
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Use GPU Roofline to Identify Optimization Opportunities」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピでは、インテル® Advisor を使用してインテル® GPU プラットフォームで実行される SYCL* アプリケーションを最適化するステップバイステップのアプローチに注目します。
また、インテル® Advisor GPU ルーフラインを使用して、アプリケーションのパフォーマンスを解析する方法を説明します。インテル® Advisor で提供される推奨事項を使用してソースコードに反復的な修正を加えることで、ベースラインの結果と比較してアプリケーションのパフォーマンスを 1.63 倍向上できます。以下のセクションでは、すべての最適化手順について詳しく説明します。
使用するもの
ここでは、このレシピで示す結果を得るために使用したハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor
https://www.intel.com/content/www/us/en/developer/tools/oneapi/advisor.html (英語) からダウンロードできます。
- アプリケーション:
QuickSilver サンプル・アプリケーション
GitHub* の https://github.com/oneapi-src/Velocity-Bench/tree/main/QuickSilver/SYCL/src (英語) からダウンロードできます。
- ワークロード:
- scatteringOnly.inp
- Coral2_p1_1*.inp
https://github.com/oneapi-src/Velocity-Bench/tree/main/QuickSilver/Examples (英語) から入手できます。
- コンパイラー: インテル® oneAPI DPC++/C++ コンパイラー
スタンドアロン・コンポーネント・カタログ (英語) からダウンロードできます。
- オペレーティング・システム: Linux* (Ubuntu* 22.04.3 LTS)
- CPU:インテル® Xeon® Platinum 8480+ プロセッサー (開発コード名 Sapphire Rapids)
- GPU:インテル® データセンター GPU マックス 1550 (開発コード名 Ponte Vecchio)
必要条件
- インテル® oneAPI DPC++/C++ コンパイラーとインテル® Advisor の環境変数を設定します。
