

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Comparative Performance of Game Threading APIs in Task Managers」 (http://software.intel.com/en-us/articles/comparative-performance-of-game-threading-apis-in-task-managers/) の日本語参考訳です。
概要
この記事では、マルチコア・プロセッサーのパフォーマンスをスケーリングする一般的なアプローチとしてタスク処理を紹介します。タスク・マネージャーの例では、インテル® スレッディング・ビルディング・ブロック (インテル® TBB)、Microsoft* 同時実行ランタイム、Windows* スレッドベースのカスタム・スケジューラーの 3 つのスケジューリング API を使用します。これらのタスク・マネージャーのパフォーマンスを、マルチコア・プロセッサーを搭載するシステムで 2 つのゲーム開発サンプル (Morphological Anti-Aliasing と Skeletal Animation [1,2]) の計算を実行して測定しました。3 つのバックエンドは同等に実行され、スケジューラーで使用する API に依存することなく、タスク処理によりパフォーマンスが向上していることが分かりました。
はじめに
近年のプロセッサーに搭載されている複数のコアを最大限に活用するため、いくつかのプログラミング・アプローチが開発されています。機能の並列化は、サブシステムまたは計算の種類ごとに、個別の、ほぼ独立したプロセシング・ユニットにプログラムを分割するアプローチです。プログラムで分割できるユニット数に上限があるため、このアプローチの効果には限界があります。例えば、ゲームエンジンの主要なシステム (レンダリング、物理計算、AI、入力、オーディオ) はすべて、別々のスレッドに分割できます。ただし、システム間で通信を行う処理が複雑になります。また、作業が各コアに均等に分散されるとは限りません。
別のアプローチは、fork/join と呼ばれるデータの並列化です。fork/join では、アルゴリズムを複数のコアで並列に実行できるようになるまでプログラムをシリアルに実行します。このアプローチでは、並列領域のパフォーマンスはシステムのコア数でスケーリングされますが、シリアル領域のパフォーマンスは向上しません。一部のゲームでは、このアプローチを粒子系やアニメーションの更新に採用しています。しかし、多くのプログラムとゲームでは fork/join を利用する機会が制限されるため、このアプローチによるパフォーマンスの向上にも限界があります。
これらの問題を解決する試みとして、タスク処理アプローチが開発されました。fork/join と同様に、タスク処理はコア数でスケーリングされますが、シリアルプログラムよりも頻繁に追加のコアを使用します。追加のコアが使用されるように、プログラムは複数のタスクに分割されてスケジューラーに渡されます。タスクがスケジューラーにサブミットされると、タスクをサブミットしたスレッドは、前に処理していた作業を継続するか、サブミットした作業を行うためスケジューラーに処理を明け渡すこともできます。すべてのタスクが互いに完全に独立するとは限らないため、同期ポイントが必要になります。
複雑な処理の管理が容易になるように、通常、スレッドを直接操作するのではなく、より高度なインターフェイスを提供する単純なタスク・マネージャーを記述します。この記事では、バックエンドのスケジューラーとしてインテル® TBB で記述した単純なタスク・スケジューラーのパフォーマンスを紹介します。パフォーマンスの比較と、タスク処理によるパフォーマンスの向上が特定のスケジューラー実装に依存しないことを示すため、Microsoft* の同時実行ランタイム (ConcRT) と Windows* のネイティブスレッド API を使用したカスタム・スケジューラーで記述した別のバックエンドのパフォーマンスについても紹介します。
タスク・マネージャーのインターフェイス

タスク・マネージャーのインターフェイスは、プログラムのタスクとスケジューラーとの唯一の通信方法です。TaskMgr クラスは生成を管理し、指定されたタスクセットが完了するまで待機する機能を提供します。インターフェイスは、タスクがほかの同様のタスクとともにサブミットされ、それらのタスクをセットとして追跡できるように作成されています。
