

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「3D Finite Differences on Multi-core Processors」(http://software.intel.com/en-us/articles/3d-finite-differences-on-multi-core-processors/) の日本語参考訳です。
はじめに
この記事では、多次元有限差分のステンシルを実装する差分最適化手法について説明します。インコアの最適化、つまりデータアクセスのパフォーマンスを向上させるデータ形式とアプローチ、 NUMA 対応のデータ配置による領域分解について説明します。また、並列プログラミング・モデルの使用例を紹介します。ここでは、ハードウェア・ベクトル・レジスターのプログラミング・サポートから並列プログラミング・モデルまで、インテル® ソフトウェア・ツールのさまざまな機能を利用します。
目次
マルチコア・プロセッサーにおける 3 次元有限差分法の実装
はじめに
1 概要
2 インコアの最適化
2.1 概要
2.2 コンパイラー・オプション
2.3 インテル® SSE/AVX プログラミング
3 データアクセス向上のためのデータ形式と最適化
3.1 データ形式
3.2 キャッシュ・ブロッキング
4 問題の分解と NUMA 対応のデータ配置
5 共有メモリーの並列化
6 引用文献
著者紹介
著作権と商標について
最適化に関する注意事項
1 概要
差分ステンシルは通常、偏微分方程式 (PDE) を解く際に反復有限差分法で利用されます。正則グリッドでは、ステンシル計算は時間と空間の両方で隣接するポイントの部分集合から明確に定義された加重により求められます。3 次元配列 v[i,j,k] = vi , j, k に適用される次数 O の 3 次元空間ステンシルは、次のように定義できます。
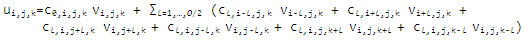
このステンシルは、(3*O+1) ポイントステンシルとも呼ばれます。ここでは、対称定数係数が cl = cl, i, j, k (i,j,k=1,…,O/2) で次数 8 の 3 次元有限差分 (FD) ステンシルを使用した最適化手法について説明します。単精度データ型を想定していますが、より汎用的なケースや他のステンシル形式にも拡張できます。
(3*8+1)=25 ポイントステンシルは、図 1 のように表すことができます。計算上は、配列 V と係数配列 C に基づいて配列 U を更新する、i,j,k の 3 重の入れ子のループとして集約できます。

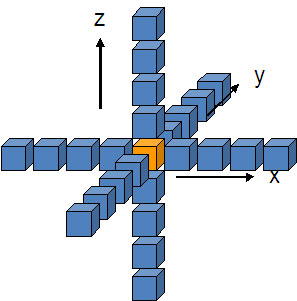
図 1: 25 ポイントステンシル。中央のセル (オレンジ) の新しい値は、すべての隣接セル (青) の値の加重和によって得られる。
通常、ステンシルが適用されるデータ構造 (配列) はプロセッサーのデータキャッシュよりも大きくなります。単純な実装では、i±r で定義される fast (ユニットストライド) 方向の隣接するポイント V[i±r, j, k] (r<=O/2) にのみアクセスするため、データの再利用が制限されます。データがすでにキャッシュにある場合でも、ステンシル形状の外部の要素であれば、その要素は再利用されません。データが再利用されない場合、メインメモリーへのアクセスが増加し、パフォーマンスが低下します。
データが効率良く再利用されるように、ここでは、NUMA、メモリー階層、SIMD 拡張命令などの、インテル® Xeon® プロセッサー・ファミリーの機能を活用してステンシル計算を実装します。
基準コード: 次のように、次元 dx*dy*dz の配列 v から配列 u までの、次数 8 の 3 次元有限差分計算のより簡単なケースについて考えてみましょう。

図 2: 次数 8 の 3 次元有限差分の基準コードと対称定数係数
2 インコアの最適化
2.1 概要
インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) は、データセットの異なる要素で同じ演算を実行する、計算集約型のアプリケーションのパフォーマンスを向上させます。単精度の場合、同じクロックサイクルで 4 つのパックド単精度浮動小数点値に対して演算を行う SIMD (Single Instruction Multiple Data) 並列処理を行うことによりパフォーマンスが向上します。
図 1 のステンシルで、メモリー内で要素が連続しているのは X 方向のみです。図 2 の基準コードで示されているように、Y 方向のストライドは dx で、Z 方向のストライドは dx*dy です。これは、浮動小数点 v[ix± k*dx] と v[ix±k*dx*dy] (k=1,..,4) がそれぞれ別のキャッシュラインに属していることを意味します。SIMD を利用したベクトル化を行わない場合、単一のステンシル計算では各キャッシュラインの 1 つの浮動小数点値のみにアクセスするため、4*4=16 のキャッシュラインが十分に利用されません。