例:$ source <oneapi-install-dir>/setvars.sh - 2 つのツールが適切に設定されていることを確認するには、次のコマンドを実行します。
$ icpx --version$ advisor --version正しく設定されている場合、各ツールのバージョンが表示されます。
アプリケーションのビルド
- アプリケーションの GitHub* リポジトリーをローカルシステムにクローンします。
$ git clone https://github.com/oneapi-src/Velocity-Bench.git - QuickSilver アプリケーション・リポジトリーに移動します。
$ cd ~/Velocity-Bench/QuickSilver/SYCL/ - build ディレクトリーを作成します。
$ mkdir build $ cd build - build ディレクトリーで次のコマンドを実行し、cmake を使用して QuickSilver アプリケーションをビルドします。
$ CXX=icpx cmake .. $ make -sj現在のディレクトリーに qs 実行ファイルが生成されます。
- QuickSilver アプリケーションのパフォーマンス・メトリック・デモを実行するには、次のコマンドを使用します。
$ QS_DEVICE=GPU ./qs -i ../../Examples/AllScattering/scatteringOnly.inpコンソール出力で、このアプリケーションのパフォーマンス・メトリックの高い値を探します。
ベースラインを確認する
- 次のコマンドを使用して、ビルドされた qs バイナリーで [GPU Roofline Insights perspective (GPU ルーフラインの調査パースペクティブ)] を実行します。
$ QS_DEVICE=GPU advisor -collect roofline --profile-gpu -gpu-sampling-interval=0.1 --project-dir=qs_base_run -- ./qs_base -i ../../Examples/AllScattering/scatteringOnly.inp - インテル® Advisor GUI で結果を開きます。
- [Summary (サマリー)] レポートで、GPU 時間、GPU ホットスポット、その他のデータを調べます。
- [GPU Roofline Regions (GPU ルーフライン領域)] ペインに移動し、GPU で実行されているカーネルの GPU ルーフラインを調べます。各カーネル呼び出し経過時間、OPS、カーネルが使用するローカルおよびグローバルのワークサイズ、メモリー使用量データ (L3、SLM)、およびその他の情報を確認します。検出されたパフォーマンスの問題については、その解決方法を提供する [Recommendations (推奨事項)] タブを調べてください。
