


この記事は、インテルの The Parallel Universe Magazine 33 号 (英語) に収録されている、インテル® VTune™ Amplifier のアプリケーション・パフォーマンス・スナップショット (APS) を利用してハードウェアを効率良く使用する方法を紹介した章を抜粋翻訳したものです。
ハイパフォーマンス・コンピューティング (HPC) システムは、ハードウェア・コンポーネントの複雑な組み合わせであると言えます。ハードウェア・ベンダーは、計算集約型アプリケーションのパフォーマンスを向上するため、スピードアップ、レイテンシーの軽減、コアの追加、ベクトル幅の拡張に常に取り組んでいます。しかし、単により優れたコンポーネントを備えたシステムでアプリケーションを実行するだけでは、それらのコンポーネントが効率良く使用される保証はありません。期待するパフォーマンス向上を達成するため、コード変更 (コードを対応させること) が必要になることがあります。
幸いにも、インテル® Parallel Studio XE には、インテル® ハードウェア上でコードのチューニング作業を支援するツールが含まれています。どのツールから使用すべきか迷った場合は、インテル® VTune™ Amplifier のアプリケーション・パフォーマンス・スナップショット (APS) を使用することで、アプリケーションのパフォーマンス特性、特にパフォーマンスを制限しているボトルネックのサマリーを素早く取得できます。アプリケーション・パフォーマンス・スナップショットは、クラスター、ノード、コアレベルのパフォーマンスのチューニングに適切なインテル® Parallel Studio XE ツールを選択するのにも役立ちます (図 1)。
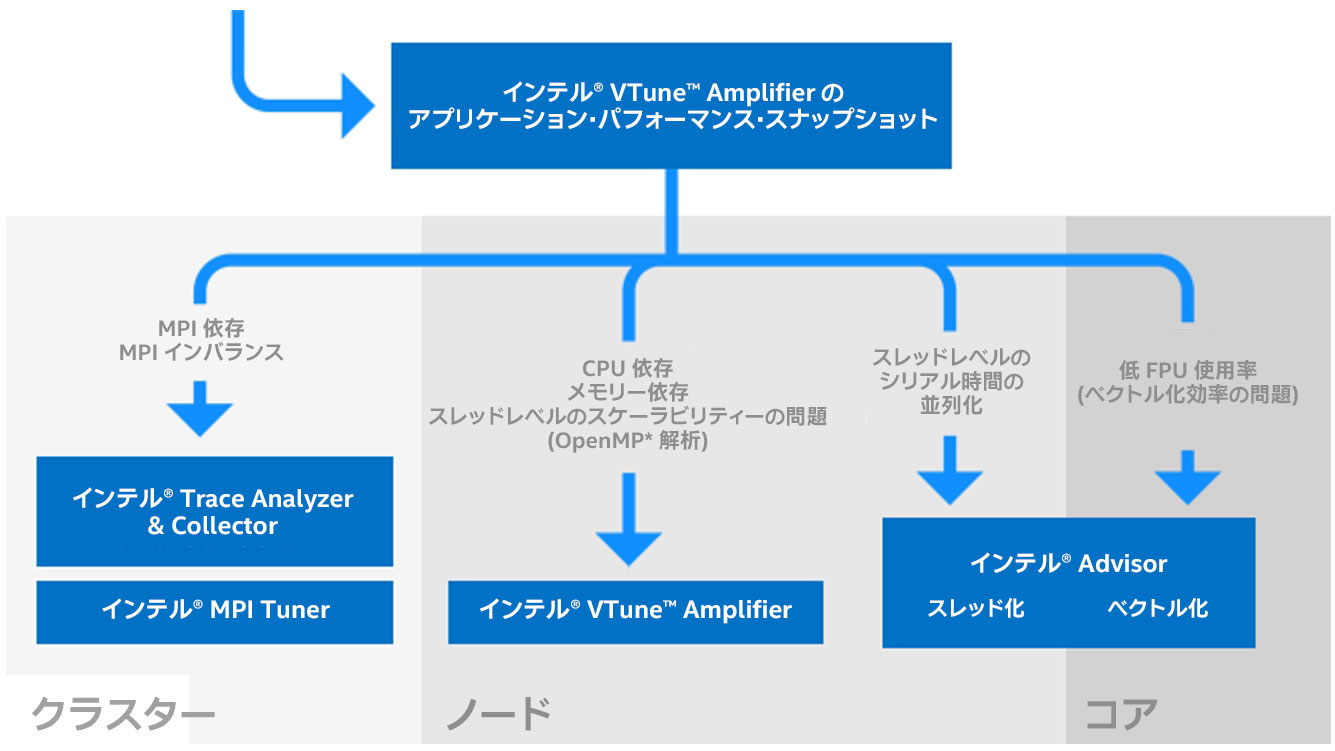
1. APS と専用のパフォーマンス・ツール
ISO3DFD: 波動伝播カーネルとパフォーマンス測定
サンプルコードを使用して、ボトルネックの発見とパフォーマンスの向上にツールがどのように役立つかを見てみましょう。ISO3DFD は、等方性音波方程式を実装します。
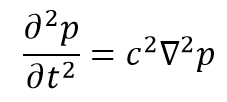