図 3 は、19 個の SSE レジスターを使用して 4 つのステンシルを同時に計算している様子を図で表したものです。少なくとも 4 つの浮動小数点要素が各キャッシュラインからロードされ、12 個の浮動小数点要素が X 方向の要素を保持するキャッシュラインに属しています。
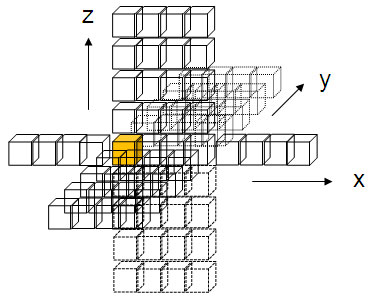
図 3: インテル® SSE のレジスター・ブロッキングを使用して 4 つのステンシルを同時に計算します。
上記の完全にベクトル化されたステンシル計算で必要な SIMD レジスター数の予測から、ループ分割を行うようにコードを変更しました。ループ分割は、コードで必要なレジスター数を減らすために、1 つのループを複数のループ (各ループはより少ない計算量) に分ける最適化です。x、y、z 方向のループのステンシル計算をそれぞれ分割することで、再構成後の各ループを完全に並列化するのに必要な SIMD レジスター数は元のループよりもかなり少なくなります。図 4 は、ループ分割の例です。インテル® コンパイラーでは、プラグマ #pragma nofusion を使用してループ単位でループ融合を無効にすることができます。
2.2 コンパイラー・オプション
インテル® コンパイラーは、自動ベクトル化をサポートすることにより、インテル® SSE を活用する最も容易で迅速な方法を提供します (1)。最初のステップは、ベクトル化に適したコンパイラー・オプションを選択することです。この例では、次のコンパイラー・オプションを追加しました。
-O3 -xHOST -ip -ansi-alias -fno-alias -openmp -vec-report3
“-O3 -xHOST” を追加すると、コードをコンパイルしたシステムのプロセッサーと互換性のあるインテル® SSE に対応したコードが生成されます。“-vec-report3” オプションを追加すると、ベクトル化を妨げるデータの依存関係情報を含む、ベクトル化されたループ、ベクトル化されなかったループに関する診断情報が出力されます。この情報により、さらなるベクトル化が可能なコード領域を特定できます。
インテル® コンパイラーには、ガイド付き自動並列化 (GAP) ツールも用意されており、コードをベクトル化するために必要な、コンパイラー・オプションの追加、ループへのプラグマの挿入、ソースコードの変更についてアドバイスを提供します (2)。この記事で追加した “-ansi-alias -fno-alias” オプションは、C/C++ コードにエイリアスされたポインターがなく、ベクトル化が安全であることをコンパイラーに通知します。別の方法は、関数定義で C99 の型修飾子 restrict を使用することです。“-ip” オプションは、可能な場合にプロシージャー間の最適化を行います。コンパイラーの最適化オプションの詳細は、(3) を参照してください。
例えば、計算ループの前に #pragma ivdep を挿入してコンパイラーに指示することで、レジスター間の自動ベクトル化とメモリーアクセスの動作を向上させることができます。このプラグマを挿入すると、コンパイラーが仮定したデータ依存性が無視されるため、より多くのループでベクトル化が行われる可能性があります。

図 4: インテル® SSE のベクトル化で使用されるレジスター数を減らすためにループを分割します。
2.3 インテル® SSE/AVX プログラミング
より積極的な方法は、インテル® SSE 命令を直接使用して、ベクトル化されたループをプログラムすることです。色々な方法がありますが、最も手間がかかるのは、アセンブラーで直接プログラムする方法です。コンパイラーがサポートする組込み関数を利用する方法もあります。これは、インテル® SSE を容易にコーディングし、同じソースコードでハードウェア・レベルのインテル® SSE 命令と高水準の C/C++ 命令を組み合わせることができます (4)。
その他の移植性に優れた簡単な方法として、インテル® C++ SIMD クラスと新しい配列構文 (CEAN) 拡張を利用する方法があります。
インテル® C++ SIMD クラスは、配列 (ベクトルデータ) を並列に処理できます。整数ベクトル (Ivec) クラスと浮動小数点ベクトル (Fvec) クラスをサポートしており、クラスの名前は、行う演算の種類に基づいています。例えば、F32vec4 は 4 つのパックド 32 ビット浮動小数点データ (SSE) の演算を行い、F32vec8 は 8 つのパックド 32 ビット浮動小数点データ (AVX) の演算を行います。標準の演算子は、+、+=、-、-=、*、*=、/、/= です。高度な演算子には、平方根、逆数、平方根の逆数があります。
