

この記事は、インテル® デベロッパー・ゾーンに公開されている「How to profile MPI processes on all nodes?」(https://software.intel.com/en-us/blogs/2015/05/26/how-to-profile-mpi-processes-on-all-nodes) の日本語参考訳です。
インテル® VTune™ Amplifier XE 2015 は、クラスターシステム上のハイブリッド MPI プロセスを解析することができます。これは、N 個のランクのシステム上でインテル® VTune™ Amplifier XE が MPI プログラムを実行し、最も CPU 時間を消費するランクのホットな関数を特定するため、パフォーマンス・データを収集することを意味します。
最初にインテル® Parallel Studio XE 2015 Cluster Edition で提供されるツールの環境を設定します (次に例を示します):
インテル® コンパイラー XE
$ source /opt/intel/ics/2015.0.3.032/composer_xe_2015/bin/compilervars.sh intel64
インテル® MPI ライブラリー
$ source /opt/intel/ics/2015.0.3.032/impi_latest/bin64/mpivars.sh
インテル® MPI ライブラリーのバージョンが 5.0.2 以降であることを確認してください。
インテル® VTune™ Amplifier XE
$ source /opt/intel/ics/2015.0.3.032/vtune_amplifier_xe_2015/amplxe-vars.sh
MPI プログラムをプロファイルするには、従来の 2 つの方法があります。以下に例を示します:
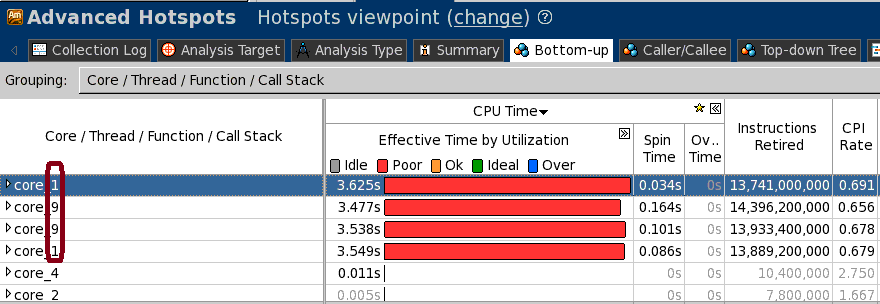
インテル® VTune™ Amplifier XE は、単一ノード (2 論理コア) 上で MPI プロセスを実行
amplxe-cl -c advanced-hotspots -r result_1 — mpirun -n 4 ./poisson.x -n 2000
単一の結果 result_1 のみを生成。シングルコア上の 2 コアの結果が格納されています。
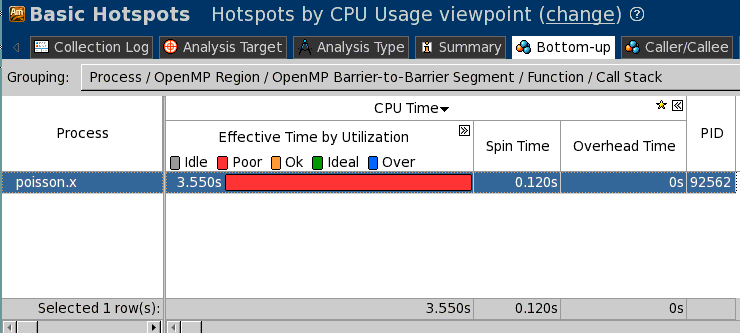
インテル® VTune™ Amplifier XE は、複数のノード上で MPI プロセスを実行
$ mpirun -n 4 amplxe-cl -c hotspots -r result_2 — ./poisson.x -n 2000
4 つの結果 result_2.0 ….. result_2.3 を生成。ここでは 4 つのレポートの 1 つを示していますが、通常は 4 つをすべて確認する必要があります。
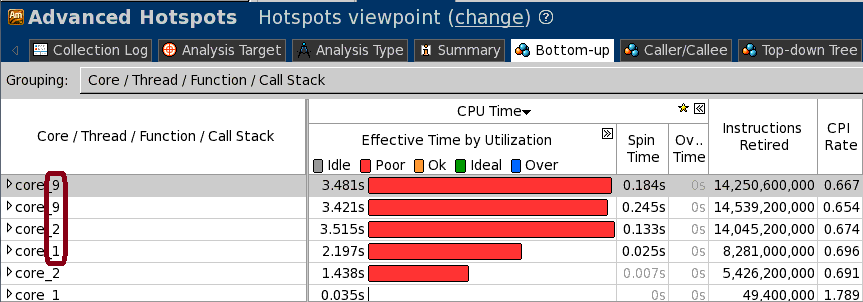
すべてのノードのすべてのランクのパフォーマンス・データを収集するため、新しいオプションが追加されました。次に例を示します:
$ mpirun -gtool “amplxe-cl -r result_3 -collect hotspots:all=node-wide” -n 4 ./poisson.x -n 2000
単一の結果 result_3.$hostname のみが生成されます。複数ノードで MPI プロセスが動作していることを確認してください。この方法の利点は、すべてのノードの結果を 1 度に確認できることです (ノード 1 のコア 1,9、他のノードのコア 2 のように)。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください
