
この記事は、インテル® デベロッパー・ゾーンに公開されている「Enable Intel® Software Development Tools for HPC Applications Running on Amazon EC2* Cluster」(https://software.intel.com/en-us/articles/enable-intel-software-development-tools-for-hpc-applications-running-on-amazon-ec2-cluster) の日本語参考訳です。
1. はじめに
この記事では、インテル® ソフトウェア開発ツールを使用してコンパイルされたハイパフォーマンス・コンピューティング (HPC) 製品をスケールアウトして Amazon* Elastic Compute Cloud* (Amazon EC2*) 環境でホストされているインテル® Xeon® スケーラブル・プロセッサーを活用する方法を説明します。ここでは、Amazon Web Services* (AWS*) により提供されるオープンソースのツール、Cloud Formation Cluster (CfnCluster) を使用して、伸縮自在な HPC クラスターをクラウドに 15 分未満でデプロイします。クラスターが作成されると、スケジューラー、メッセージ・パッシング・インターフェイス (MPI) 環境、共有ストレージなどの標準 HPC ツールがセットアップされます。
このチュートリアルの対象者: インテル® C++ コンパイラーやインテル® Fortran コンパイラーとインテル® MPI ライブラリーを使用して HPC アプリケーションを開発し、複数の HPC ノードでアプリケーションのスケーリングをテストしたいと考えているアプリケーション開発者。クラウドで動作している HPC 環境でインテル® ソフトウェア開発ツールを使用してコンパイルされた事前コンパイル済みアプリケーション・バイナリーを実行してアプリケーションのスループットを向上したいと考えているアプリケーション・ユーザー。
2. CfnCluster
CfnCluster は、AWS* 上に HPC クラスターをデプロイおよび維持するフレームワークです。
CfnCluster ツールを使用して AWS* に HPC クラスターをセットアップするには、AWS* アカウントと Amazon EC2* のキーペアが必要です。ローカル・ワークステーションに、AWS* コマンドライン・インターフェイス (AWS* CLI) と最新バージョンの Python* (Python* 2.7.9 以降または Python* 3.4 以降) をインストールして設定します。
AWS* にサインアップして Amazon EC2* のキーペアにアクセスするプロセスは、この記事の範囲外であるため、ここでは取り上げません。この記事の残りの部分では、ユーザーが AWS* アカウントを作成済みで、Amazon EC2* のキーペアにアクセスできると仮定しています。AWS* アカウントの作成についての詳細は、AWS* Web サイトを参照してください。Amazon EC2* のキーペアの作成についての詳細は、このページを参照してください。
次のセクションで、AWS* CLI と CfnCluster のインストール方法および設定方法を説明します。
2.1 AWS* CLI のインストールと設定
ワークステーションに最新バージョンの Python* がインストールされていれば、Python* のパッケージ・マネージャー pip を使用して AWS* CLI をインストールできます。
$ pip install awscli --upgrade –user
AWS* CLI をインストールしたら、次のコマンドを使用して設定します。AWS* CLI を設定するには、Amazon EC2* のキーペアが必要です。AWS* インスタンスを起動する領域を選択することもできます。AWS* CLI の設定についての詳細は、このページを参照してください。
$ aws configure
2.2 CfnCluster のインストールと設定
CfnCluster をインストールするには、pip コマンドを使用します。
$ sudo pip install --upgrade cfncluster
CfnCluster をインストールしたら、次のコマンドを使用して設定します。
$ cfncluster configure
CfnCluster 設定ファイルのデフォルトの場所は ~/.cfncluster/config です。エディターを使用してファイルを編集し、クラスター・サイズ、スケジューラーのタイプ、ベース・オペレーティング・システム、その他のパラメーターをカスタマイズできます。図 1 は、CfnCluster 設定ファイルの例です。