Nehalem と Westmere プロセッサーでは、アラインされていない SIMD ロードとストア命令のペナルティーは、アラインされている場合と比較してそれほど大きなものではありませんが、可能な場合は 16 バイトでアラインされたロードとストア命令を使用することを推奨します。Sandy Bridge/AVX では、可能な場合は 32 バイトのアライメントを推奨します (5)。コードサンプルでは、メインループで配列 v および u のアラインされたアドレスからインテル® SSE 命令を発行できるように、事前ループを追加しています。
図 5 は、F32vec4 クラスを使用して y 方向のループにインテル® SSE のベクトル化を実装する例を示しています。整数値 align_offset は、配列ポインターを 16 バイト境界にアラインする事前ループから取得した配列インデックスです。つまり、vec_v と vec_u はそれぞれ、アラインされたメモリーアドレス v+align_offset と u+align_offset のポインターです。vec_v の配列要素を 1 つ進めることは、配列 v の配列要素を 4 つ進めることと同じです。ループの反復回数 vec_loop_trip とストライド vec_dx は、元のスカラーバージョンの dx-4 と dx の 1/4 になります。各定数係数 ci について、コンストラクター F32vec4 は ci の 4 つの同じコピーを vec_ci にパックします。

図 5: C++ クラスを使用してループにインテル® SSE のベクトル化を実装します。インテル® SSE レジスターループ内の算術演算はそれぞれ、4 つの単精度スカラー演算と等価です。F32vec8 クラスを使用した同様の AVX コードでは、8 つの単精度スカラー演算を計算できます。
これらのクラスを利用するインテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) のような新しいハードウェア言語拡張に容易に移行することもできます (6)。インテル® AVX は、Sandy Bridge プロセッサー・ファミリーの一部として追加される、インテル® SSE の新しい命令セットの拡張で、より幅の広いベクトル、新しい拡張可能な構文、豊富な機能により、パフォーマンスを向上させます。新しい 256 ビット命令セットでは、インテル® SSE の 128 ビット命令セットの倍の幅の SIMD レジスターを使用します。実際に、図 3 のレジスターはインテル® AVX では 2 倍の幅になっています。
バージョン 11.1 以降のインテル® コンパイラーは、インテル® AVX SIMD のコード生成と C++ クラスをすでにサポートしています。開発者は、今までどおり、インテル® C/C++/Fortran コンパイラーの自動ベクトライザーを使用してインテル® AVX のベクトルループを生成できます。また、F32vec4 から F32vec8 クラスに変更してアライメントを 32 ビットにすることで、サイクルごとに 8 つのパックド 32 ビット浮動小数点演算を行うように図 5 の 3 次元有限差分コードを更新することもできます。これらのインテル® AVX クラスは、インテル® コンパイラーで提供されるインクルード・ファイルに定義されています。
明示的なベクトル化を実装する別の方法としては、インテル® Cilk™ Plus の配列表記 (アレイ・ノーテーション) を活用することです (7)。これらの C/C++ 拡張を利用すると、次の構文を使用して、ソースコードで直接配列セクションを表現することができます。
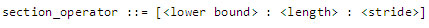
図 5 のコードを明示的に拡張して配列表記でベクトル化した AVX バージョンは、図 6 のように記述できます。このサンプルでは、__assume_aligned() と __assume() 宣言を使用してインテル® コンパイラーにデータ・アライメント情報を伝える方法についても示します。
__assume_aligned(u,32) および __assume_aligned(v,32) 宣言は、配列 u と v の基本アドレスが 32 バイトでアラインされることを示しています。型の宣言 __assume( %8 == 0) は、整数スカラー が 8 の倍数であることを示しています。v[ix] のアドレスが 32 バイトでアラインされる場合、v[ix+ ] のアドレスのオフセットも 32 バイトでアラインされます。__assume() および __assume_aligned() 宣言を使用すると、アライメント情報がコンパイラーに伝えられ、コード生成が最小限に抑えられますが、これらの宣言の使用は必須ではないことに注意してください。
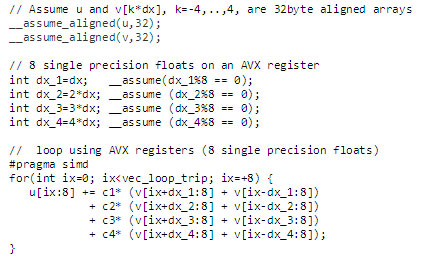
図 6: インテル® Cilk™ Plus の配列表記を使用してループにインテル® AVX のベクトル化を実装します。インテル® AVX レジスターループ内の算術演算はそれぞれ、8 つの単精度スカラー演算と等価です。必須ではありませんが、アライメントされていると仮定すると、コンパイラーのコード生成が最小限に抑えられます。
