
この記事は、The Parallel Universe Magazine 47 号に掲載されている「Hyperparameter Optimization with SigOpt for MLPerf Training on Habana Gaudi*」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

大規模なディープラーニング (DL) のトレーニング・ワークロードのパフォーマンスを最適化するには、コストがかかります。多くの専門分野にわたるチームからの貢献に加え、DL トレーニング用に設計された大規模な計算インフラストラクチャーが必要です。最適化手法は多岐にわたり、データ並列トレーニング・パラダイムの集合演算の計算/ 通信関連の最適化、独立タスクのオーケストレーション/スケジューリング、データセットの前処理/拡張のパイプライン化、収束率を高める軽量なアルゴリズムの最適化、fp32 と bfloat16 の混合精度を利用した数値的最適化などがあります。
この記事では、ハイパーパラメーター最適化 (HPO) に基づき、目標精度 (収束エポック) を維持しつつ、トレーニング・エポック数を削減する最適化手法に注目します。ここでは、Habana* Gaudi* トレーニング・プロセッサーのMLPerf* トレーニング・ワークロードに HPO を適用します。AI に特化したインテルの Habana Labs と SigOptが共同で行ったこの作業では、モデルのトレーニング時間が改善され、ResNet50 (RN50) モデルの最適なハイパーパラメーターを得るために必要な計算リソースが減少し、グリッド検索の利点を活用して MLPerf* モデルのトレーニング時間を短縮し、グリッド検索に関連した Gaudi* 時間を短縮できました。
MLPerf* トレーニング・ワークロード
