
この記事は、The Parallel Universe Magazine 48 号に掲載されている「Winning the NeurIPS Billion-Scale Approximate Nearest Neighbor Search Challenge」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

近似最近傍探索 (ANN) (英語) とも呼ばれる類似性探索は、ウェブスケールのデータベース上で検索、推薦、ランキング操作を必要とする多くの AI アプリケーションのバックボーンであり、精度、スピード、スケール、コスト、そしてサービス品質制約が重要になります。この記事では、インテル® Xeon® プロセッサーとインテル® Optane™ メモリーの能力を活用することで、ANN を進化させるソリューションについて説明します。これらの進化を示すため、我々は NeurIPS’21 億単位の近似最近傍探索コンテスト (https://big-ann-benchmarks.com/) に参加し、カスタム・ハードウェア・トラックで優勝しました。我々のソリューションは、CAPEX (資本的支出) を 1/8 ~1/19 に削減し、5 年間の OPEX (営業費用) を第 2 位のソリューション (英語) と同等に抑えました。これにより、現代の大規模で高精度かつハイパフォーマンスなシナリオにおける類似性検索の参入障壁を大幅に下げ、普及を促進します。
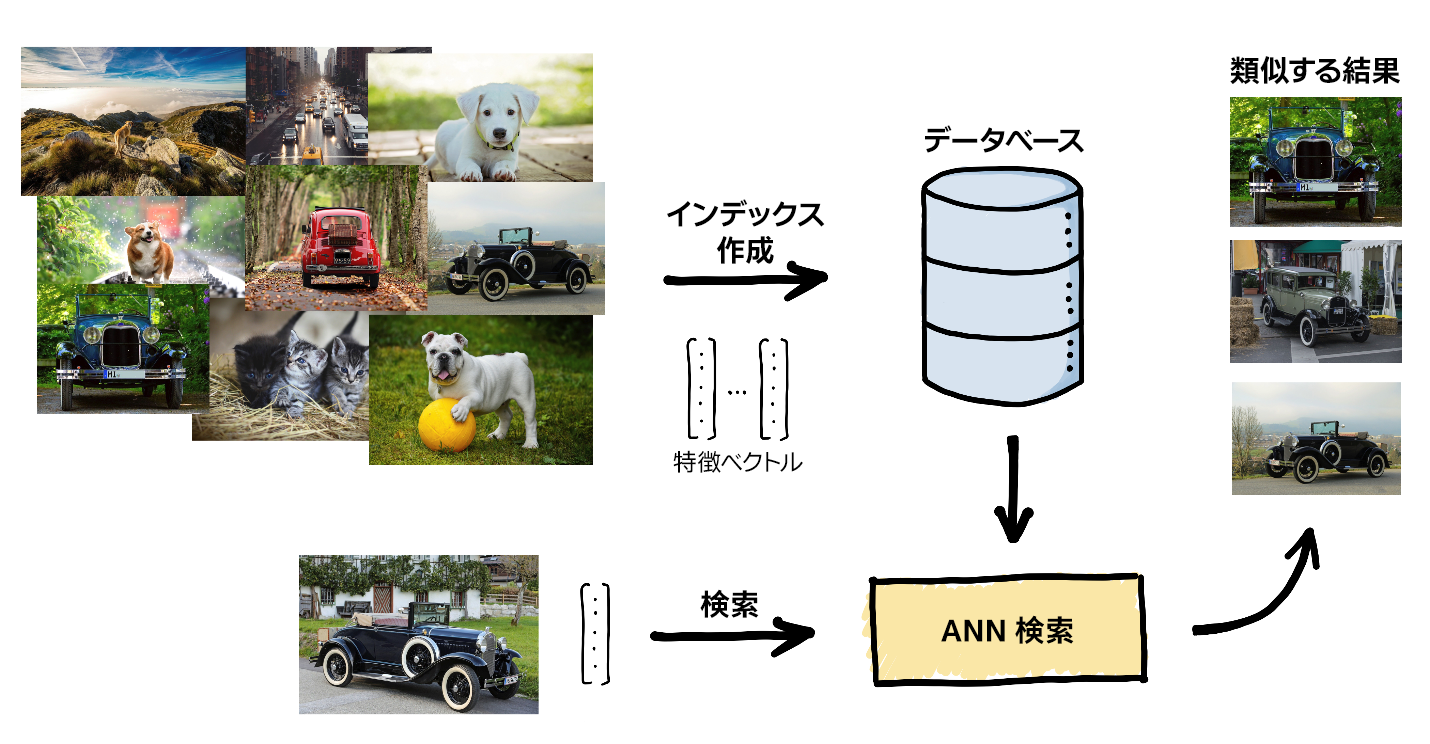
図 1. ANN 検索パイプラインの概略図
近似最近傍探索
類似性検索の目的は、与えられた高次元特徴ベクトルのデータベースと同次元のクエリーベクトルに対し、何らかの類似性関数に基づいて、クエリーと最も類似するデータベース・ベクトルを検索することです (図 1)。現代のアプリケーションでは、これらのベクトルはデータ (画像、音声、テキストなど) の内容を表し、類似したベクトルが意味的に関連する項目に対応するように、ディープラーニング・システムを使用して抽出および要約されます。
実際に有用であるには、類似性検索ソリューションはさまざまな価値を提供する必要があります。