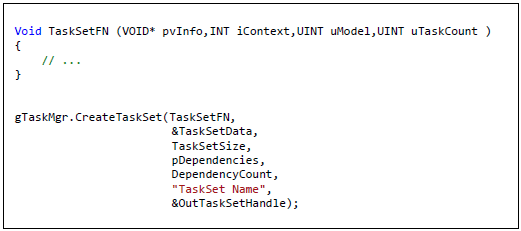
プログラムは、関数ポインター、データポインター、セットのタスクの数、任意の依存関係を TaskMgr に提供します。プログラムが提供する関数は、データポインター、タスクを実行するスレッドの ID、タスク ID、セットのタスクの総数、実行の前に完了する必要があるタスクセットを受け取ります。
スレッド ID とタスク ID を使用することで、ロックすることなく、タスクまたはスレッド固有のデータにアクセスできます。例えば、スレッド ID は、スレッド固有のレンダリング・コンテキストのアクセスやスレッド固有の統計情報の記録に使用できます。タスク ID は、タスクで必要な特定のデータのアクセスに使用できます。Multi-Threaded Animation サンプルは、タスク ID を使用して、更新するモデルを決定します。各タスクセットでそのタスクセットよりも前のセットからのデータが必要な Morphological Anti-Aliasing サンプルのようなケースでは、依存関係が必要です。[3]
TaskMgr は、生成されたときにタスクセットのハンドルをプログラムに渡します。プログラムは、このハンドルを使用して待機することで、タスクセットが完了したかどうかを判断します。タスクセットの完了まで待機することで、スレッドはそれ自身の処理をスケジューラーに譲り渡し、スケジューラーはそのセットが完了するまでタスクの実行を行います。
インテル® TBB で記述したタスク・マネージャー
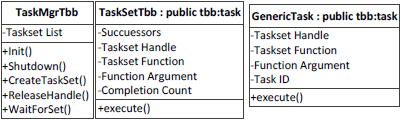
インテル® TBB は、タスクの生成とサブミットに継承ベースのインターフェイスを使用します。すべてのタスクは tbb::task クラスを継承します。このクラスは、タスクの現在の状態や現在割り当てられているスレッドなど、インテル® TBB が必要とするすべての情報を保持します。継承により、プログラムは同様にタスクで必要なすべての情報を格納できます。
タスクセットを管理するため、TaskMgr クラスは TaskSet インスタンスを記録します。TaskSet クラスは、生成関数に渡されたすべてのデータ、依存する TaskSet のリスト、完了したタスクの数を格納します。TaskSet はスケジューラーにタスクをサブミットする準備が整うと、GenericTask インスタンスをスポーンします。GenericTask は、個々のタスクの実行に必要な情報 (関数ポインター、データポインター、タスク ID、タスクセットのサイズ、親 TaskSet へのハンドル) をすべて格納します。インテル® TBB に渡されるタスクとして、GenericTask は tbb::task から派生します。
スケジューラーにスレッドの処理を明け渡したり、すべての GenericTask が完了したときに通知を受けるためにインテル® TBB の待機機能を利用するには、TaskSet も tbb::task から派生する必要があります。tbb::task から TaskSet を派生させることで、TaskSet のインスタンスを、スポーンする GenericTask の親タスクとして設定できます。インテル® TBB では、TaskSet は子の GenericTask が完了するまで完了しない tbb::task です。

Microsoft* 同時実行ランタイムで記述したタスク・マネージャー
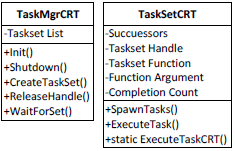
同時実行ランタイム (ConcRT) は、タスクの生成にインテル® TBB とは異なるアプローチを採用しており、 関数インターフェイスを使用します。タスクは、関数ポインター、関数オブジェクト、またはラムダ関数としてサブミットされます。タスクの生成とサブミットには task_group オブジェクトを使用します。task_group は受け取った関数をスケジューラーに渡し、プログラムは task_group を使用してタスクの状態を照会します。[4]
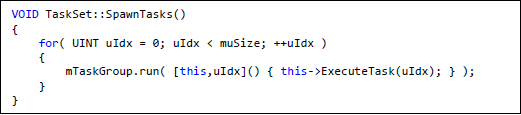