3 データアクセス向上のためのデータ形式と最適化
3.1 データ形式
有限差分法によって偏微分方程式 (PDE) を解く場合は、多くの 3 次元データ配列にアクセスして出力値 ui,j,k を計算します。少なくとも元の入力配列 vi,j,k とステンシルの隣接する値 vi±l,j±m,k±n が、演算の特性により定義された適切な係数 ci±l,j±m,k±n と組み合わされます。データは、隣接する浮動小数点の配列に格納されます。このレイアウトはベクトル化も考慮しています。欠点は、複数の配列を扱う計算で、データの局所性を高める工夫が必要になることです。
3.2 キャッシュ・ブロッキング
HPC アプリケーションにおけるアクティブなデータセットは、プロセッサーのキャッシュサイズよりも大幅に多くなります。データ・ブロッキングによって、空間と再利用できるデータを増やすことができます。データは、システムで利用可能なコア/スレッド数およびデータキャッシュのサイズに基づいて分割するべきです。データ・ブロッキングは、多くの方法で、さまざまなレベルで実装できます (例えば、コア・ブロッキングやキャッシュ・ブロッキング)。同時マルチスレッディング (SMT) が有効な場合、すべての物理コアに 2 つのスレッドがあります。この場合、スレッド・ブロッキングとコア・ブロッキングの実装は異なります。
図 7 では、サイズ CX × CY × CZ のサブブロックで元の dx × dy × dz データ配列にキャッシュ・ブロッキングを実装してアクセスしています。目標は、最上位レベルのキャッシュ・データ・ミスが最小限になり、データが最大限に再利用される大きさのキャッシュ・ブロッキングを定義することです。スレッド・ブロッキングは、キャッシュブロックをより小さなサブブロック (スレッドブロック) に分割して、キャッシュブロックが属するプロセッサー・コア内のスレッドをスケジュールする処理です。この記事の実装では、キャッシュ・ブロッキングとスレッド・ブロッキングを同じものとして扱いました。レジスター・ブロッキングは、SIMD データの並列処理で説明します。CX × CY × CZ キャッシュ・ブロッキング手法を図 7 に示します。

図 7: 3 次元ブロッキングの概要。CX、CY、CZ は、ハードウェアのキャッシュ構造に基づくブロッキング定数です。
パフォーマンスの観点から、ユニットストライドな 1 次元 x のブロッキングは、内側のループでベクトル化が可能な大きさでなければなりません。
キャッシュ制御により、開発者はプログラムのデータフローを応用できます (5)。特に、非テンポラルなストリーミング・ストアは、プロセッサー・キャッシュへの書き込みによるストアの帯域幅が増加する可能性があるため、近い将来再びアクセスされないデータによるキャッシュミスを最小限に抑えるようにします。キャッシュライン内に収まるように 64 バイトが連続して書き込まれている場合、ストリーミング・ストアを使用できます。デフォルトでは、インテル® コンパイラーはそれぞれの配列にストリーミング・ストアを使用するかどうかを自動的に決定します。開発者は、図 8 で示すように、VECTOR NONTEMPORAL プラグマを定義して、一時的でない (ストリーミング) ストアを使用するようにコンパイラーに指示することができます。

図 8: プラグマを使用して配列 u に一時的でない (ストリーミング) 操作を使用するようにコンパイラーに指示します。
インテル® 64 および IA-32 プロセッサーのアーキテクチャーとプログラミング環境についての詳細は、(8) を参照してください。
4 問題の分解と NUMA 対応のデータ配置
インテル® マイクロアーキテクチャー Nehalem 以降のマルチプロセッサー・システムは、NUMA (NonUniform Memory Access) アーキテクチャーに基づいています。プロセッサーは、自身のローカルメモリーまたは別のプロセッサー・ソケットに物理的に配置されているリモートメモリー (つまり、別の NUMA ノード に配置されている物理メモリー) にアクセスすることができます。利用可能な共有メモリーの合計は、システムに含まれるすべての NUMA ノードのメモリーの総計です。局所性問題: リモートの NUMA ノードのメモリーのアクセス・レイテンシーは、ローカルの NUMA メモリーのレイテンシーよりも高くなります。逆に、ローカルの NUMA ノードのメモリー帯域幅は、リモートの NUMA ノードのメモリー帯域幅よりも広くなります。このため、スレッドは、そのスレッドを実行している NUMA ノードのメモリーにアクセスすることが望まれます。
各プロセッサーに対するデータ・アフィニティーを保証する方法は、並列化モデルに依存します。
