

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Using Tasking to Scale Game Engine Systems」(http://software.intel.com/en-us/articles/using-tasking-to-scale-game-engine-systems/) の日本語参考訳です。
はじめに
6 コア、12 ハードウェア・スレッドのゲーム用デスクトップが市場に登場してからかなり経ち、今ではラップトップでさえも 4 コア CPU が一般的になりつつあります。特定のプラットフォームに依存せずその機能を最大限活用できるように、ここではコア数に依存しないゲーム・エンジン・コードの記述方法を紹介します。
タスク処理を実装することで、コア数の増加に伴いプログラムはスケーリングし、ハードウェアの機能を最大限活用してゲームを楽しめます。サンプルプログラムを例に、シングルスレッドのアニメーション・システムを、タスク処理を使用するアニメーション・システムに変換してみましょう。
タスク処理に関連する用語
- タスク: タスクとは、システムの独立した作業単位です。タスクはコールバック関数として実装されます。ここでは、アニメーション・システムのタスク処理について取り上げ、それぞれのタスクはシーンのモデルを描画します。
- タスクセット: タスクセットとは、アプリケーションのスケジューリング・プリミティブです。作業をスケジューリングするために、アプリケーションはタスクセットを生成し、タスク関数と依存関係の情報を指定します。
- 依存性グラフ: タスクセット内のタスクは非同期に実行されます。タスクセットは、その依存関係が満たされた場合のみ実行されます。
- スケジューラー: スケジューラーはタスク API の内部で使用され、すべての作業スレッドの生成と管理、そしてタスクの実行を行います。
このサンプルプログラムでは、スケジューラーとしてインテル® スレッディング・ビルディング・ブロックを使用しています。
図 1 は、4 コアシステムにおけるタスクセットの依存性グラフを表したものです。スケジューラーは、すべての依存関係が満たされると、タスクセットにあるそれぞれのタスクを直ちに実行します。
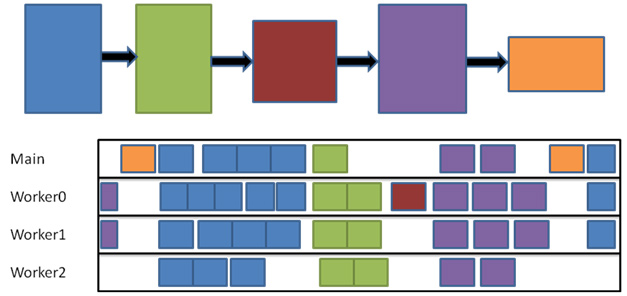
図 1. 依存性グラフとスケジューラーによるタスクの実行をビジュアル化したもの
優れたタスクの生成
タスク関数には、次の 4 つの引数があります (リスト 1 を参照)。
- pvInfo: タスクセットに対するグローバルなデータへのポインター。このデータは不変のバッファーと考えることができます。タスク API によって実データが所有されているわけではないので、タスクセットを実行している間、データが有効であることを、アプリケーションで確認する必要があります。
- iContext: 0 からスケジューラーによって生成された最大スレッド数までの範囲のインデックス。この値により、スレッドセーフでないデータへのロックフリー (ロックを利用しない)・アクセスが可能になります。タスク API は、1 つの実行タスクだけが特定のコンテキスト ID を持つことを保証します。
コンテキスト ID の模範的な使用例は D3D11DeviceContext です。アプリケーションは、D3D11DeviceContext オブジェクトの配列を生成します。コマンドリストを描画するタスクは、このコンテキスト ID を使用することで、ロックを使用しなくても、配列から D3D11DeviceContext オブジェクトを選択できます。 - uTaskId: タスク ID は、タスク関数で実行中のタスクを示します。このインデックスは、リストからタスクの作業を選択するのに使用されます。サンプルプログラムでは、描画するモデルを選択するのに使用しています。
- uTaskCount: タスクセットで実行するようにスケジューリングされているタスクの合計数。この値を使用して、タスク ID を処理するオブジェクト群にマップできます。
void
AnimateModel(
VOID* pvInfo,
INT iContext,
UINT uTaskId,
UINT uTaskCount );
リスト 1. タスク関数のシグネチャー
効率良いタスクを生成するには、プロセッサーのアーキテクチャーを活用して、スケジューラーができるだけ効率良く作業をコアに分配できるようにする必要があります。次のヒューリスティックにより、タスクの実行を最適化できます。
- タスクの実行時間はタスクセットの合計実行時間のほんの一部でなければならない。これにより、スケジューラーはコア間で作業の分配を最適化できます。タスクのスケジューリングには一定の時間がかかるため、この時間を最小限に抑えつつ、最高のスケーリングを達成するには、最適なタスク数を使用することが重要になります。
サンプルプログラムではタスク処理によりモデルを描画していますが、シーンに 20 以上のモデルがある場合にのみ、このヒューリスティックが達成できます。最適なタスク数を見つけるには、タスク ID とタスクカウントを使って各タスクで処理されるデータ量を調整するのが最良の方法といえるでしょう。 - タスクのワーキングセットが L2 キャッシュサイズの 1/4 になるようにする。多くのプロセッサーはインテル® ハイパースレッディング・テクノロジーに対応しているため、1 物理コアにつきワーカースレッドが 2 つ存在します。1 タスクにつきワーキングセットをキャッシュの 1/4 にすることで、キャッシュが最適に使用されます。
