
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Profiling AI Applications」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
インテル® VTune™ プロファイラーを使用して、人工知能 (AI) および機械学習 (ML) のワークロードをプロファイルする方法を学びます。
このレシピでは、インテル® VTune™ プロファイラーを使用して、単純なニューラル ネットワークの実装である Python* コードのサンプルをプロファイルする方法を説明します。このレシピでは、クラウドからエッジまでディープラーニング・モデルを最適化して展開するオープンソース・ツールキットである OpenVINO™ ツールキットも利用します。OpenVINO ツールキットは、生成 AI、ビデオ、オーディオ、言語などのユースケース全体でディープラーニング推論を加速します。このツールキットは、PyTorch*、TensorFlow*、Open Neural Network Exchange (ONNX) などの一般的なフレームワーク・モデルを使用します。
コンテンツ・エキスパート: Rupak Roy、Lalith Sharan Bandaru
- 使用するもの
- 手順:
使用するもの
以下は、このパフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
アプリケーション: このレシピでは、 TensorFlow_HelloWorld.py (英語) および Intel_Extension_For_PyTorch_Hello_World.py (英語) アプリケーションを使用します。これらのサンプルコードは両方とも、以下を使用した単純なニューラル・ネットワークの実装です。
- 畳み込みレイヤー
- 正規化レイヤー
- トレーニングと評価が可能な ReLU レイヤー
このレシピでは、OpenVINO™ (英語) の MobileNet v2 (英語) モデルを使用した画像分類の例も使用します。
解析ツール: インテル® VTune™ プロファイラー (バージョン 2025.0 以降) を使用したユーザー モードのサンプリングとトレース収集
Python パッケージ: インテル® ディストリビューションの Python* (英語) (バージョン 3.10 以降) または Miniforge (英語)
CPU: 第 13 世代インテル® Core™ i5-13600K
オペレーティン・システム: Ubuntu* Server 22.04.5 LTS
Python パッケージをインストール
インテル® ディストリビューションの Python* (英語) (バージョン 3.10 以降) およびその他の必要なパッケージをインストールするには、次の手順に従います。
conda create --name py310 python=3.10 -y conda activate py310 pip install openvino-dev onnx torch torchvision intel-extension-for-pytorch opencv-python ittapi tensorflow
Python アプリケーションでインテル® VTune™ プロファイラーを実行
まず、コードを変更せずに、Intel_Extension_For_PyTorch_Hello_World.py ML アプリケーションでホットスポット解析を実行します。この解析は、コード内で最も時間のかかる領域を特定し、以降の詳細な解析の出発点となります。
コマンドラインで、次のコマンドを入力します。
vtune -collect hotspots -knob sampling-mode=sw -knob enable-stack-collection=true -source-search-dir=path_to_src -search-dir /usr/bin/python3 -result-dir vtune_hotspots_results -- python3 Intel_Extension_For_PyTorch_Hello_World.py
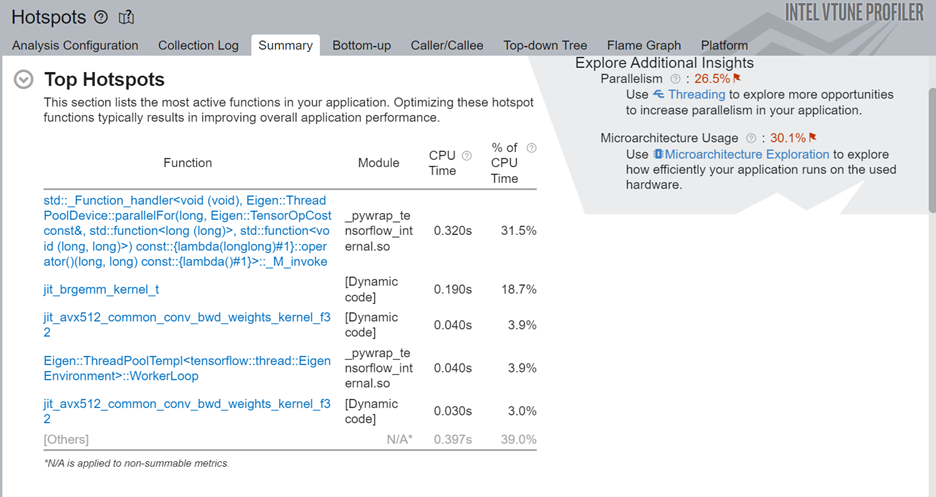
解析が完了したら、[Summary (サマリー)] ウィンドウの [Top Hotspots (上位ホットスポット)]セクションを参照して、コード内で最もアクティブな関数を特定します。
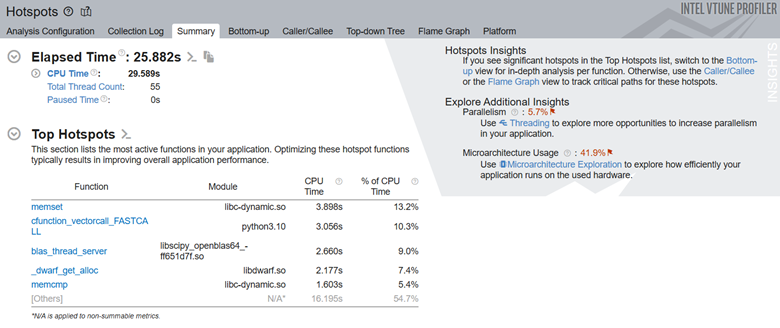
