


この記事は、インテルの The Parallel Universe Magazine 28 号に収録されている、OpenMP* のこれまでの歩みと今後に関する章を抜粋翻訳したものです。
OpenMP* Architecture Review Board (ARB) (英語) は、1997 年 10 月に OpenMP* Fortran 仕様 1.0 を、そしてその約 1 年後に C/C++ 仕様を発表しました。当時、世界最速のスーパーコンピューター ASCI Red (英語) は、2 基のインテル® Pentium® Pro プロセッサー (200MHz) を搭載した計算ノードで構成されていました。(今では信じられないことですが、当時は最先端のスーパーコンピューティングで、シングルコアの 200MHz のインテル® Pentium® プロセッサーが最速と考えられていました。) 4600 万ドル (現在の約 6800 万ドルに相当) を投じて構築された ASCI Red は、TOP500 LINPACK ベンチマークで TFLOPS (1 秒間に 1 兆回の浮動小数点演算を実行) を達成した最初のスーパーコンピューターでした。また、その後の傾向の前兆とも言える、メガワットの電力を消費した最初のスーパーコンピューターでもあります。それと比べると、最近のデュアルソケットのインテル® Xeon® プロセッサー v4 ファミリーは、TFLOPS の計算性能と電力消費の両方において格安と言えます。
Center for Research in Extreme Scale Technologies (https://www.crest.iu.edu) ディレクターの Thomas Sterling 博士は、次のように述べています。「OpenMP* により、単純さと統一性を強調した単一システムのプログラミングと実行という見方がもたらされました。これは、システム・ソフトウェアの開発者には、非同時性、レイテンシー、制御のオーバーヘッドへの対応を求める一方、将来のハードウェア・システムの設計者には、エクサスケールの時代に向けてユーザーの生産性とパフォーマンスの移植性に取り組むように働きかけます。過去 20 年間の素晴らしい成果は、スケーラブル・コンピューティングの次の 20 年間につながるでしょう。」
OpenMP*: 将来を考慮した、開発者による取り組み
OpenMP* イニシアチブは、デベロッパー・コミュニティーの働きかけによって発足しました。当時、異なる共有メモリー型並列プラットフォーム間でコードを移行するための、信頼性のある標準規格に対する関心が高まっていました。
OpenMP* が登場する前は、Pthreads などのスレッド化モデルを明示的に使用するか、MPI などの分散フレームワークを使用して並列コードを作成する必要がありました。(最初の MPI 標準は 1994 年に完成しました。) OpenMP* プラグマを追加するだけで、共有メモリーモデルで並列処理を利用できるという便利さは画期的でした。しかし、シングルスレッド・プロセッサーのクラスターが主流だった当時のハイパフォーマンス・コンピューティングでは、スレッドベースのコンピューティング・モデルに対する関心は限られていました。一部のハードウェア・プラットフォームでは、プラグイン CPU を追加することで、ハードウェア・ベースのマルチスレッド・パフォーマンスを利用できましたが、一般にスレッドは、スケーラブルな並列パフォーマンスではなく、OS タイムスライスを使用して非同期動作をエミュレートするソフトウェア手法と考えられていました。当時、スレッドに関する議論の焦点は、メモリーを共有する軽量なスレッドではなく、フォーク/ ジョインで生成されるプロセスなどの重いスレッドの使用でした。ノード内のハードウェア並列処理は、デュアルコアまたはクアッドコア・プロセッサー・システムに限定されていたため、OpenMP* によるスケーリングは取るに足らない問題でした。