最適なタスク数を見つけるには、タスク ID とタスクカウントを使って各タスクで処理されるデータ量を調整するのが最良の方法といえるでしょう。 - ロック命令やインターロック命令の代わりにコンテキスト ID を使用する。タスク内でロックを使用すると、ワーカースレッドがブロックされ、タスクの実行パフォーマンスが大幅に低下します。これには、一般にロックを必要とするメモリーの割り当てが含まれます。インターロック操作もキャッシュ・スラッシングを引き起こします。タスクセットでロックが必要な場合は、タスクセットを 2 つ生成することを検討してみてください (以下を参照)。
- オーバーラップ・フレームによる枯渇時間を回避する。
枯渇は、タスクセットが間もなく完了するというときに、スケジューラーに実行可能なタスクセットがない場合に発生します (以下を参照)。
依存関係を使用してインターロック操作を回避
タスクを使用してイメージの平均輝度を計算する例について考えてみましょう。最初のアプローチでは、各タスクでスキャンラインのセットを処理し、インターロックされた加算代入により合計を求めます。この場合、タスクのパフォーマンスは、合計値が格納されているキャッシュラインのロックにかかる時間によっておそらく制限されるでしょう。
より良いアプローチでは、各タスクの合計値を格納する配列を作成します。これにより、各タスクはインターロック操作を使わなくても、コンテキスト ID を使用して現在の合計を加算できるようになります。そして、2 つ目のタスクセットで 1 つのタスクを使って、配列の合計を求め、最終的な平均値を計算します。この 2 つ目のタスクセットは、1 つ目のタスクセットに依存します。
枯渇の回避
図 2 に、依存性グラフの実行で発生する枯渇時間 (赤い丸で囲まれた部分) を示します。これらの枯渇時間は、スケジューラーに実行可能なタスクセットがないため有効利用することができません。この依存性グラフがフレーム単位で処理される作業を表したものだと仮定すると、プロセッサーで同時に 2 つのフレームを実行できるため、 フレーム n の枯渇時間をフレーム n -1 の作業によって埋めることができます (図 3 を参照)。
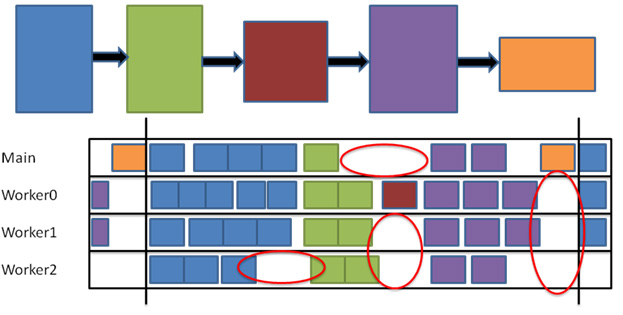
図 2. 依存性グラフの実行と枯渇時間
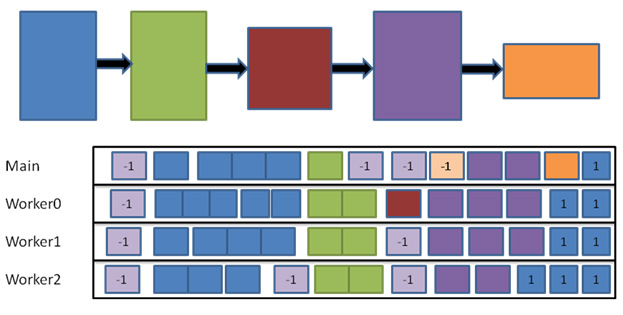
図 3. オーバーラップした依存性グラフの実行
サンプルプログラムでのタスク処理の使用
アニメーション・サンプルでは、1 つのタスクで 1 つのモデルを描画するように定義しています (リスト 2 を参照)。シーンを描画するには、描画するモデル数と生成されるタスク数が等しくなるようにタスクセットを生成します。各タスクは、タスク ID (uModel) を使用して、リストの中からそのタスクで描画するモデルを特定します。グローバル・データ・ポインター (pvInfo) には、フレームのアニメーション時間が含まれています。
void
AnimateModel(
VOID* pvInfo,
INT iContext,
UINT uTaskId,
UINT uTaskCount )
{
D3DXMATRIXA16 mIdentity;
PerFrameAnimationInfo* pInfo = (PerFrameAnimationInfo*)pvInfo;
D3DXMatrixIdentity( &mIdentity );
gModels[ uModel ].Mesh.TransformMesh(
&mIdentity,
pInfo->dTime + gModels[ uModel ].dTimeOffset );
for( UINT uMesh = 0; uMesh < gModels[ uModel ].Mesh.GetNumMeshes(); ++uMesh )
{
for( UINT uMat = 0; uMat < gModels[ uModel ].Mesh.GetNumInfluences( uMesh ); ++uMat )
{
const D3DXMATRIX *pMat;
pMat = gModels[ uModel ].Mesh.GetMeshInfluenceMatrix(
uMesh,<
uMat );
D3DXMatrixTranspose(
&gModels[ uModel ].AnimatedBones[ uMesh ][ uMat ],
pMat );
}
}
}
リスト 2. AnimateModel タスク
アニメーション・タスクセットを実行するため、グローバルデータと現在表示されているモデル数を使用して OnFrameMove 関数でタスクセットを生成します。リスト 3 では、メインスレッドの実行時間を利用して残りのアニメーション・タスクを処理するために、OnD3D11FrameRender() の WaitForSet でタスクセット・ハンドル (ghAnimateSet) を使用しています。WaitForSet から戻ってきたときには、アニメーション・タスクセットは完了しているため、メインスレッドはそのデータを D3D に送ることができます。
OnFrameMove()
{
...