[aws] aws_access_key_id = AAWSACCESSKEYEXAMPLE aws_secret_access_key = uwjaueu3EXAMPLEKEYozExamplekeybuJuth aws_region_name = us-east-1 [cluster Cluster4c4] key_name = AWS_PLSE_KEY vpc_settings = public initial_queue_size = 4 max_queue_size = 4 compute_instance_type = c5.9xlarge master_instance_type = c5.large maintain_initial_size = true scheduler = sge placement_group = DYNAMIC base_os = centos7 [vpc public] vpc_id = vpc-68df1310 master_subnet_id = subnet-ba37e8f1 [global] cluster_template = Cluster4c4 update_check = true sanity_check = true
図 1. CfnCluster 設定ファイルの例
図 1 の設定ファイルには、CfnCluster ツールを使用して起動される、クラスターに関する次の情報が含まれています。
- AWS* アクセスキーと HPC クラスターの領域名
- クラスターのパラメーター
- 初期キューサイズと最大キューサイズ。初期キューサイズは、クラスターが最初に起動されたときに利用できる計算ノードの数です。CfnCluster は伸縮自在なクラスターをセットアップできるため、計算ノードの数はニーズによって異なります。最大キューサイズは、クラスターで利用できる計算ノードの最大数です。このチュートリアルでは、4 計算ノードのクラスターを起動します。
- マスターノードと計算ノードのインスタンス・タイプ。マスターノードと計算ノードで起動される AWS* インスタンス・タイプ。現在利用可能なインスタンス・タイプは、AWS* インスタンス・タイプ Web ページにリストされています。この記事では、インテル® Xeon® スケーラブル・プロセッサー・ベースの Amazon EC2* C5 インスタンスを選択しました。クラスターの管理とジョブ・スケジューラーの実行を行うマスターノードに c5.large モデル (2 仮想 CPU -vCPU)、計算ノードに c5.9xlarge モデル (36 vCPU) を選択しました。
- スケジューラー。このクラスターに設定およびインストールされるジョブ・スケジューラーのタイプ。デフォルトでは、CfnCluster は Sun Grid Engine (SGE) スケジューラー (英語) を使用してクラスターを起動します。Slurm ワークロード・マネージャー (Slurm) (英語) および Torque リソース・マネージャー (Torque) (http://www.adaptivecomputing.com/products/open-source/torque/) オプションも利用できます。
- プレイスメント・グループ。インスタンスを基盤となるハードウェアに配置する方法を決定します。できるだけ低いレイテンシーが必要な HPC アプリケーションのパフォーマンスを向上するには、正しいプレイスメント・グループを選択することが重要です。NONE (デフォルト)、DYNAMIC、またはカスタム (ユーザーが作成) のいずれかのプレイスメント・グループを選択します。DYNAMIC は、一意のプレイスメント・グループをクラスターで作成および削除します。
- Virtual Private Cloud (VPC) とサブネット。VPC は、ほかのアカウントやユーザーから論理的に分離された、AWS* アカウント専用の仮想ネットワークです。CfnCluster の起動に使用する VPC ID とマスター・サブネット ID は、ユーザーの AWS* コンソールから参照できます。
CfnCluster パラメーターのほかのオプションについての詳細は、CfnCluster の設定 Web ページ (英語) を参照してください。
3. CfnCluster の作成
CfnCluster 設定ファイルを検証したら、HPC クラスターを起動します。
$ cfncluster create Cluster4c4
クラスターが正常に作成されると、CfnCluster ツールはマスターノードのパブリック/プライベート IP アドレスのような必要な情報を提供します。これらの情報を使用して、起動した HPC クラスターにアクセスします。オープンソースのツール、Ganglia モニタリング・システムを使用してクラスターの使用状況をモニターする URL も提供されます。