ここで、∇2 はラプラス演算子、p は圧力場、c は速度場です。有限差分は、pt と pt-1 の関数として pt+1 を表現するために使用できます。有限差分伝播カーネルは、ステンシルパターンを利用して実装できます。3 次元では、ステンシルは圧力場を横切って移動する 3D クロスのように見えます。つまり、pt+1[x,y,z] を更新するには、pt[x,y,z] のすべての近傍に 3D でアクセスする必要があります。図 2 は、2D のステンシルパターンです。
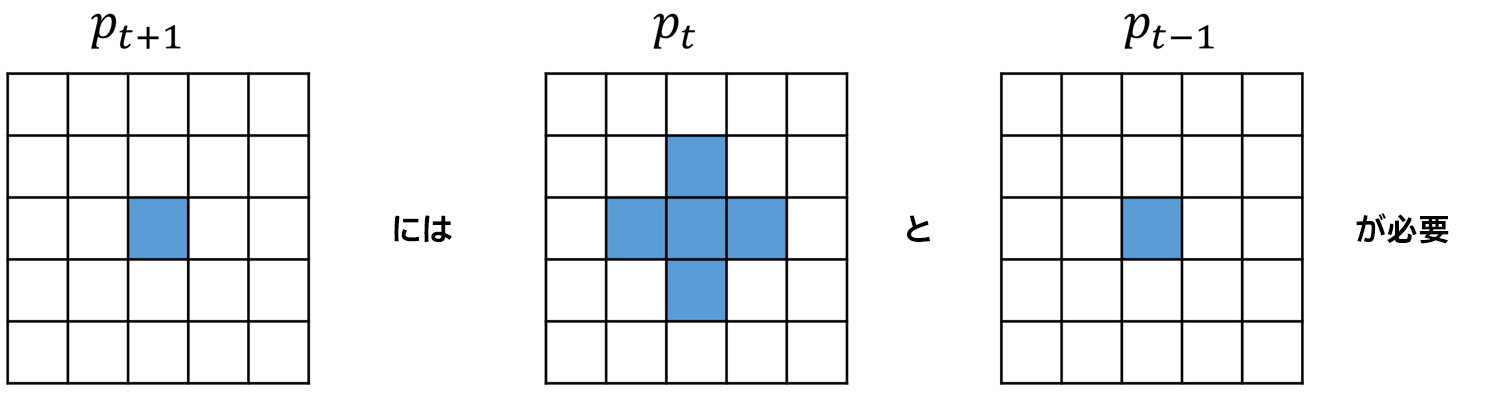
2. 2D ステンシルパターン
実際のアプリケーションでは、物理学者は通常コーナーケース用に特定の伝播手法を実装します。これらのコーナーケースは、境界条件と呼ばれます。ここではコードを簡潔にするため、境界に波を伝播しません。図 3 の単純な実装は、ステンシルの単一の反復を計算します。
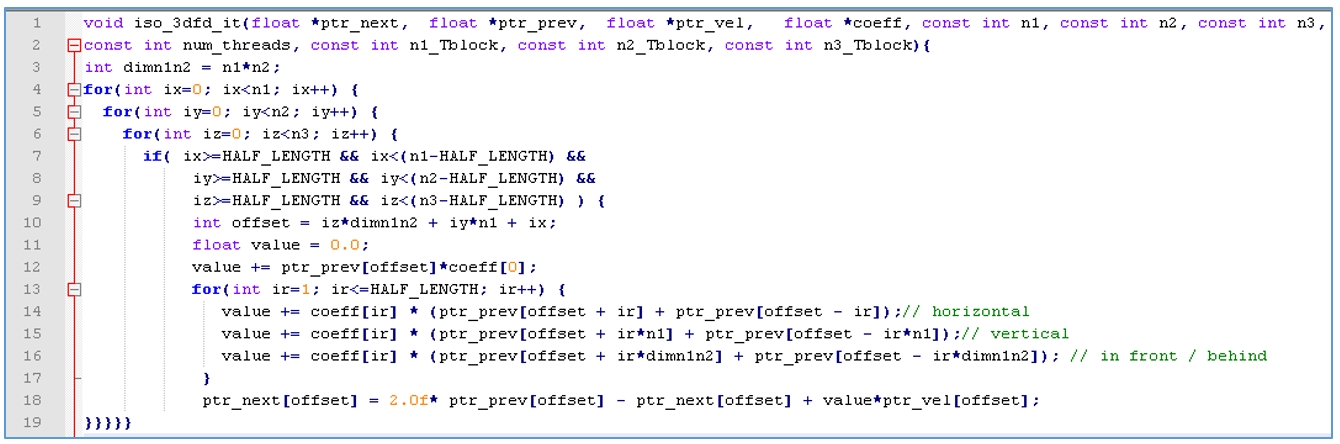
3. ステンシルの単一の反復の計算
この記事では単一ノードのパフォーマンスに注目するため、サンプルコードは MPI を使用してクラスターレベルの並列処理を実装していません。
ベースライン・パフォーマンスを確立するため、デュアルソケットのインテル® Xeon® Gold 6152 プロセッサー (2.10GHz、22 コア/ソケット) を搭載した Red Hat* Enterprise Linux* Server 7.4 システム上で、512 x 400 x 400 グリッドで初期実装を実行してベンチマークを測定しました。次のコマンドを使用して、インテル® Parallel Studio XE 環境を設定します。
> source <Parallel_Studio_install_dir>/psxevars.sh
そして、インテル® VTune™ Amplifier のアプリケーション・パフォーマンス・スナップショットを使用して、ISO3DFD 初期実装のチューニングの可能性を素早く見つけます。次のコマンドで APS を起動します。
> aps ./Iso3DFD