次に、アプリケーションの上位タスクを見てみましょう。

ここで、畳み込みタスクが最も長い処理時間を費やしていることがわかります。
[Bottom-up (ボトムアップ)] ウィンドウに切り替えてさらに深く掘り下げることができますが、最適化の対象となる領域を特定するのは難しい場合があります。これは、コードの各レイヤーに多くのモデル演算子と関数が存在する大規模なアプリケーションに当てはまります。解釈しやすい結果を生成するために、インテル® インストルメントとトレース・テクノロジー (ITT) API を追加します。ITT-Python API をインクルード
ここで、ITT-Python (英語) で利用可能な Python* バインディングを、インテル® VTune™ プロファイラーが使用するインテル® インストルメントとトレース・テクノロジー (ITT) API に追加します。これらのバインディングには、データ収集を制御するユーザー・タスク・ラベルと、いくつかのユーザータスク API (タスク・インスタンスを作成および破棄できる) が含まれます。
ITT-Python は 3 種類の API を使用します。
- 収集コントロール API
- ittapi.active_region
- ittapi.collection_control.resume()
- ittapi.collection_control.pause()
- タスク API
- ittapi.task
次の例では、画像分類に ITT API を使用します。この例では、OpenVINO™ (英語) の MobileNet v2 (英語) モデルを使用します。
モデルをダウンロードして変換するには、次のコマンドを実行します。
omz_downloader --name mobilenet-v2-pytorch omz_converter --name mobilenet-v2-pytorch
# openvino_sample.py
from openvino.runtime import Core
import cv2
import numpy as np
import os
import ittapi
import urllib
@ittapi.task()
def DownloadUrl(url, filename, force=False):
if not force:
if os.path.exists(filename):
print(f'{filename} already exists.Skip download from {url}')
return True
print(f'Downloading {url}')
urllib.request.urlretrieve(url, filename)
if os.path.exists(filename):
print(f'Download success.File saved {filename}')
return True
else:
print(f'Download Fail')
return False
pwd = os.getcwd();
ie = Core()
model_path = os.path.join(pwd,"public/mobilenet-v2-pytorch/FP32/mobilenet-v2-pytorch.xml")
compiled_model = ie.compile_model(model_path, "CPU")
output_layer = compiled_model.output(0)
# Download Image
with ittapi.task("Download Test Image") :
image_filename = os.path.join(pwd,"dog.jpg")
DownloadUrl("https://github.com/pytorch/hub/raw/master/images/dog.jpg", image_filename)
# Download Image Classes
with ittapi.task("Download Image classes file") :
imagenet_classes_filename = os.path.join(pwd,"imagenet_classes.txt")
DownloadUrl('https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt', imagenet_classes_filename)
# Load Image
print(f'Loading Image : {image_filename}')