Status: cfncluster-Cluster4c4 - CREATE_COMPLETE Output:"MasterPublicIP"="34.224.148.71" Output:"MasterPrivateIP"="172.31.18.240" Output:"GangliaPublicURL"="http://34.224.148.71/ganglia/" Output:"GangliaPrivateURL"="http://172.31.18.240/ganglia/"
3.1 CfnCluster へのログイン
パブリック IP アドレスを使用してマスターノードに SSH 接続します。ベース・オペレーティング・システムが CentOS* の場合、デフォルトのユーザー名は centos です。Amazon* Linux* AMI (Amazon Machine Image) の場合、デフォルトのユーザー名は ec2-user です。
$ ssh centos@MasterPublicIP Eg. $ ssh centos@34.224.148.71
4. HPC クラスター上で HPC ジョブを実行する
インテル® MPI ライブラリーは、OpenMPI* や MVAPICH のようなほかのオープンソースのメッセージ・パッシング・インターフェイス (MPI) ライブラリーよりも MPI パフォーマンスが大幅に優れています。これは、インテル® MPI ライブラリーは、ハイパフォーマンスな MPI-3.1 仕様を実装して、インテル® アーキテクチャー・ベースのクラスター上で MPI アプリケーションを高速に実行することに焦点を当てているためです。しかし、デフォルトでは、CfnCluster は、オープンソースの MPI ライブラリーである OpenMPI* をインストールします。インテル® Xeon® スケーラブル・プロセッサー・ベースの Amazon EC2* C5 インスタンスのアプリケーション・パフォーマンスを向上するには、インテル® MPI ライブラリー、インテル® コンパイラー、インテル® マス・カーネル・ライブラリー (インテル® MKL) のスタンドアロン・ランタイム・パッケージをインストールして、インテル® コンパイラーとインテル® MPI ライブラリーを使用してコンパイルしたアプリケーションを実行する必要があります。
4.1 インテル® MPI ライブラリーのランタイムのインストール
インテル® MPI ライブラリーのランタイムパッケージには、インテル® MPI ライブラリー・ベースのアプリケーションを実行するために必要なものがすべて含まれています。ランタイムパッケージは無料で、インテル® MPI ライブラリー対応のアプリケーションをすでに利用しているユーザーが対象です。インストール・スクリプトとランタイムスクリプトが含まれています。ランタイムパッケージは、https://registrationcenter.intel.com/ja/forms/?ProductID=1744 からダウンロードできます。
インテル® MPI ライブラリーのランタイムパッケージをダウンロードしたら、次のコマンドを使用してランタイムパッケージを展開してインストールします。ここでは、インテル® MPI ライブラリー 2018 Update 2 をダウンロードしたと仮定します。デフォルトでは、インテル® MPI ライブラリーは /opt/intel ディレクトリー以下にインストールされます。しかし、ここではライブラリーをクラスターのすべてのノードで共有するため、インストール・ディレクトリーを /shared/opt/intel に変更します。
セットアップ済みのクラスターでは、ユーザー向けの共有 NFS マウントが作成され、/shared で利用できます。デフォルトでは、この共有 NFS マウントは Amazon Elastic Block Storage* (Amazon EBS*) ボリュームで、クラスターが切り離されるとコンテンツはすべて削除されます。しかし、一般的には、同じ事前設定済みソフトウェアを将来クラスターにデプロイできるように、インテル® MPI ライブラリーのようによく使われる HPC アプリケーション・ソフトウェアを /shared ドライブにインストールして、スナップショットを /shared Amazon EBS* ボリュームにコピーします。
$ tar -xvzf l_mpi-rt_2018.2.199.tgz $ cd l_mpi-rt_2018.2.199 $ sudo ./install.sh
次のステップは、事前定義済みの MPI アプリケーション・パッケージを HPC クラスターにコピーまたはダウンロードすることです。このチュートリアルでは、例として、事前定義済みのインテル® MKL ベンチマークの 1 つである、HPCG (High Performance Conjugate Gradient) ベンチマークを使用して、HPC クラスター上で MPI アプリケーションを実行する方法を紹介します。インテル® MKL のスタンドアロン・バージョン (無料) は、こちら (英語) からダウンロードできます。
