


この記事は、インテルの The Parallel Universe Magazine 28 号に収録されている、オープンソースの分散型ディープラーニング・フレームワークでディープラーニングの普及を促進する取り組みを紹介した章を抜粋翻訳したものです。
人工知能 (AI) は現代のスマートで接続された世界で中心的な役割を果たしており、ディープラーニング機能を備えた、スケーラブルな分散型ビッグデータ解析の必要性は高まるばかりです。また、特徴量の設計や従来のマシンラーニングをサポートする既存のデータ処理パイプラインとディープラーニングを同じクラスターで処理したいという要望も増えています。ビッグデータの解析とディープラーニング向けの統一プラットフォームを求める声に応えるため、インテルは、Apache Spark* 向けのオープンソース分散型ディープラーニング・フレームワーク、BigDL (英語) を最近リリースしました。この記事では、BigDL の機能と BigDL を使用してモデルを作成する方法を紹介します。
BigDL は Spark* の上位のライブラリーとして実装され (図 1)、スケールアウト・コンピューティングを容易に行うことができます。BigDL を利用すると、ディープラーニング・アプリケーションを既存の Spark* または Hadoop* クラスター上で直接実行できる標準 Spark* プログラムとして記述することができます。
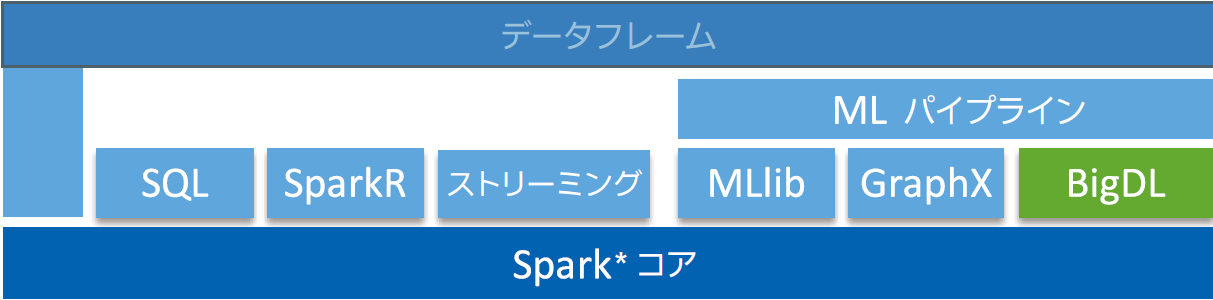
図 1. BigDL の実装
BigDL は、次の特長を備えており、ビッグデータおよび Spark* プラットフォームでディープラーニング機能をネイティブにサポートします。
- ディープラーニングの包括的なサポート。Torch を手本に開発された BigDL は、数値計算 (テンソルなど) や高レベルのニューラル・ネットワークを含む、ディープラーニングの包括的なサポートを提供します。さらに、BigDL を使用して、訓練された Caffe* または Torch のモデルを Spark* プログラムにロードすることもできます。
- 非常に高いパフォーマンス。高いパフォーマンスが得られるように、BigDL は各 Spark* タスクでインテル® マス・カーネル・ライブラリー (インテル® MKL) およびマルチスレッド・プログラミングを使用します。そのため、シングルノードのインテル® Xeon® プロセッサー (メインストリーム GPU と同等) でオープンソースの Caffe*、Torch、TensorFlow* をそのまま利用するよりもはるかに高速です。
- 効率的なスケールアウト。BigDL は、Apache Spark* を活用して、Spark* での同期 SGD や Allreduce 通信の効率的な実装により、効率的にスケールアウトしてビッグデータ・スケールでデータ解析を実行できます。