- プロセス並列実行 では、HPC アプリケーションは通常、MPI (Message Passing Interface) を使用して実装されます。プロセスのアフィニティー・ピニングをサポートする MPI 実装は、各 MPI プロセスがプロセッサー・ソケットの境界を超えないようにしながら、同じソケットの物理メモリーにプロセスのデータを割り当てることで、ローカルの NUMA メモリーのアクセスを最大限にします。インテル® MPI は、特定の MPI プロセスを対応するプロセッサーに割り当てて不要なプロセス・マイグレーションを回避する、プロセスのアフィニティー・コントロールを提供します (9)。
- マルチプロセッサー共有メモリー・スレッディング では、アプリケーションは複数のスレッドにより並列化される単一のプロセスで構成されます。開発者は、可能であれば、データを消費するスレッドを実行するプロセッサー・ソケットに、そのデータが配置されるようにデータ構造を分割するべきです。これらのスレッドは、OS のスケジューラーが不要なスレッド・マイグレーションを行わないように、同じ NUMA ノードのプロセッサーに対してアフィニティーを設定するべきです。
スレッドが特定の NUMA ノードに必要なメモリーを割り当てられることを保証するため、Linux* と Windows* ではどちらも、割り当ての動作を制御する手段が提供されています。Linux* では、malloc はメモリーを単に予約します。OS は、データが初めてアクセスされる場合に限り、物理ページを実際に割り当てます (First touch ポリシー) (10)。このデフォルトポリシーは、開発者がこのポリシーを利用することを考慮すれば、多くのケースで最適に動作します。データは、データが処理フェーズでスレッドによってアクセスされるような方法で並列ルーチンを使用して初期化されます (First touch)。その結果、メモリーページは、これらのページにアクセスするスレッドを含むプロセッサー・ソケットに正しく割り当てられます。Windows* での詳細は、(11) および (12) を参照してください。
- ハイブリッド MPI + 共有メモリー・スレッディング では、上記のアプローチを組み合わせます。最も高いレベルでは、MPI プロセスは、システムで利用可能な複数のプロセッサー・ソケットで処理を並列化するために使用されます。次に、MPI プロセスはそれぞれ、プロセッサー・ソケットで利用可能なコアの数に基づいて共有メモリー・スレッディングで並列化されます。つまり、各 NUMA ノード内で、NUMA ノードに対する MPI アフィニティー・ピニングの利点と共有メモリー・スレッディングの利点を合わせ持つことになります。
以下に、2 つの実装 (共有メモリー・スレッディングのみと、2 つの NUMA ノードがあるシステムで MPI と共有メモリー・スレッディングを組み合わせたハイブリッド) を比較します。どちらの実装も、最も遅い方向 Z の外側のループで定義された処理を分割して並列化されています。共有メモリー・スレッディングのみの実装では、各スレッドはデータの連続する [dx, dy, dz/nt] セクションの計算を行います (nt はスレッドの総数)。ここでは、スレッド化に 2 つのバリエーションを定義しました。スレッディング・ベースラインは、OpenMP* による実装です。NUMA 対応スレッディングは、同じコードのバリエーションで、z ループが並列化された複製データ・アクセス・パターンに並列データ初期化ルーチンが追加されました。
ハイブリッド MPI + スレッディング・バージョンでは、データは 2 つの連続する [dx, dy, dz/2] セクションに分割されます。データの各セクションは、MPI プロセスに割り当てられます。次に、各 MPI プロセスは nt/2 のスレッドにスレッド化されます。図 9 は、このサンプルのスレッディング・ベースライン実装を 1.0 とした場合のパフォーマンスを比較したものです。
この 3 次元有限差分コードの 480x480x400 サンプルは、デュアルソケットのインテル® Xeon® プロセッサー X5680 (Westmere) システムで実行しました。問題サイズは、NUMA の効果が分かる、できるだけ小さなものを選択しました。コードの NUMA 対応スレッディング・バージョンは、インテル® コンパイラーの OpenMP* ライブラリーの KMP_AFFINITY 環境変数を使用してスレッド・アフィニティーが正しく設定された場合、1.4 倍のパフォーマンス向上を示しました (13)。ハイブリッド MPI + スレッディング・バージョン (それぞれの NUMA ノードにデータ構造を割り当ててデータの局所性を保証) は、1.7 倍のパフォーマンス向上を示しました♦ 。
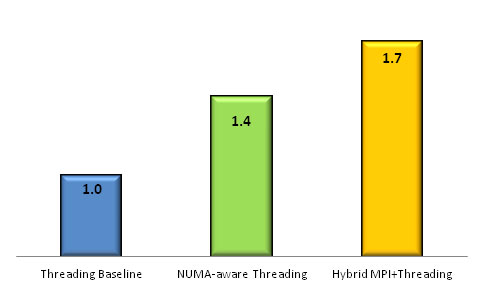
図 9: NUMA メモリー・アフィニティーのパフォーマンスにおける効果。ローカルとリモートの NUMA メモリーの帯域幅を考慮した実装では、ローカルのメモリー・アフィニティーが活用されています。表のバーは、このサンプルの NUMA 非対応実装に対するパフォーマンス向上を表しています。