タスクがオブジェクトの代わりに関数としてサブミットされると、GenericTask クラスは必要なくなります。代わりに、GenericTask::Execute メソッドは TaskSet クラスに統合され、タスクは新しいメソッドを呼び出すラムダ関数としてサブミットされます。ラムダ関数は本体のみで名前のない匿名関数です。これらの関数は別の関数の本体で定義されるため、生成関数のデータと変数をキャプチャーできます。この機能は、TaskSet のポインターと実行するタスクの ID の両方をキャプチャーするために使用されます。この機能により、ロックやアトミック操作を行うことなく、各タスクが一意の ID を持つことができます。
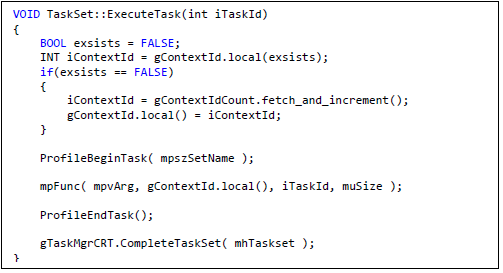
インテル® TBB と異なり、ConcRT は新しいワーカースレッドが生成されたときにカスタムコードを実行するインターフェイスを提供していません。このため、ユーザーが提供するタスク関数において範囲 [0,n) (n はハードウェア・スレッド数) 内の一意のスレッド・コンテキスト ID が必要な場合に問題が発生します。スレッドの生成時に ID を取得するためにコードを実行できないこの問題を回避するため、コードは TaskSet::ExecuteTask メソッドに配置しました。
Windows* スレッドで記述したタスク・マネージャー
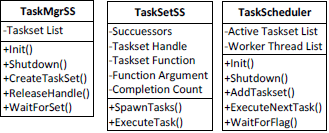
インテル® TBB や ConcRT を使用した、タスクのスケジューリングを制御するバックエンドとは異なり、Windows* スレッド・バックエンドではカスタム・スケジューラーが必要です。TaskSet で扱えるため、ConcRT バックエンドからは、個々のタスクを操作するクラスは必要ないようでした。Windows* スレッド・バックエンドでは、このアイデアが一歩進められ、スケジューラーは個々のタスクでのサブミットは受け付けず、タスクセットでのサブミットのみ受け付けます。タスクセットを個々のタスクに分割できないため、結果として、単一のワークキューがすべてのワーカースレッドで共有されます。ワークキューは、オーバーヘッドを最小限に抑え、複数のリーダーやライターで利用可能なデータ構造にする必要があります。例では、配列 TaskSetHandle を使用しています。リーダーとライターは、各スレッドが現在対話しているスロットと対応する ID を保持します。
待機時間を短縮するため、各スレッドには固有のリーダーがあります。配列は循環バッファーとして扱われます。リーダーが配列の最後に到達すると、配列の先頭から再度検索を開始します。未完了のタスクセットが見つかると、スレッドはタスクセットの内部カウンターをインクリメントしてタスクを実行します。TaskSet が完了すると、スレッドはスロットを空としてマークし、次の TaskSet を処理します。
ライターも各スレッドに固有です。新しいセットが追加されるたびにスレッドが配列全体を検索するのを防ぐため、スケジューラーは最後に書き込まれた位置を記録します。そして、書き込むスレッドはその位置から開始して、空のスロットが見つかるまで検索します。空のスロットが見つかると、ほかのスレッドがそのスロットに書き込んでいないことを保証するため、アトミックに compare-and-exchange が行われます。

タスク・スケジューラーは、実行できるタスクセットの総数を記録します。新しいタスクセットがワークキューに追加されると、この数が最初にインクリメントされます。この処理により、新しい作業を開始する直前にスレッドがスリープしないことが保証されます。タスクセットのカウンターがゼロになると、スレッドはセマフォーで待機します。新しいタスクセットがワークキューに追加され、作業の処理に必要な数のスレッドが起動すると、セマフォーはリリースされます。別のアプローチは、Windows* イベントの作業がないときにスレッドを休止する方法です。新しいタスクセットがキューに追加されたときに誤ってイベントが設定またはリセットされないことを保証するため、ロックが必要になります。このため、セマフォーを代わりに使用しました。
パフォーマンスの比較
3 つのタスク・マネージャーのバックエンドすべてを同じインターフェイスにすることで、バックエンドを容易に交換して比較できます。マルチコアのパフォーマンス・スケーリングを比較するため、2 ~ 6 コアのシステムで Morphological Anti-Aliasing および Multi-Threaded Animation サンプルを実行したときのタスク・マネージャーを比較した結果を次に示します。2 コアおよび 4 コアのシステムではインテル® Core™ i7 Extreme 965 (2 コアのシステムでは 4 コアのうち 2 コアを無効に設定)、6 コアのシステムではインテル® Core™ i7 Extreme 980 を使用しました。