Spark* とのネイティブ統合は、BigDL の重要な利点です。BigDL は Spark* の上に構築されるため、ディープラーニングにおいて計算負荷の高いモデルの訓練を簡単に分散できます。計算を明示的に分散するように要求するのではなく、BigDL は Spark* クラスター全体にワークを自動的に分配します。
BigDL は (データストレージ、データ処理/ データマイニング、特徴量の設計、典型的なマシンラーニング、ディープラーニング向けの) 統一データ解析プラットフォームとして Hadoop* と Spark* をサポートし、ビッグデータのユーザーやデータ・サイエンティストがディープラーニングをより簡単に利用できるようにします。
典型的な BigDL のユースケースは次のとおりです。
- 大量のデータをその格納場所 (HDFS*、HBase*、Hive* など) と同じビッグデータ (Hadoop* および Spark*) クラスター上でディープラーニング・テクノロジーを使用して解析し、別のシステムとの間の大量の不要なデータ転送を排除します。
- ディープラーニング機能 (訓練、微調整、予測など) をビッグデータ (Spark*) プログラムやワークフローに追加して、システムの複雑さやエンドツーエンドのレイテンシーを減らします。
- 既存の Hadoop* および Spark* クラスターを活用してディープラーニング・アプリケーションを実行し、ほかのワークロード (ETL、データ・ウェアハウス、特徴量の設計、典型的なマシンラーニング、グラフ解析など) を動的に共有します。
BigDL を利用する
BigDL は、数値計算 (テンソルなど)、高レベルのニューラル・ネットワーク、分散型確率的最適化 (Spark* での同期ミニバッチ SGD や Allreduce 通信など) を含む、ディープラーニングを包括的にサポートします。表 1 は、BigDL で提供される抽象化と API をまとめたものです。
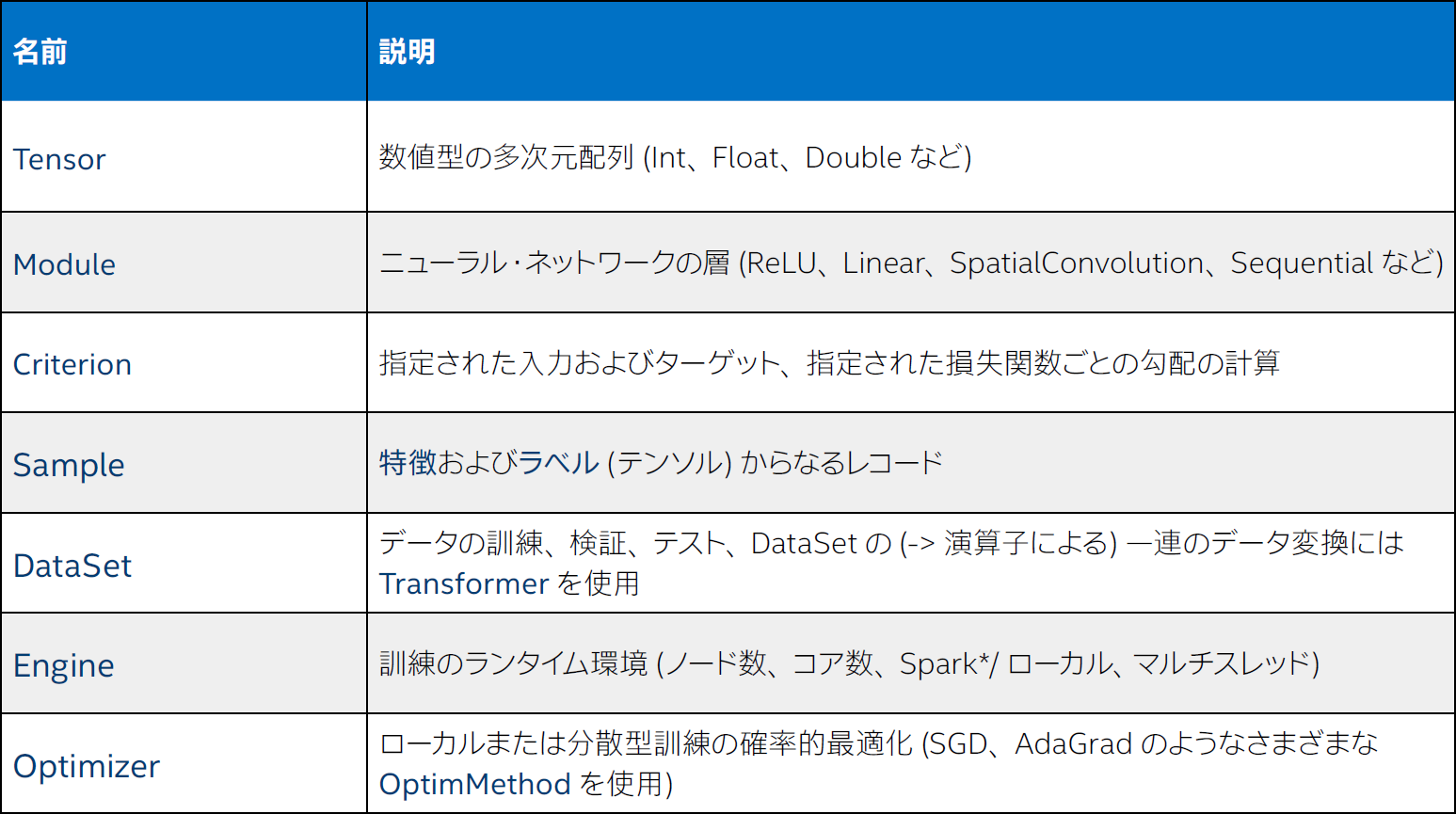
表 1. BigDL の抽象化と API
BigDL プログラムは、ローカル Scala*/Java* プログラムとして、または Spark* プログラムとして実行できます。[編集者注: Python* のサポートはまもなく行われます。この記事が掲載される頃にはサポートされているでしょう。] 対話型の Scala* シェル (REPL) を使用して BigDL コードをローカル Scala*/Java* プログラムとして 作成するには、最初に次のように入力します。
$ source PATH_To_BigDL/scripts/bigdl.sh $ SPARK_HOME/bin/spark-shell --jars bigdl-0.1.0-SNAPSHOT-jar-with-dependencies. jar