HPCG ベンチマーク・プロジェクトは、HPC システムをランク付けする新しいメトリックを提供し、TOP500 スーパーコンピューター・システムのランク付けに使用される HPL (High Performance Linpack) ベンチマークを補完することを目的としています。アプリケーションの特性に関しては、システムの計算能力を重視しない点で HPCG は HPL と異なります。また、データ・アクセス・パターンも異なります。その結果、HPCG は重要なアプリケーションの広範なセットの代表的なベンチマークとして利用されています。
4.2 インテル® MKL のインストール
$ tar -xvzf l_mkl_2018.2.199.tgz $ cd l_mkl_2018.2.199 $ sudo ./install.sh $ cp -r /shared/opt/intel/mkl/benchmarks/hpcg /home/centos/hpcg
アプリケーションがインテル® MKL に依存していない場合は、このステップをスキップして、アプリケーション・パッケージをマスターノードにコピーしてください。その場合でも、ほかのランタイム・ライブラリー (例えば、インテル® コンパイラーのランタイム・ライブラリー) のインストールが必要になることがあります。
$ scp -r /opt/intel/mkl/benchmarks/hpcg centos@34.224.148.71:/home/centos/hpcg
4.3 インテル® コンパイラーのランタイム・ライブラリーのインストール
インテル® C++/Fortran コンパイラー 2018 for Linux* の再配布可能なライブラリーは、https://software.intel.com/en-us/articles/redistributable-libraries-for-intel-c-and-fortran-2018-compilers-for-linux からダウンロードできます。インテル® MKL をインストールしている場合は、このステップをスキップしてかまいません。
$ tar -xvzf l_comp_lib_2018.2.199_comp.cpp_redist.tgz $ cd l_comp_lib_2018.2.199_comp.cpp_redist $ sudo ./install.sh
4.4 計算ノードのリスト
クラスター全体で MPI ジョブを実行するため、HPC ジョブを実行する計算ノードのリスト (hostfile または machinefile) を使用します。スケジューラーのタイプに応じて、hostfile を設定します。
// For SGE scheduler
$ qconf -sel | awk -F. '{print $1}' &> hostfile
// For Slurm workload manager
$ sinfo -N | grep compute | awk '{print $1}' &> hostfile
4.5 ジョブ提出スクリプト
スケジューラーを使用して MPI ジョブを起動するには、ジョブ提出ファイルを作成する必要があります。図 2 は、SGE スケジューラーを使用してインテル® Xeon® スケーラブル・プロセッサー・ベースの計算インスタンス (Amazon EC2* C5 インスタンス) で HPCG を起動するジョブ提出スクリプトの例です。
#!/bin/sh #$ -cwd #$ -j y # Executable EXE=/home/centos/hpcg/bin/xhpcg_skx # MPI Settings source /shared/opt/intel/compilers_and_libraries/linux/bin/compilervars.sh intel64 source /shared/opt/intel/impi/2018.2.199/bin64/mpivars.sh intel64 # Fabrics Settings export I_MPI_FABRICS=shm:tcp # Launch MPI application mpirun -np 4 -ppn 1 -machinefile hostfile -genv KMP_AFFINITY="granularity=fine,compact,1,0" $EXE
図 2. ジョブ提出スクリプト – SGE スケジューラー (job.sh)
図 3 は、Slurm ワークロード・マネージャーの場合のジョブ提出スクリプトの例です。
