


この記事は、インテルの The Parallel Universe Magazine 31 号に収録されている、OpenCL* を利用して FPGA プログラミングに取り組むための章を抜粋翻訳したものです。
FPGA が注目されている理由
フィールド・プログラマブル・ゲート・アレイ (FPGA) は、低レイテンシーで高いパフォーマンスと電力効率を実現できる優れたハードウェアです。これらの長所は、FPGA の大規模な並列機能と再構成の容易性により実現されます。FPGA は、次のような処理を行うことができる、再構成可能なチャネルレス型の構造を提供します。
- カスタム・ハードウェア・アクセラレーターを設計する。
- 単一アプリケーションに配置する。
- 異なるアプリケーションの新しいアクセラレーターとしてデバイスを素早く再構成する。
この記事では、独自の設計を行う方法と、それらの設計を使用してアプリケーションを高速化する方法を説明します。ハードウェア・エンジニアは、さまざまなアプリケーションで ASIC の代わりに FPGA を長年使用してきました。これまで、FPGA の構成 (プログラミング) は、Verilog* や VHDL* のような高水準定義言語を利用して行われてきました。これらの設計手法はハードウェア・エンジニアにはよく知られていますが、ソフトウェア開発者にとっては全く新しいものです。
OpenCL* を中心とする新しいツールは、このギャップを埋め、FPGA ハードウェア・プラットフォームの恩恵をソフトウェア開発者にもたらします。これらの新しいツールを使用すると、C のような構文で記述されたカスタム・アルゴリズムを高速で電力効率の良いハードウェアに変換できる、高度に構成可能なデバイスとして FPGA を活用することができます。これらのソリューションの高い柔軟性とパフォーマンスは、最新世代の FPGA デバイスのおかげです。
大規模な並列処理
インテル® Stratix® 10 FPGA は、最大 10 TFLOPS の単精度浮動小数点パフォーマンスを提供します。また、標準数値形式に制限されません。例えば、2 ビットのディープ・ニューラル・ネットワークの実装は困難でしたが、2017 年 11 月にスーパーコンピューター上で行われたデモで紹介された、インテルのディープラーニング・アクセラレーターの構成可能なワークロードを利用すると簡単に実装できます。
インテル® FPGA は、大規模な並列処理とハードウェアの柔軟性によりレイテンシーを軽減します (図 1)。FPGA はデータフロー (またはパイプライン) の構成がプログラムされるため、データの移動が最適化され、ホスト CPU と FPGA 間のデータ転送は排除されます。
注意すべき点
現在では、C プログラマーが FPGA プログラミングを試してみることを妨げるものは何もありません。ただし、OpenCL* (新しい開発環境と新しい手法を含む) を使用して FPGA のプログラミングを行う場合も、ほかのすべてのプログラミングと同様に、学習曲線が存在します。幸い、オンライン・トレーニングと OpenCL* コーディング・ガイドを利用することで、簡単に FPGA プログラミングに取り組むことができます。
FPGA の開発環境
OpenCL* ソフトウェア開発環境は Eclipse* または Visual Studio* ベースであるため、C プログラマーには馴染み深いものです。この記事では、OpenCL* で最初のプログラムを記述する方法と、そのプログラムを FPGA で実行する方法を説明します。
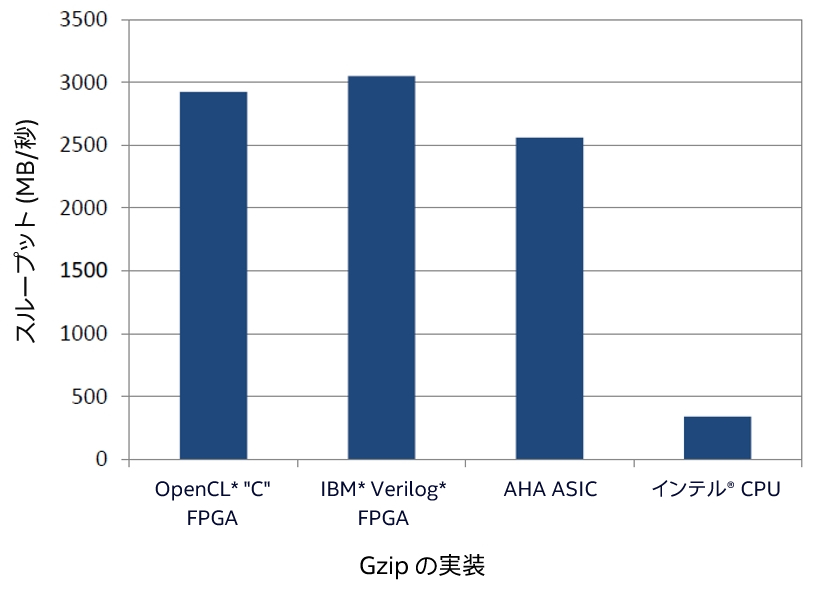
図 1. FPGA への対応が進む OpenCL*: 非常に生産的な OpenCL* FPGA プログラミングと、生産性が低く、アプローチの種類が少ない 3 つの従来のプログラミングを使用した結果の比較。(この記事の最後の関連情報セクションの「Gzip on a Chip」を参照。)
FPGA の最適化
新しいデバイスとプログラミング手法には、最高のパフォーマンスを達成するさまざまな秘訣があります。これらの最適化は、アルゴリズムのデータ構造組織やクリーン思考などのよく知られているアプローチから、OpenCL* でパイプラインを表現する最も効果的な方法までさまざまです。よくある状況ではありませんが、CPU のインライン・アセンブリーを使用するのと同じように、ハードウェア記述言語プログラミング (Verilog* または VHDL*) も使用可能です。FPGA の最適化は CPU や GPU の最適化とは異なりますが、簡単でも難しくもありません。
CPU や GPU と同様に、FPGA プログラマーは FPGA 向けに記述された (ハードウェア・エンジニアが通常 IP ブロックと呼ぶ) ライブラリーを使用できます (FPGA の最適化についてさらに詳しく知りたい方は、この記事の次に、インテル® FPGA SDK for OpenCL* ベスト・プラクティス・ガイドをお読みになることを推奨します。)