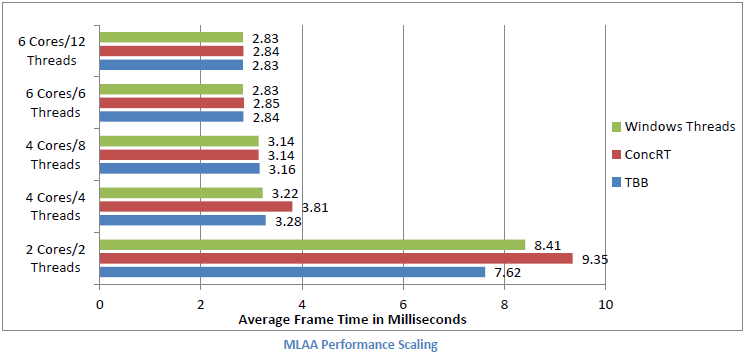
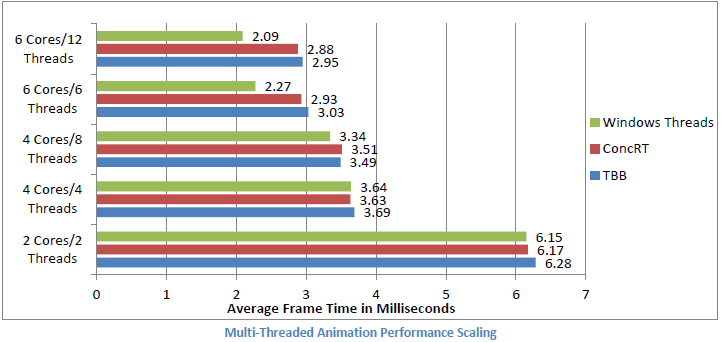
これらの結果から、タスク処理が近年のマルチコア・プロセッサーにおけるパフォーマンス・スケーリング・テクニックとして価値があることが分かります。アニメーションの例は、3 つのタスク・マネージャーのパフォーマンスが 2 コアから 4 コアで平均 43%、4 コアから 6 コアで平均 25% 向上していることを示しています。MLAA の例は、パフォーマンスが 2 コアから 4 コアで平均 60%、4 コアから 6 コアで平均 20% 向上していることを示しています。また、特定のスレッド API を使用することがタスク処理によるパフォーマンスの向上にあまり影響していないことも分かります。
結果からは、パフォーマンスの向上率がワークロードに依存して変わることも判明しました。アニメーションの例は、依存関係のない多くの小さなタスクで構成されています。この結果、特にインテル® TBB と ConcRT で、スケジューラーのオーバーヘッドが増えていることが分かります。これらのスケジューラーはどちらも、ワークスチール・アルゴリズムを使用してワーカースレッド間のワークロードのバランスを取っていますが、 このアルゴリズムは、より大きく、不規則なタスクを制御するときに最適な手法です。一方、MLAA は依存関係によって制限されます。イメージを水平に処理するために 2 つ、イメージを垂直に処理するために 2 つ、合計 4 つのタスクセットが使用されます。正しい結果を得るためには依存関係が必要ですが、セット間ではワーカースレッドがアイドル状態になります。
サンプルの更新
Morphological Anti-Aliasing および Multi-Threaded Animation サンプルは、オリジナルのインテル® TBB ベースの TaskMgr API を使用して記述されていました。代替バックエンドは同一 API を使用するように記述されていたため、1 つの定数を変更することで、コンパイル時にマネージャーを切り替えていました。ここでは、異なるスケジューラーの実装を比較しやすくするため、スケジューラーをランタイムに変更できる機能を実装しました。この機能を実装するため、2 つの小さな変更を行いました。1 つ目の変更は、TaskMgr にスタティック・グローバル変数でアクセスせずに、TaskMgr のポインターを代わりに使用しました。2 つ目の変更は、3 つの TaskMgr クラス実装のインターフェイスをすべて、ポインターでアクセスできるようにしたことです。コンパイル時にバックエンド・スケジューラーを切り替えていたときにはなかった API への仮想関数呼び出しが行われるため、オーバーヘッドはわずかに増えます。
参考文献 (英語)
- Morphological Anti-Aliasing (http://software.intel.com/en-us/articles/mlaa/)
- Multi-Threaded Animation (http://software.intel.com/en-us/articles/game-engine-tasking-animation/)
- Using Tasking to Scale Game Engine Systems (http://software.intel.com/en-us/articles/using-tasking-to-scale-game-engine-systems/)
- Microsoft Concurrency Runtime (http://msdn.microsoft.com/en-us/library/dd504870.aspx)
著者紹介
James Lenell: プラットフォーム・アプリケーション・エンジニアリング部門のソフトウェア・エンジニア・インターンで、 現在、デジペン工科大学でリアルタイム・インタラクティブ・シミュレーションの学士課程に在籍しています。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