- 精度: 検索結果が実用に耐えられる品質でなければなりません (つまり、検索された項目がクエリーに類似している必要があります)。
- パフォーマンス: 検索は高速で、多くの場合、厳格なサービス品質制約を満たす必要があります。
- スケーラビリティー: データベースは、含まれる項目の数や次元数など、ますます大きくなっています。
- コスト: 本番環境やデータセンターで使用されるため、 総所有コスト (TCO) を最小化する必要があります。TCO は通常、資本的支出 (CAPEX) と営業費用 (OPEX) の組み合わせとして測定されます。
自然なソリューションとして、データベース内の各ベクトルを線形にスキャンし、クエリーと比較し、結果を類似度の降順でランク付けし、最も類似したベクトルを返すことが考えられます。しかし、データの膨大さと豊富さから、このアプローチは不可能であり、計算とメモリーの両方を多用する大規模な類似性検索は、非常に困難な問題です。一般に、次の 2 つのフェーズを含む優れたソリューションを必要とします。
- インデックス作成時には、データベースの各要素を高次元ベクトルに変換し、検索時にデータベースの一部にのみアクセスするようにインデックスを作成します。
- 検索時には、与えられたクエリーベクトルに対し、アルゴリズムはインデックスを使用してデータベースをふるいにかけます。その結果は、最終的な用途に応じて、またこれらの意味的に関連した結果に基づいて、さまざまな情報に基づいた行動を取るために使用されます。
NeurIPS’21 億単位の近似最近傍探索コンテスト
2021年12月、NeurIPS カンファレンスの一環として、初の億単位の類似性検索コンテストが開催されました。コンテストの目的は、精選された実際のデータセットで最先端の類似性検索を比較検討し、新しいソリューションの開発を促進することでした。我々は、インテルのハードウェアをフル活用できるカスタム・ハードウェア・トラックに参加しました。インテル® Xeon® プロセッサーとインテル® Optane™ パーシステント・メモリー (PMem) の機能をフル活用したソリューションを開発し、ワンツーアプローチを実現した結果、最終的にコンテストで優勝を勝ち取りました。