gTaskMgr.CreateTaskSet(
AnimateModel,
&gAnimationInfo,
guModels,
NULL,
0,
"Animate Models",
&ghAnimateSet );
...
}</p>
<p>OnD3D11FrameRender()
{
...
gTaskMgr.WaitForSet( ghAnimateSet );
...
}
リスト 3. アニメーション・タスクセットの生成
図 4 はサンプルプログラムの実行結果です。スライダーを使用してモデル数 (Model Count) を変更できます。また、[Enable Tasking (タスク処理を有効にする)] ボタンをオン/オフにして、シングルスレッドとマルチスレッドを切り替えることができます。
1 つのモデルを描画させた場合でも、メインスレッドでアニメーションを実行するより、タスク処理のほうが高速であることが分かります。[Force CPU Bound (CPU 制約を強制する)] をオン/オフにして、モデルの最初の三角形だけを描画し、プロセッサーに非常に大きな負担をかけるシナリオでタスク処理による効果を確認できます。
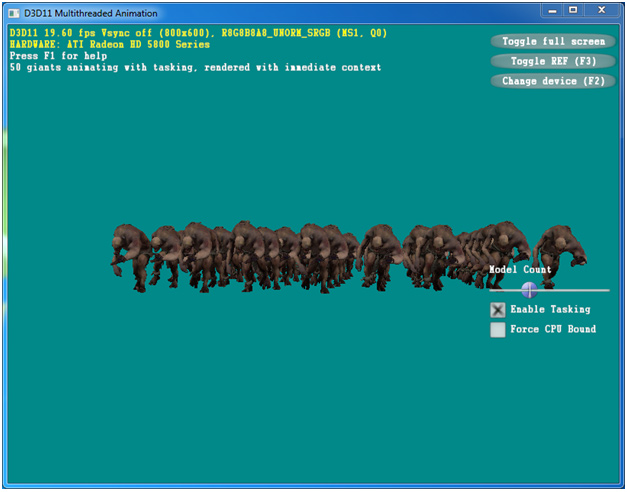
図 4. ATI Radeon* HD 5870 グラフィックスでのアニメーション・サンプルの実行結果
図 5 は、サンプルプログラムで描画するモデル数を増やした場合のパフォーマンス・コストを示します。このデータは、ATI Radeon* HD 5870 グラフィックスを搭載したインテル® Core™ i7 プロセッサー・ベースのシステムで収集したものです。この図から、特定のコア数に対してコードを変更することなく、描画オブジェクトの増加に対して効率良くスケールできていることが分かります。
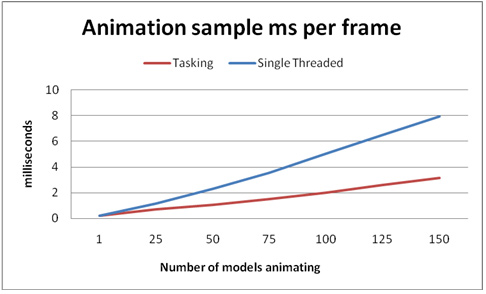
図 5. アニメーション・サンプルのパフォーマンス・データ(時間はミリ秒/フレーム単位で、 値が小さいほどハイパフォーマンス)
参考文献
[1] GDC 2011 におけるタスク処理のプレゼンテーション[2] インテル® スレッディング・ビルディング・ブロック (http://threadingbuildingblocks.org/)
ゲームタスクのホームページ
ホームページ: ゲームエンジンのタスク処理 - アニメーション (ソースコード、バイナリー、ビデオ)
http://software.intel.com/en-us/articles/game-engine-tasking-animation/
インテル® ソフトウェア製品のパフォーマンス/最適化に関する詳細は、最適化に関する注意事項 (英語) を参照してください。