#!/bin/bash #SBATCH -N 4 #SBATCH -t 00:02:00 #wall time limit # Executable EXE=/home/centos/hpcg/bin/xhpcg_skx # MPI Settings source /shared/opt/intel/compilers_and_libraries/linux/bin/compilervars.sh intel64 source /shared/opt/intel/impi/2018.2.199/bin64/mpivars.sh intel64 # Fabrics Settings export I_MPI_FABRICS=shm:tcp # Launch MPI application mpirun -np 4 -ppn 1 -machinefile hostfile -genv KMP_AFFINITY="granularity=fine,compact,1,0" $EXE
図 3. ジョブ提出スクリプト – Slurm スケジューラー (job.sh)
4.6 HPC ジョブの起動
ジョブ提出スクリプトの変更が完了したら、MPI アプリケーションを実行します。
// For SGE scheduler $ qsub job.sh // For Slurm workload manager $ sbatch job.sh
4.7 HPC ジョブのモニタリング
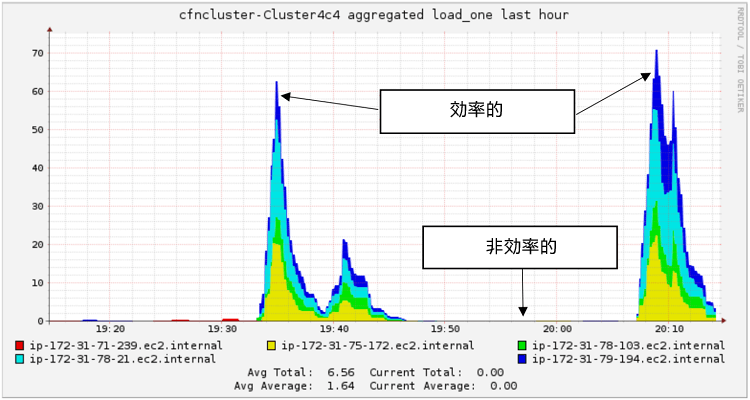
CfnCluster ツールを使用してセットアップされた HPC クラスターは、クラスター固有の URL を利用して Ganglia モニタリング・システムにアクセスできます。Ganglia パブリック URL (http://<PublicIPAddress>/ganglia/) を使用して、クラスターの使用状況をモニターするコンソールビューにアクセスします。図 4 は、1 時間前からのクラスター使用状況を示しています。
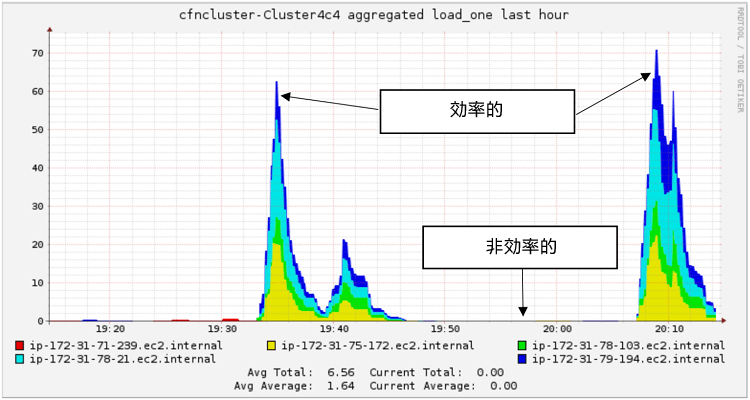
図 4. Ganglia を使用したクラスター使用状況の表示
Ganglia モニタリング・システムについての詳細は、こちら (英語) を参照してください。
5. CfnCluster の削除
マスター・インスタンスからログオフしたら、CfnCluster を削除します。
$ cfncluster list //To get list of clusters online $ cfncluster delete Cluster4c4
クラスターを再利用する予定があり、クラスターを作成するたびにランタイム・ライブラリーをインストールしないようにするには、クラスターを削除する前に、Amazon EBS* ボリューム上の共有ドライブ /shared のスナップショットを作成します。クラスターを再利用するために Amazon EBS* ボリュームのスナップショットを作成する方法についての詳細は、伸縮自在な HPC クラスターをデプロイするからダウンロードできるドキュメント (英語) を参照してください。
6. まとめ
この記事では、AWS* クラウド環境で動作する HPC アプリケーションでインテル® Xeon® スケーラブル・プロセッサーの機能を活用する方法を紹介しました。具体的には、AWS* から CfnCluster ツールを使用して 4 計算ノードのクラスターを設定および起動する方法を説明しました。この記事で説明した手順を使用して、HPC アプリケーション開発者やユーザーは、ワークステーション上でインテル® Parallel Studio XE を使用してアプリケーションをコンパイルしてデプロイした後、スタンドアロン・ランタイム・ライブラリー (登録ユーザーは無料で利用可能) と SGE や Slurm などのジョブ・スケジューラーを利用してアプリケーションのスケーラビリティーをテストできます。アプリケーションのパフォーマンスは、選択した計算インスタンスのタイプ、メモリーサイズ、計算ノード間の利用可能なネットワークのスループットに依存します。
7. 参考文献
- Amazon EC2*
- Amazon EC2* のキーペア
- Amazon* Elastic Block Store
- Amazon* Virtual Private Cloud
- Amazon Web Services*
- AWS* コマンドライン・インターフェイス
- AWS* プレイスメント・グループ
- CfnCluster の設定 (英語)
- 伸縮自在な HPC クラスターをデプロイする
- Ganglia モニタリング・システム (英語)
- HPCG ベンチマーク (英語)
- インテル® MKL
- インテル® MPI ライブラリー
- インテル® Parallel Studio XE
- インテル® Xeon® スケーラブル・プロセッサー
- インテル® C++/Fortran コンパイラー 2018 for Linux* の再配布可能なライブラリー
https://software.intel.com/en-us/articles/redistributable-libraries-for-intel-c-and-fortran-2018-compilers-for-linux
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