このため、分散メモリー MPI コンピューティングが並列処理への唯一の道と考えられていた中、1997 年に発表された OpenMP* 仕様は、将来をよく考慮したものであると言えます。基本的に、ネットワークを介して多数のマシンを接続することは安価で簡単です。デナード・スケーリング則 (英語) の世界では、アプリケーション・パフォーマンスの向上は、MPI ノードを追加するか、シリアル・ソフトウェアをより高速に実行できるより高いクロックレートのプロセッサーを搭載したマシンによって達成可能です。そのため、COTS (既製品の) ハードウェアを使用してクラスターを構築することでスピードアップが図られ、ハイパフォーマンス・コンピューティングでは一般にこの手法が採用されていました (図 1)。例えば、1998 年のオリジナルの Beowulf のハウツーでは、「Beowulf は、クラスター・コンピューターで並列の仮想コンピューターを形成しており、多数のワークステーションではなく単一のマシンのように動作します。」と説明しています。つまり、科学または商業分野においてマルチコア・プロセッサーに対する需要がほとんどなかったのです。マルチスレッド並列コンピューティングは、主流のプログラミング・モデルというよりも、興味深い HPC プロジェクトという程度でした。図 1 に示すように、超並列 SIMD (Single Instruction, Multiple Data) の時代は短く、SIMD アーキテクチャー・ベースの CM-2 スーパーコンピューターと CM-5 MIMD (Multiple Instruction, Multiple Data) 超並列プロセッサー (MPP) スーパーコンピューターの製造元である Thinking Machines Corporation の消滅とともに幕を閉じました。この時代の SMP (ここでは共有メモリー・マルチプロセッサーを表す) の一例として、SGI* Challenge があります。
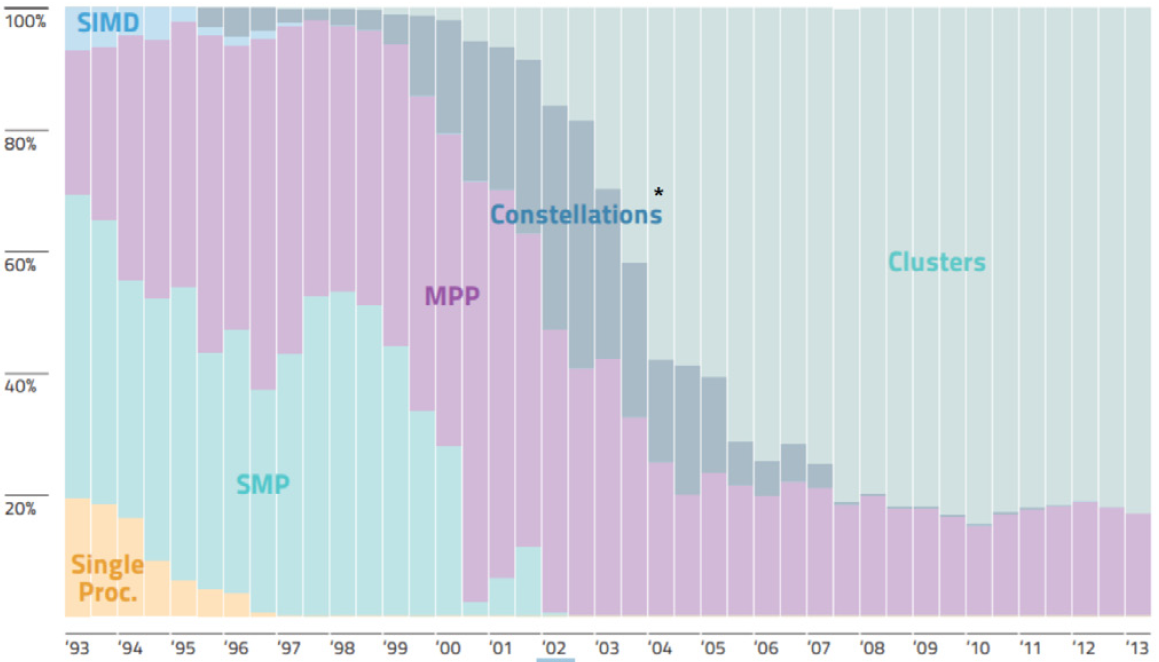
図 1. 年ごとの TOP 500 に占めるシステム・アーキテクチャーの割合 (出典: top500.org) (コンステレーション (Constellations) は、大規模 SMP システムのクラスターを指します。)
OpenMP* 時代の幕開け: デナード・スケーリング則の衰退とマルチコアへの関心の高まり
2005 年から 2007 年の間に、デナード・スケーリング則は衰退し、現代のマルチコア・プロセッサーが登場し始めました。クロックレートの上昇により大幅なパフォーマンスの向上が達成できなくなったため、さらなるパフォーマンスを生み出し、アップグレードを促すためにも、メーカーはプロセッサー・コアを増やし始めました。この方針転換により、次世代のハードウェアではクロックレートの向上により自動的にコードが高速化される、という期待はできなくなりました。その結果、アプリケーション・パフォーマンスを向上する手段として、スレッドベースのコンピューティングの本格的な調査が始まりました。とは言うものの、ほとんどのアプリケーションは、マルチプロセッサー上でコアごとに 1 つのシリアル MPI ランクを実行するように並列化されただけでした。
図 2 は、TOP500 のパフォーマンス・シェアを示すグラフです。このグラフから分かるように、2007 年から 2008 年の間に、パフォーマンス分野ではマルチコア・プロセッサーが主流となりました。それ以降、コア数が増加傾向にあることは一目瞭然です。
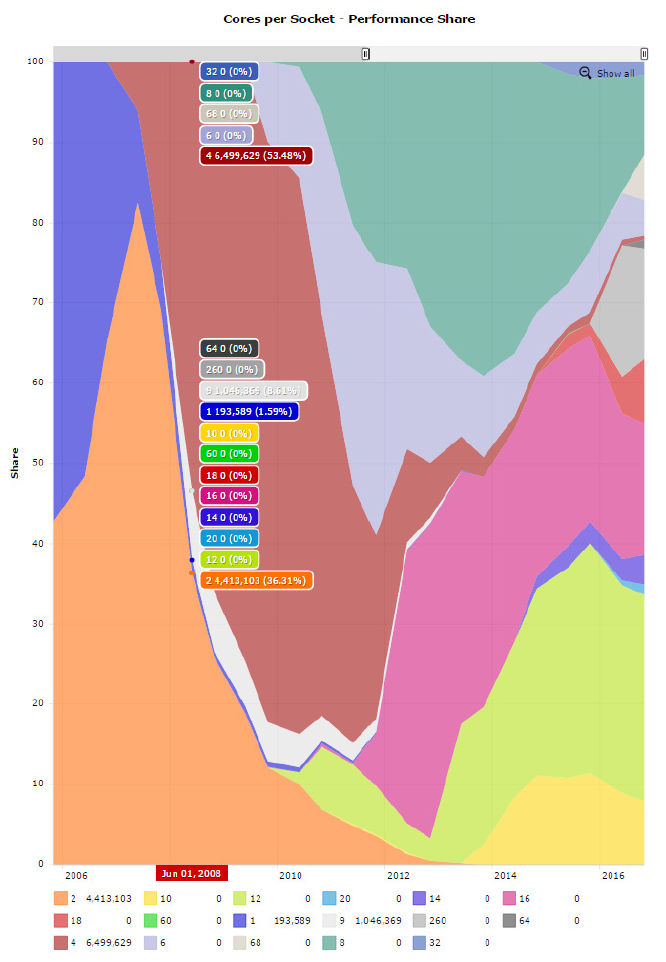
図 2. TOP500 におけるコア数の増加によるパフォーマンスの向上 (出典: top500.org (英語))