データセット間で比較される基本的なメトリックは TCO で、90% の再現率と 10 万クエリー/秒 (QPS) のスループットを持つソリューションの CAPEX + 5 年間の OPEX として定義されました。CAPEX と OPEX (英語) は、コンテスト主催者によって次のように定義されています。
- CAPEX = (すべてのハードウェア・コンポーネントの希望小売価格) × (100,000QPS をサポートするのに必要な最小システム数)
- OPEX = (ベースライン再現率 @10 しきい値以上の最大 QPS) × (キロワット時/クエリー) × (秒/時間) × (時間/年) × (5 年間) × (ドル/キロワット時) × (100,000QPS に対応するのに必要な最小システム数)
これらのメトリックは、各ソリューションの電力効率 (OPEX) と生のパフォーマンス (CAPEX) のバランスをとります。
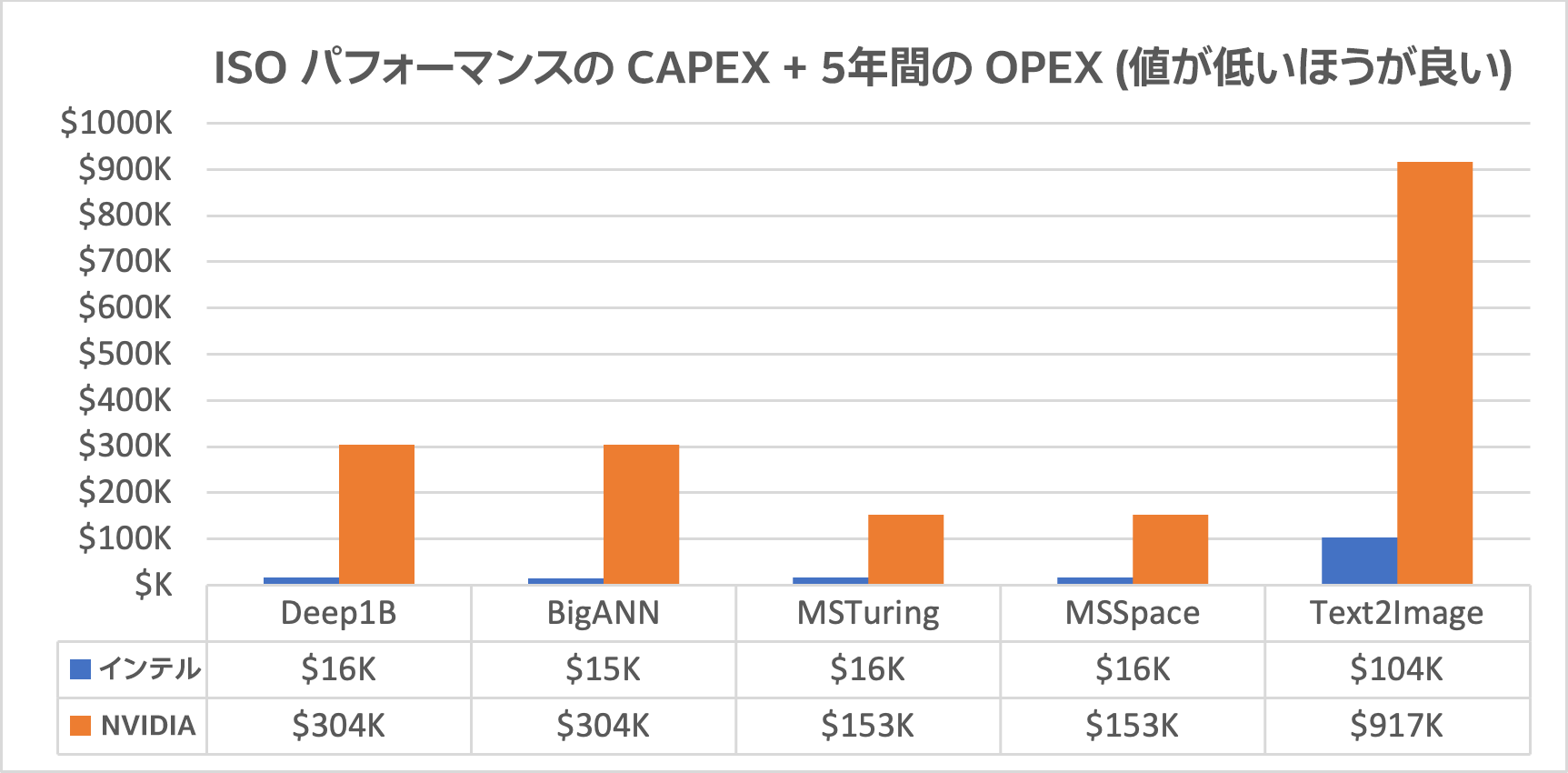
図 2. 優勝したインテルベースのソリューションと第 2 位の NVIDIA* ベースのソリューションの TCO の相違点
(5 つの異なるデータセット (X 軸) で最大 20 倍の向上を達成)
我々のソリューションは TCO を画期的に改善し、第 2 位の複数のデータセットで NVIDIA DGX* A100 GPU システムを使用する cuanns_multigpu と比較して、8.85 ~19.7 倍の効率を実現しています (図 2)。 この圧倒的な差は、我々と第 2 位の NVIDIA* のハードウェア構成を比較すると明白です (表 1)。インテル® Optane™ パーシステント・メモリーを搭載した安価な 1U 2S インテル® Xeon® プロセッサー・ベースのサーバー 1 台で、A100 GPU を 8 個、ANN 検索ワークロード用の 64 コア CPU を 2 個搭載した NVIDIA* のフラッグシップである NVIDIA DGX* A100 サーバーと同等のパフォーマンスを達成することが可能です。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
