランスを視覚化するには、[Timeline (タイムライン)] ビューを使用します。有効な作業を実行している時間は緑色で示され、浪費時間は黒色で示されます。
並列処理の粒度を大きくする
前述のとおり、ワーカースレッドに細粒度の作業チャンクを割り当てると、スケジューラーが作業割り当てに費やす時間を相殺できません。単純なパーティショナーを使用する parallel_deterministic_reduce のデフォルトのチャンクサイズは 1 です。つまり、ワーカースレッドは 1 ループ反復を実行しただけで、スケジューラーに新しい作業を要求します。次のコードのように、最小チャンクサイズを 10,000 に増やします (行5)。
double VectorReduction( double *v, size_t n )
{
return parallel_deterministic_reduce(
blocked_range<double*>( v, v + n, 10000 ),
0.f,
[](const blocked_range<double*>& r, double value)->double {
return std::accumulate(r.begin(), r.end(), value);
},
std::plus<double>()
);
}
そして、スレッド解析を再度実行します。
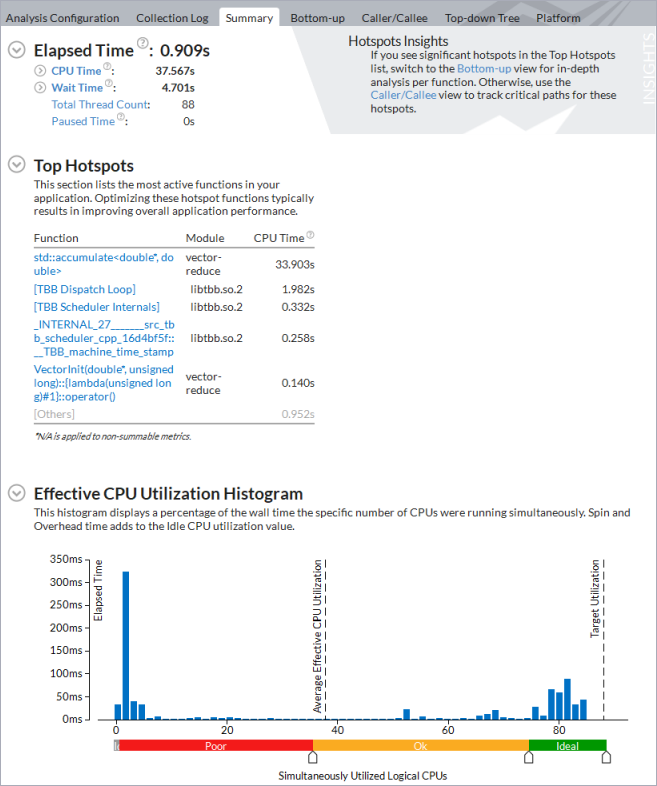
アプリケーションの経過時間が大幅に減り、効果的な CPU 使用率の平均は約 38 論理コアになります (このメトリックにはウォームアップ・フェーズが含まれるため、計算フェーズの CPU 使用率は 80 コア近くに上ります)。インテル® TBB のスケジューリングやその他の並列処理関連の作業に費やされた CPU 時間はわずかです。このわずかなコード変更によって、アプリケーション全体では (収集時間を除いて) オリジナルバージョンと比較して 10 倍のスピードアップを達成しました。
注
このレシピの情報は、デベロッパー・フォーラムを参照してください。
関連情報
- スレッド解析 (英語)