with ittapi.task("Loading image and preprocessing") :
image = cv2.imread(image_filename)
image = cv2.resize(image, (224,224))
image = image.transpose(2,0,1)
image = np.expand_dims(image,0)
image = image.astype(np.float32)
with ittapi.task("Image classification") :
results = compiled_model([image])[output_layer]
probability_indexs = np.argsort(results[0])[-5:][::-1]
probabilities = results[0][probability_indexs]
#print(f'probability_indexs : {probability_indexs}')
#print(f'probabilities : {probabilities}')
#predicted_class = np.argmax(results)
# Print probable image class in Human readable format
with ittapi.task("Display classification results") :
print('Classification Results')
with open(imagenet_classes_filename, "r") as f:
categories = [s.strip() for s in f.readlines()]
for p in (probability_indexs):
print(f"\t{categories[p]}",)
上記のサンプルコードでは、注目する領域が ittapi.task ラベルでマークされています。ホットスポットとともに上位タスクを収集するには、次のコマンドを実行します。
vtune -collect hotspots -knob sampling-mode=sw -knob enable-stack-collection=true -source-search-dir=path_to_src -search-dir /usr/bin/python3 -result-dir vtune_hotspots_results -- python3 openvino_sample.py
[Top Tasks (上位タスク)] セクションには、ittapi.task ラベルでインストルメントされたコード領域の詳細が表示されます。
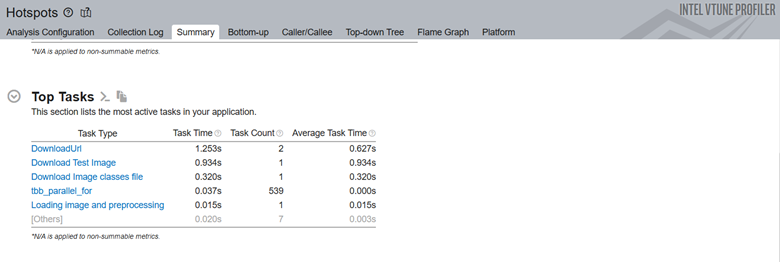
TensorFlow_HelloWorld.py (英語) の次の例では、ITT-Python でドメイン API とタスク API を呼び出します。
#Change#1
with ittapi.active_region(activator=lambda: True):
with ittapi.task("CreateOptimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
#Change#2
with ittapi.active_region(activator=lambda: True):
with ittapi.task("CreateTrainer"):
for epoch in range(0, EPOCHNUM):
for step in range(0, BS_TRAIN):
x_batch = x_data[step*N:(step+1)*N, :, :, :]
y_batch = y_data[step*N:(step+1)*N, :, :, :]
s.run(train, feed_dict={x: x_batch, y: y_batch})
'''Compute and print loss.We pass Tensors containing the predicted and true values of y, and the loss function returns a Tensor containing the loss.''’
print(epoch, s.run(loss,feed_dict={x: x_batch, y: y_batch}))上記のコード例の操作シーケンスは次のとおりです。
- ループの実行が始まる直前にプロファイルを再開します。これはコードの中で最も注目する部分です。ループは active_region API でマークされます。
- タスク API でタスクを開始します。プロファイル結果でタスクを識別するには、CreateTrainer ラベルを参照します。
- タスクが完了したら、データ収集を一時停止します。
ホットスポットとマイクロアーキテクチャ全般解析を実行
コードを修正したら、再びホットスポット解析を行います。
vtune -collect hotspots -start-paused -knob enable-stack-collection=true -knob sampling-mode=sw -search-dir=/usr/bin/python3 -source-search-dir=path_to_src -result-dir vtune_data -- python3 TensorFlow_HelloWorld.py
このコマンドは、-start-paused パラメーターを指定して、ITT-Python API でマークされたコード領域のみをプロファイルします。修正後のホットスポット解析の結果を見てみましょう。[Top Hotspots (上位ホットスポット)] セクションには、ITT-Python API でマークされたコード領域のホットスポットが表示されます。右上隅の [Insights (調査)] セクションでは、ホットスポットをさらに詳しく理解するために実行すべき追加の解析が推奨されます。
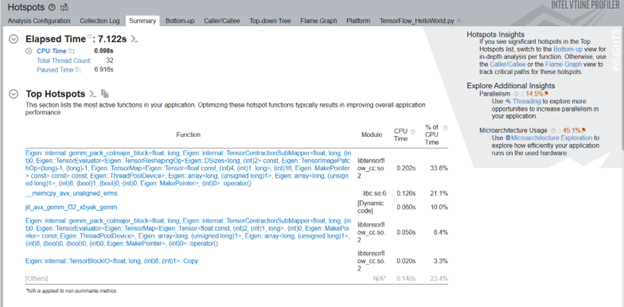
ターゲットコード領域で最も時間のかかる ML プリミティブを調査します。最適化を進めるには、まずこれらのプリミティブに注目します。ITT-API を使用すると、ML プリミティブに関連性の高いホットスポットをすばやく識別できます。
次に、ITT-Python API で対象とする上位タスクを確認します。これらの API を使用すると、プロファイルの結果を特定のコード領域に限定できます。
この例では、2 つの ITT 論理タスクを使用します。
- CreateTrainer
- CreateOptimizer
これらのタスクをクリックすると、次のような詳細が表示されます。
- CPU 時間
- 有効時間
- スピン時間
- オーバーヘッド時間
- CPU 利用率時間
- ソースコード行レベル解析
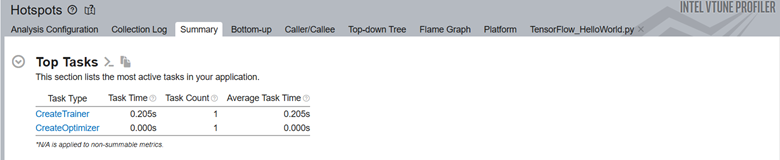
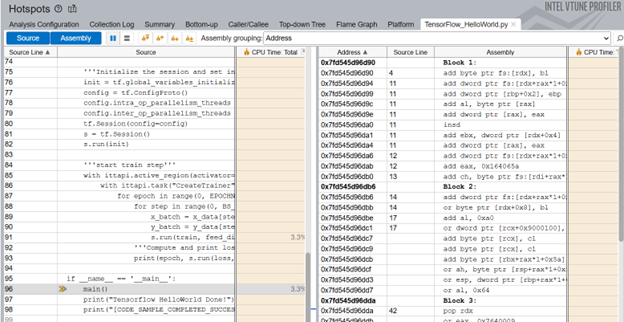
ML コードのソース行レベルのプロファイルにより、CPU 時間のソース行の内訳が明確になります。この例では、コードはモデルのトレーニングに合計実行時間の 3.3% を費やしています。
アプリケーションのパフォーマンスをより詳しく理解するため、マイクロアーキテクチャー全般解析を実行します。コマンドプロンプトから次を入力します。
vtune -collect uarch-exploration -knob collect-memory-bandwidth=true -source-search-dir=path_to_src -search-dir /usr/bin/python3 -result-dir vtune_data_tf_uarch -- python3 TensorFlow_HelloWorld.py
解析が完了すると、[Bottom-up (ボトムアップ)] ウィンドウに、ITT-Python API でマークされたタスクの詳細なプロファイル情報が表示されます。
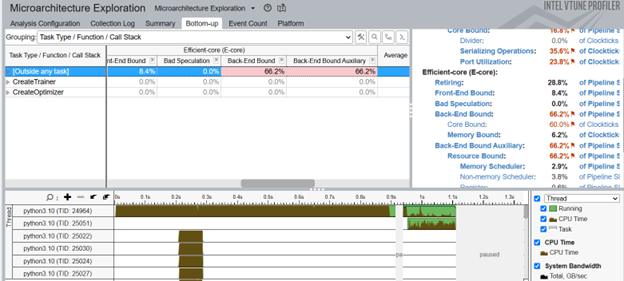
CreateTrainer タスクはバックエンド依存であることがわかります。つまり、バックエンドがリソースを受け取るまで待機するのに多くの時間が無駄に費やされていることになります。この状態は、次の問題を示しています。
- メモリーアクセス
- データ依存関係
- 実行ユニット競合
より小さなコードブロックに解析を集中するには、CreateTrainer タスクから 1 つを右クリックしてフィルター処理を有効にします。
PyTorch ITT API を追加 (PyTorch フレームワーク向けのみ)
ITT-Python API と同様に、インテル® VTune™ プロファイラーでは PyTorch* ITT API (英語) も使用できます。PyTorch ITT API を使用して、個々の PyTorch 演算子の時間範囲にラベル付けし、カスタマイズされたコード領域の詳細な解析結果を取得します。PyTorch 1.13 では、インテル® VTune™ プロファイラーで使用するため次のバージョンの torch.profiler.itt API が提供されています。
