
この記事は、The Parallel Universe Magazine 58 号に掲載されている「JAX and OpenXLA* Part 1: Run Process and Underlying Logic」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

この記事では、JAX フレームワークと OpenXLA バックエンドにおける Python プログラムの実行ワークフローと、基本となる動作ロジックについて考察します。まず、OpenXLA の高レベル統合構造と JAX の基本的な概念の概要を説明します。インテルの GPU 上で OpenXLA を使用した JAX の実行例を示すことで、Python プログラムが JAX フレームワークによってどのように認識され、StableHLO 表現に変換されるか詳細な分析を提供します。次に、OpenXLA はこれらの StableHLO 表現を HLO (高水準操作) に解析します。
この記事では、JAX フレームワークと OpenXLA コンパイラーがどのように Python プログラムを解釈するかについて初期考察を提供し、より複雑なモデルの実行と分析の基礎を築きます。これは、インテルのGPU 上でOpenXLA コンパイラー開発に取り組む開発者や、JAX/OpenXLA モデルのデバッグに携わる開発者にとって、基礎的なガイドとなるでしょう。
JAX: Auto-grad と XLA
JAX (英語) は、高性能数値計算と大規模マシンラーニング向けに設計された、アクセラレーター指向の配列計算とプログラム変換用の Python ライブラリーです。XLA (Accelerated Linear Algebra) (英語) は、マシンラーニング向けのオープンソース・コンパイラーです。
OpenXLA* 向けインテル® エクステンション
OpenXLA (英語) プロジェクトは、開発者コミュニティーと主要な人工知能 (AI) およびマシンラーニング (ML) チームを結集して、ML を加速し、ML フレームワークとハードウェア間のインフラストラクチャーの断片化に対処します。
OpenXLA* 向けインテル® エクステンション (英語) には、インテルの GPU 上で JAX モデルをシームレスに実行する PJRT プラグインが実装されています。PJRT API は統合を簡素化するため、インテルの GPU 用のプラグインを個別に開発し、JAX に迅速に統合することができます。この PJRT 実装により、XLA アクセラレーションを使用した TensorFlow および PyTorch モデルにおけるインテルの GPU の初期サポートも可能になります。詳細は、「RFC : OpenXLA PJRT プラグイン」 (英語) を参照してください。
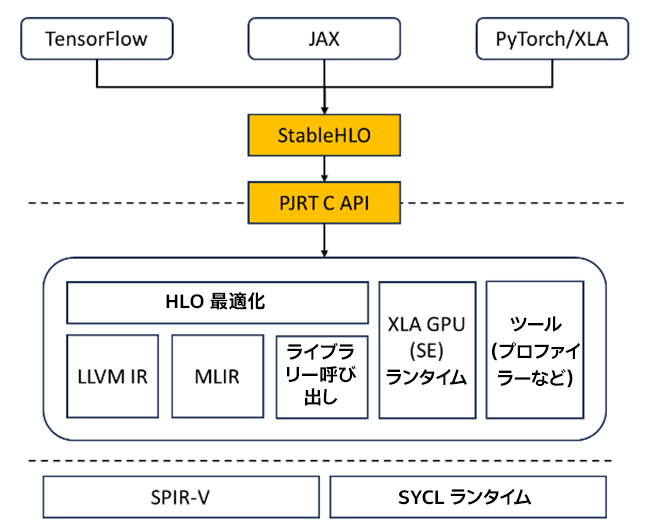
図 1. PJRT プラグインが実装された OpenXLA* 向けインテル® エクステンション (出典 (英語))
JAX と OpenXLA* 向けインテル® エクステンションの組み合わせにより、インテルの GPU においてハードウェア適応とモデル ・アクセラレーションが向上します。
実際の実行ロジック
JAX フレームワークが Python プログラムを解析し、OpenXLA が計算グラフを生成し、演算は GPU ハードウェア上で実行されます。
以下の実行プロセスと詳細は、JAX と OpenXLA の開発およびデバッグのプロセスを示しています。プロセス全体は、JAX 表現、StableHLO、初期 HLO、最終 HLO、初期 LLVM IR、最終 LLVM IR、および SPIR-V ファイルの各フェーズに分かれています。
それでは、実際のコード例を使って説明しましょう。
import jax.numpy as jnp
from jax import grad
def simple_function(x):
return x**2 + 3*x + 2
gradient = grad(simple_function)
x = 2.0
computed_gradient = gradient(x)
print(“Computed Gradient:”, computed_gradient)