続いて、クラスターの処理ノード内の最適化について説明します。
5 共有メモリーの並列化
このセクションでは、マルチスレッド・アプリケーションを開発するためにインテル® ソフトウェア・ツールがサポートしているさまざまなアプローチの概要を説明します。同じサンプルケースを使用して、OpenMP*、インテル® スレッディング・ビルディング・ブロック (インテル® TBB)、インテル® Cilk™ Plus ベースの並列処理の実装を示します。インテル® ソフトウェア・ツールでは POSIX* スレッドと MPI ベースの並列化もサポートしていますが、これらの実装についてはここでは説明しません。
前述のように、データ・ブロッキングを使用すると、空間と再利用できるデータを増やすことができます。このサンプルでは、(14) の表記に従ってスレッド・ブロック・サイズ TX、TY および TZ を定義することで、システムで利用可能なコア/スレッドにデータを分割しています。この処理は、さまざまな方法で行うことができます。例えば、ブロッキングをサポートしているスレッディング・モデル構造を使用するか、スレッドに割り当てるスレッディング・ブロックのリストを定義します。簡単に説明するため、この後のケースでは、ユニットストライドでベクトル化可能な 1 次元 x でのブロッキングを考慮していません。つまり、TX=dx としています。
第 1 次元 x のユニットストライドにおけるベクトル化と、第 2、第 3 次元 y-z のスレッディング・ブロック TY および TZ のみを考慮した場合、OpenMP* の parallel for 構文を使用してスレッディング・ブロックを処理できます。実際に、第 3 次元 z で スレッディング・ブロックの数が利用可能なスレッドをすべてビジーに保てるほど多くない場合、z と y のループはどちらも一重化されます。このケースは図 10 で示しています。
POSIX* スレッドに対する OpenMP* 実装の利点は、ユーザーがスレッドプールを管理する必要がないことです。インテル® コンパイラーの OpenMP* ライブラリーは、スレッド生成のオーバーヘッドを回避するように、スレッドプールを自動的に管理します。
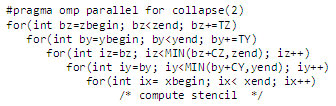
図 10: OpenMP* は、簡単な方法でスレッドにスレッディング・ブロックを割り当てることができます。この場合、OpenMP* 並列化により 2 つの外側のループは一重化されます。
この実装では、図 11 に示すように、スレッドに割り当てるスレッディング・ブロックのリストを定義する手法を採用しました。この手法を採用することで、開発者はスレッドに割り当てるスレッディング・ブロックを任意の順序で定義できます。また、ほかのスレッディング・モデルでもサンプルと同じフレームワークを使用できます。

図 11: スレッドに割り当てるスレッディング・ブロックのリストを定義します。リストのほかの部分は、赤-黒のループの再配置、Y-Z の反転、その他の順序スキームで変更できます。
図 12 は、スレッディング・ブロックのリストに基づく 2 つの実装による OpenMP* コードを抜粋したものです。最初の実装は、OpenMP* の parallel for 構文を使用してスレッドにスレッディング・ブロックを割り当てています。num_blocks はシステムで利用可能なスレッド数よりも大きくなる場合があることに注意してください。ここでの目標は、データの局所性を高めて、最適なロードバランスのデータ粒度にすることです。擬似関数 3DFD_BLK は、[0..dx, iyb..iyb+TY, izb..izb+TZ] で定義されたスレッディング・ブロックのベクトル化された有限差分を計算します。関数呼び出しとこの後のサンプルの省略記号 “…” は、追加引数 (例えば、ステンシル係数) を表しています。2 つめは、OpenMP* の task 構文を使用してスレッディング・ブロックを割り当てています。

図 12: ディスパッチするスレッドのリストを使用する OpenMP* 実装の 2 つのバリエーション。最初の実装は、OpenMP* の parallel for 構文を使用しています。2 つめは、OpenMP* のタスクを使用しています。擬似関数 3DFD_BLK は、[0..dx, iyb..iyb+TY, izb..izb+TZ] で定義されたスレッディング・ブロックのベクトル化された有限差分を計算します。
OS のスケジューラーによるスレッド管理は、OpenMP* ベースの実装のパフォーマンスに影響します。KMP_AFFINITY 環境変数 (13) を使用すると、スレッド配置を制御できます。また、KMP_LIBRARY を “turnaround” に設定して OpenMP* のダイナミック・スケジューリングを行うと、コア数が多いシステムではロードバランスを向上させることができます。