- is_available()
- mark(msg)
- range_push(msg)
- range_pop()
Intel_Extension_For_PyTorch_Hello_World.py (英語) のコードでこれらの API がどのように使用されるか確認してみましょう。
with ittapi.active_region(activator=lambda: True):
with torch.autograd.profiler.emit_itt():
torch.profiler.itt.range_push('training')
model.train()
for batch_index, (data, y_ans) in enumerate(trainLoader):
data = data.to(memory_format=torch.channels_last)
optim.zero_grad() y = model(data)
loss = crite(y, y_ans)
loss.backward()
optim.step()
torch.profiler.itt.range_pop()上記の例では、次の一連の操作が示されています。
- ループが実行される直前にプロファイルを再開するには、itt.resume() API を使用します。
- 特定のコード領域をプロファイルするには、torch.autograd.profiler.emit_itt() API を使用します。
- range_push() API を使用して、ネストされた範囲スパンのスタックに範囲をプッシュします。メッセージ ('training') を付けてマークします。
- 注目するコード領域に挿入します。
- ネストされた範囲スパンのスタックから範囲をポップするには、range_pop() API を使用します。
PyTorch ITT API でホットスポット解析を実行
ここで、PyTorch ITT API で修正されたコードのホットスポット解析を実行します。コマンドプロンプトから次を入力します。
vtune -collect hotspots -start-paused -knob enable-stack-collection=true -knob sampling-mode=sw -search-dir=/usr/bin/python3 -source-search-dir=path_to_src -result-dir vtune_data_torch_profiler_comb -- python3 Intel_Extension_For_PyTorch_Hello_World.py
注目するコード領域内の上位ホットスポットは次のとおりです。
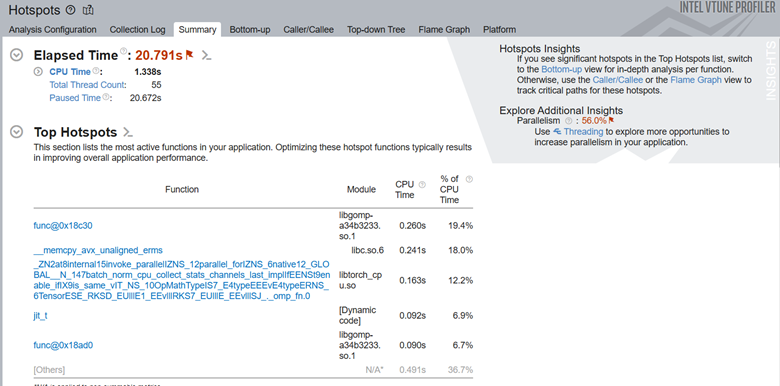
[Summary (サマリー)] の [Top Tasks (上位タスク)] セクションには、ITT-API を使用してラベル付けされたトレーニング・タスクが表示されます。
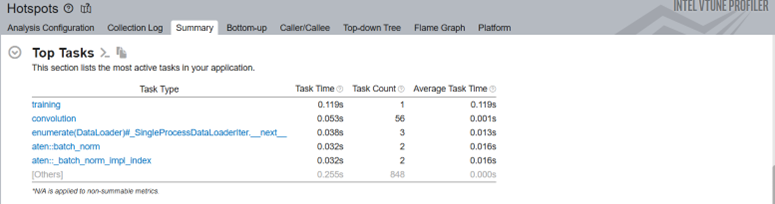
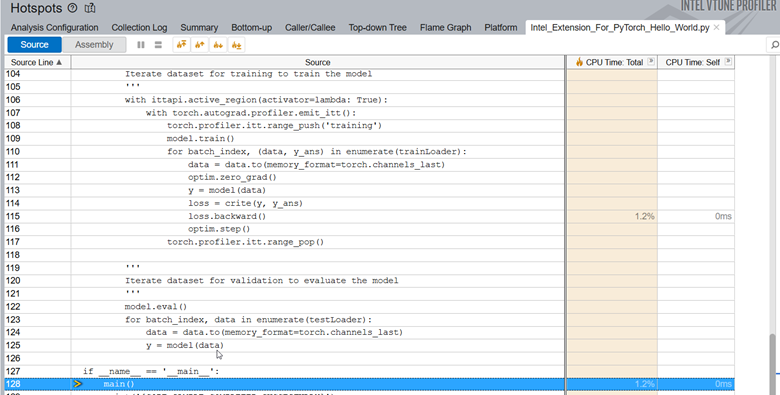
PyTorch コードのソース行プロファイルを調べると、コードが loss.backward() に合計実行時間の 1.2% を費やしていることがわかります。
[Platform (プラットフォーム)] ウィンドウに切り替えて、PyTorch* ITT API でマークされたトレーニング・タスクのタイムラインを表示します。

タイムラインでは、メインスレッドは python3 (TID:30787) で、小さなスレッドがいくつか含まれています。aten::batch_norm、aten::native_batch_norm、aten::batch_norm_i で始まる演算子名はモデル演算子です。これらのモデル演算子は、PyTorch の ITT によって暗黙的にラベル付けされます。
プラットフォーム・ウィンドウから、次の詳細を取得できます。
- 個々のスレッドごとの CPU 使用率 (特定の期間)
- 開始時間
- ユーザータスクとoneDNNプリミティブ (畳み込み、並べ替え) の所要時間
- 各タスクおよびプリミティブのソース行。タスク/プリミティブのソースファイルがデバッグ情報付きでコンパイルされていたら、タスク/プリミティブをクリックしてソース行を表示します。
- 反復回数ごとにグループ化されたプロファイル結果 (複数の反復がある場合)