2018 年以降、MLPerf* (英語) ベンチマーク・スイートは、多種多様なコンピューティング・インフラストラクチャー上で動作する幅広いニューラル・ネットワーク・モデルを評価するため、AI コミュニティーによって使用されています。AI の急速な進化を反映するため、ニューラル・ネットワークは提出のたびに再評価されています。RN50 トレーニングには、LARS (Layer-wise Adaptive Rate Scaling) (英語) アルゴリズム (図 1) を活用します。ハイパーパラメーターとそれぞれの MLPerf* の制約を表 1 に示します。このワークロードでは、75.9% という特定の目標精度(AC) を達成する必要があります。

図 1. HPO で使用されるハイパーパラメーターを示す LARS の疑似コード
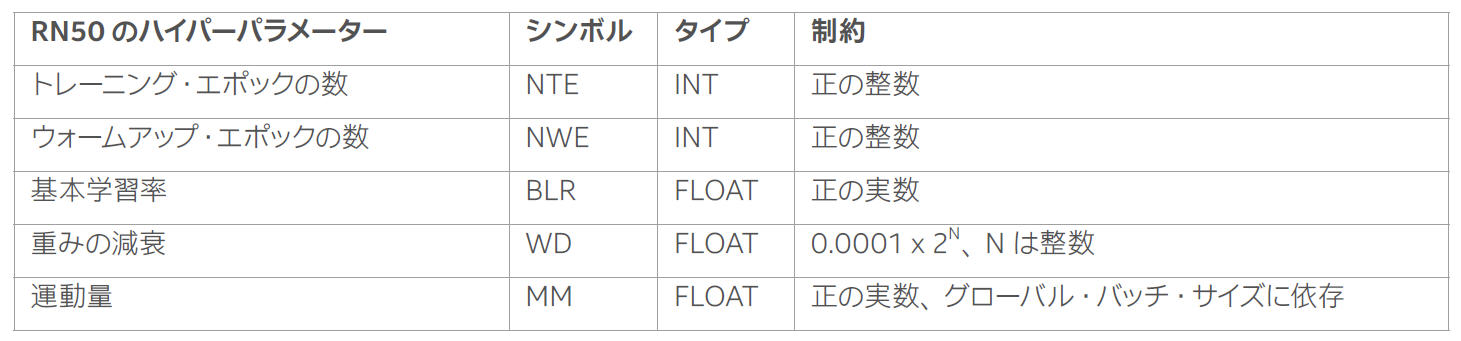
表 1. ハイパーパラメーターと MLPerf* の制約
大規模なトレーニングと HPO ワークフロー・プロセスの統合
図 2 は、オンプレミスまたはクラウドベースのトレーニング・クラスターの概念図です。AI ユーザーはこのクラスターにアクセスして、トレーニング・ジョブのバッチをコンピューティング・インフラストラクチャーに送信し、実行したジョブの精度 (AC) と収束したエポック数 (CE) を受け取ります。この情報は SigOpt に送られ、SigOpt は新しいハイパーパラメーターの提案をユーザーに返します。ユーザーは、目標精度に到達し、可能な限り低い収束エポックを見つけるという最適化目標が達成された時点で、ハイパーパラメーター検索を継続、調整、停止するように条件をプログラムできます。
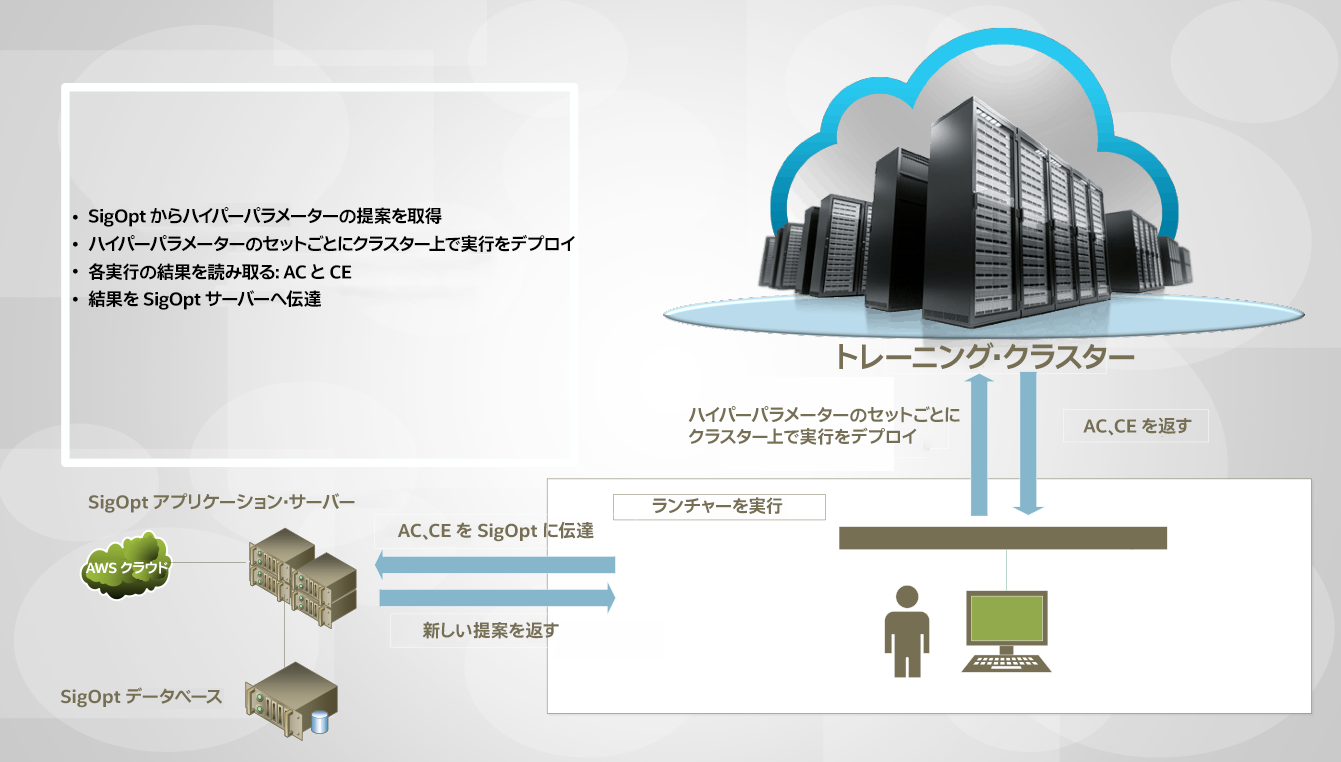
図 2. SigOpt と AI ユーザーが HPO の進捗を制御するトレーニング・クラスターでのトレーニング・ジョブの実行
SigOpt を使用した HPO ワークフロー
図 3 は、SigOpt を使用した H PO ワークフローの現時点の実装です。以下の変数を定義して SigOpt を起動します。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