同様の方法で、インテル® Cilk™ Plus の拡張機能を使用して並列化を実装することもできます。OpenMP* と同じように、最初の実装は cilk_for ループを、2 つめは cilk_spawn を使用します。
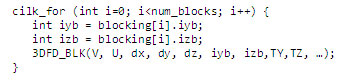
図 13: Cilk++ 実装の 2 つのバリエーション。OpenMP* と同様に、最初の実装は cilk_for を、2 つめは cilk_spawn を使用しています。
インテル® TBB を使用して blocking リストで定義したスレッディング・ブロックをディスパッチすることもできますが、図 14 では、インテル® TBB の blocked_range2d テンプレート・クラスを使用するバリエーションを示しています (15)。parallel_for ループは、ロードバランスのために使用され、ループの各要素に関数 3DFD_BLK を適用しています。ループ分割は 2 次元の半開区間 [ybegin,yend) × [zbegin,zend) で定義されます (最大ブロックサイズは TY および TZ)。
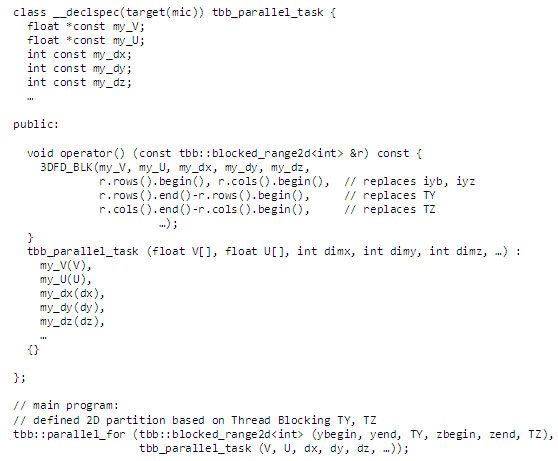
図 14: インテル® TBB の parallel_for ループで blocked_range2d クラスを使用してスレッド間の作業を自動的に分割します。このサンプルでは、2 次元の半開区間 [ybegin,yend) × [zbegin,zend) をそれぞれ、最大ブロックサイズ TY および TZ で分割しています。
アプリケーションのスレッド化、同期、メモリー管理、プログラミング・ツールについての技術情報は、インテルがソフトウェア開発者向けに提供しているガイド (16) を参照してください。
6 引用文献
- インテル® C++ コンパイラーのベクトル化ガイド
- ガイド付き自動並列化 (GAP) (http://software.intel.com/en-us/articles/guided-auto-parallel-gap/)
- インテル® コンパイラー 12 最適化クイック・リファレンス・ガイド (http://software.intel.com/sites/products/collateral/hpc/compilers/compiler_qrg12.pdf)
- インテル® C++ 組込み関数リファレンス (http://software.intel.com/sites/products/documentation/studio/composer/en-us/2011/compiler_c/intref_cls/common/intref_bk_intro.htm)
- インテル® 64 アーキテクチャーおよび IA-32 アーキテクチャー最適化リファレンス・マニュアル (英語)
- インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) (http://software.intel.com/en-us/avx)
- インテル® Cilk™ Plus のサポート (http://software.intel.com/en-us/articles/intel-cilk-plus-support)
- インテル® 64 アーキテクチャーおよび IA-32 アーキテクチャー・ソフトウェア開発マニュアル (英語)
- インテル® MPI
- NUMA 向けのアプリケーションの最適化
- >NUMA ベースのシステム向けアプリケーション・ソフトウェアに関する注意事項 (http://www.microsoft.com/whdc/archive/numa_isv.mspx (英語))
- Windows 開発、NUMA のサポート (英語)
- SMT または HT 対応システムで優れたパフォーマンスを得るためのスレッド・アフィニティーの設定 (http://software.intel.com/en-us/articles/setting-thread-affinity-on-smt-or-ht-enabled-systems/)
- 最新のマルチコア・アーキテクチャーにおけるステンシル計算の最適化と自動チューニング Stencil Computation Optimization and Auto-tuning on State-of-the-Art MulticorK. Datta, M. Murphy, V. Volkov, S. Williams, J. Carter, L. Oliker, D. Patterson, J. Shalf, K. Yelick. s.l. : IEEE Press Piscataway, NJ, USA, 2008, Proceeding SC ’08 Proceedings of the 2008 ACM/IEEE conference on Supercomputing.
- インテル® スレッディング・ビルディング・ブロック
- マルチスレッド・アプリケーション開発のためのガイド
著者紹介
Leonardo Borges: テキサス州ヒューストン在住のシニア・アプリケーション・エンジニアで、Energy vertical 分野における HPC の活用を研究しています。専門は数値解析と並列計算で、 Texas A&M University でコンピューター・サイエンスの博士号を取得しています。
Philippe Thierry: パリにあるインテルのエネルギー・アプリケーション・エンジニア・チームのシニア・スタッフ・エンジニアで、HPC と地震探査を専門としています。Paris School of Mines および University of Paris VII で地球物理学の博士号を取得しています。
著作権と商標について
本資料に掲載されている情報は、インテル製品の概要説明を目的としたものです。本資料は、明示されているか否かにかかわらず、また禁反言によるとよらずにかかわらず、いかなる知的財産権のライセンスも許諾するものではありません。製品に付属の売買契約書『Intel’s Terms and Conditions of Sale』に規定されている場合を除き、インテルはいかなる責任を負うものではなく、またインテル製品の販売や使用に関する明示または黙示の保証 (特定目的への適合性、商品適格性、あらゆる特許権、著作権、その他知的財産権の非侵害性への保証を含む) に関してもいかなる責任も負いません。
インテルによる書面での合意がない限り、インテル製品は、その欠陥や故障によって人身事故が発生するようなアプリケーションでの使用を想定した設計は行われていません。
インテル製品は、予告なく仕様や説明が変更される場合があります。機能または命令の一覧で「留保」または「未定義」と記されているものがありますが、その「機能が存在しない」あるいは「性質が留保付である」という状態を設計の前提にしないでください。これらの項目は、インテルが将来のために留保しているものです。インテルが将来これらの項目を定義したことにより、衝突が生じたり互換性が失われたりしても、インテルは一切責任を負いません。この情報は予告なく変更されることがあります。この情報だけに基づいて設計を最終的なものとしないでください。
本資料で説明されている製品には、エラッタと呼ばれる設計上の不具合が含まれている可能性があり、公表されている仕様とは異なる動作をする場合があります。現在確認済みのエラッタについては、インテルまでお問い合わせください。
最新の仕様をご希望の場合や製品をご注文の場合は、お近くのインテルの営業所または販売代理店にお問い合わせください。
本資料で紹介されている資料番号付きのドキュメントや、インテルのその他の資料を入手するには、1-800-548-4725 (アメリカ合衆国) までご連絡いただくか、インテルの Web サイトを参照してください。
Intel、インテル、Intel ロゴ、Xeon は、アメリカ合衆国およびその他の国における Intel Corporation の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
© 2011 Intel Corporation. 無断での引用、転載を禁じます。
* パフォーマンスおよびベンチマークの結果に関する詳細は、www.intel.com/benchmarks を参照してください。
| 最適化に関する注意事項 |
|
インテル® コンパイラー、関連ライブラリーおよび関連開発ツールには、インテル製マイクロプロセッサーおよび互換マイクロプロセッサーで利用可能な命令セット (SIMD 命令セットなど) 向けの最適化オプションが含まれているか、あるいはオプションを利用している可能性がありますが、両者では結果が異なります。また、インテル® コンパイラー用の特定のコンパイラー・オプション (インテル® マイクロアーキテクチャーに非固有のオプションを含む) は、インテル製マイクロプロセッサー向けに予約されています。これらのコンパイラー・オプションと関連する命令セットおよび特定のマイクロプロセッサーの詳細は、『インテル® コンパイラー・ユーザー・リファレンス・ガイド』の「コンパイラー・オプション」を参照してください。インテル® コンパイラー製品のライブラリー・ルーチンの多くは、互換マイクロプロセッサーよりもインテル製マイクロプロセッサーでより高度に最適化されます。インテル® コンパイラー製品のコンパイラーとライブラリーは、選択されたオプション、コード、およびその他の要因に基づいてインテル製マイクロプロセッサーおよび互換マイクロプロセッサー向けに最適化されますが、インテル製マイクロプロセッサーにおいてより優れたパフォーマンスが得られる傾向にあります。 インテル® コンパイラー、関連ライブラリーおよび関連開発ツールは、互換マイクロプロセッサー向けには、インテル製マイクロプロセッサー向けと同等レベルの最適化が行われない可能性があります。これには、インテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2)、インテル® ストリーミング SIMD 拡張命令 3 (インテル® SSE3)、ストリーミング SIMD 拡張命令 3 補足命令 (SSSE3) 命令セットに関連する最適化およびその他の最適化が含まれます。インテルでは、インテル製ではないマイクロプロセッサーに対して、最適化の提供、機能、効果を保証していません。本製品のマイクロプロセッサー固有の最適化は、インテル製マイクロプロセッサーでの使用を目的としています。 インテルでは、インテル® コンパイラーおよびライブラリーがインテル製マイクロプロセッサーおよび互換マイクロプロセッサーにおいて、優れたパフォーマンスを引き出すのに役立つ選択肢であると信じておりますが、お客様の要件に最適なコンパイラーを選択いただくよう、他のコンパイラーの評価を行うことを推奨しています。インテルでは、あらゆるコンパイラーやライブラリーで優れたパフォーマンスが引き出され、お客様のビジネスの成功のお役に立ちたいと願っております。お気づきの点がございましたら、お知らせください。 改訂 #20110307 |