以下の例では、[Recommendations (推奨事項)] タブに、インテル® データセンター GPU マックス 1550 で実行される GPU カーネルに関する 2 つの提案が含まれています。以下を示しています。
- プライベート・メモリーが使用されています。
- SIMD ディレクティブがあります。
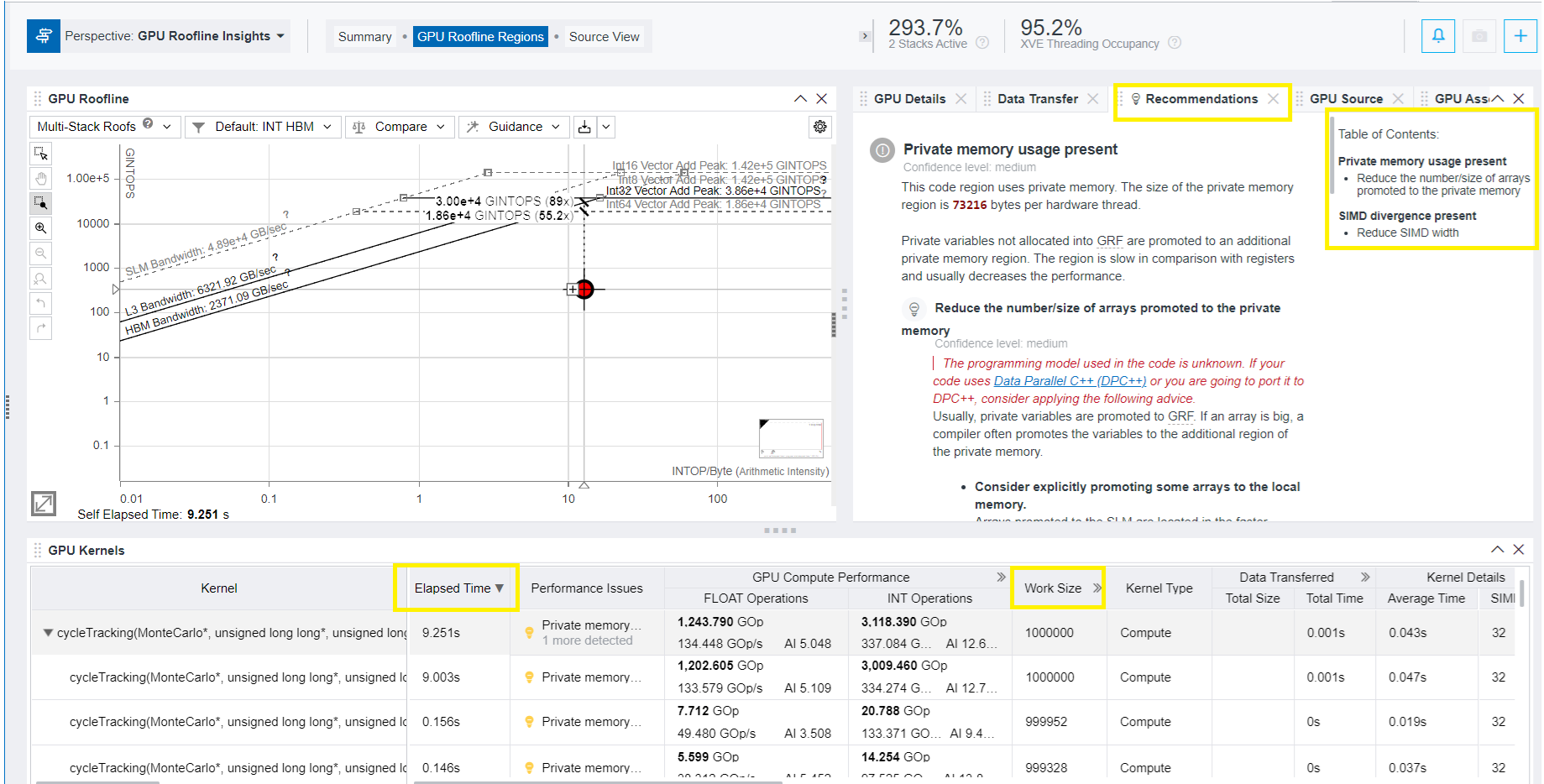
推奨事項を適用
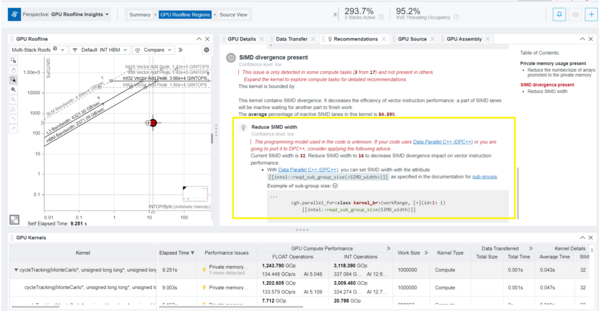
- 問題を調査し、それを解決する最適化手法を見つけるには、右側の目次で推奨事項を選択し、その詳細を調べます。下の図では、カーネルに SIMD の相違があり、ベクトル命令のパフォーマンスの効率が低下していることを示しています。この問題に対処するため、インテル® Advisor は SIMD 幅を小さくすることを推奨します。
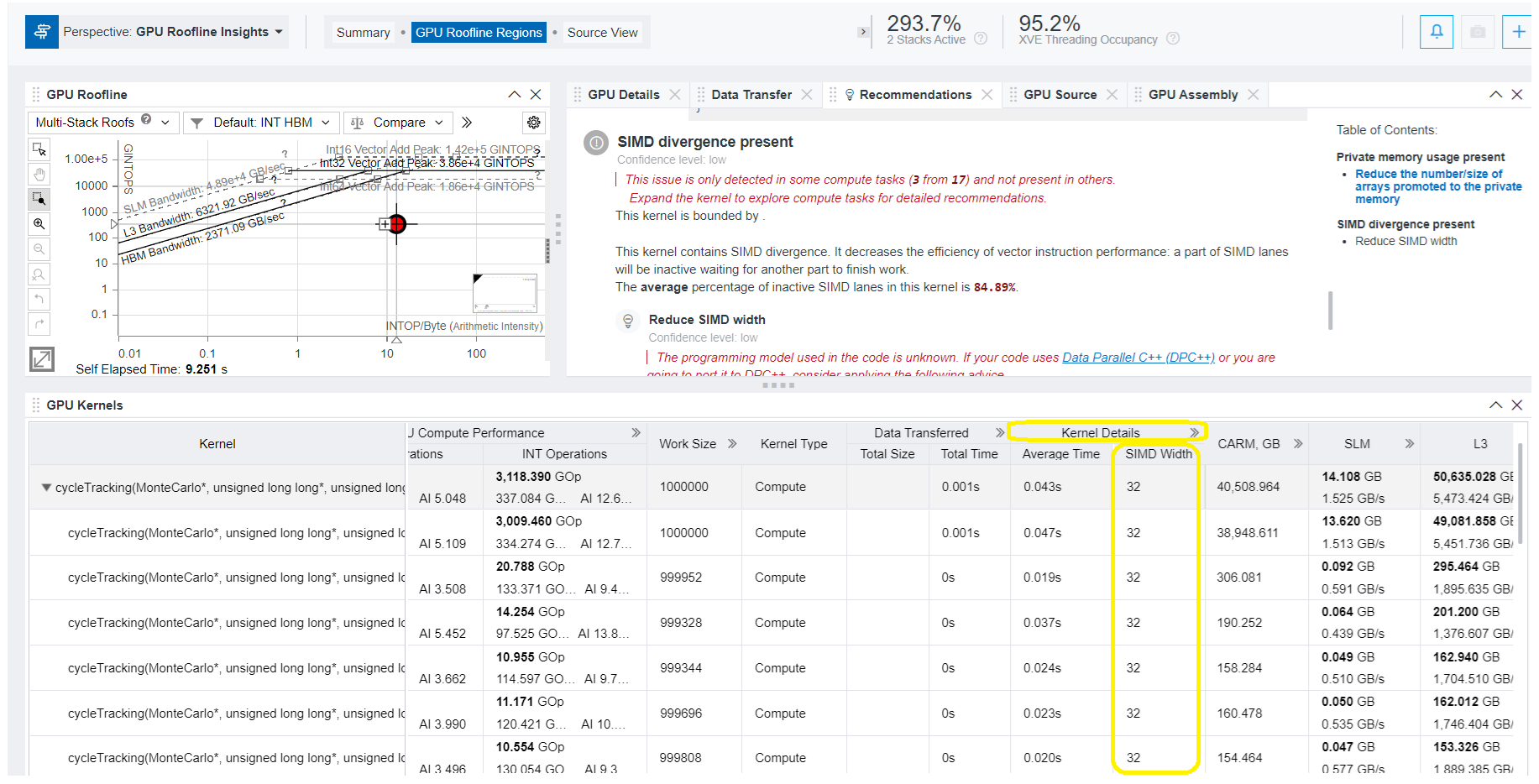
- カーネルで使用されている SIMD 幅を確認するには、[Kernel Details (カーネルの詳細)] の値を調べます。この例では 32 です。
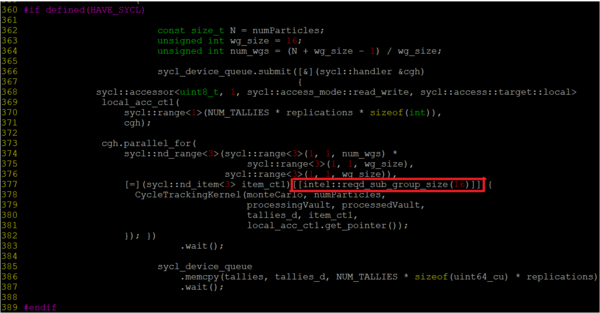
- 推奨事項を適用して SIMD 幅を縮小するには、カーネル呼び出しに以下を追加します。
[[intel::reqd_sub_group_size(<SIMD_width>)]]QuickSilver アプリケーションから main.cc.dpc.cpp ファイルを見つけて、次のように変更を加えます。
$ cd <quicksilver>/SYCL/src$ vi main.cc.dp.cpp下の図の例は、main.cc.dp.cpp を変更して SIMD 幅を 16 に設定する方法を示しています。
- 更新後にバイナリをリビルドします。
$ make -sj - 最新のバイナリーの [GPU Roofline Insights (GPU ルーフラインの調査)] パースペクティブを表示するには、次のコマンドを実行します。
$ QS_DEVICE=GPU advisor -collect roofline --profile-gpu -gpu-sampling-interval=0.1 --project-dir=qs_simd_16_change -- ./qs_simd_16 -i ../../Examples/AllScattering/scatteringOnly.inp - インテル® Advisor GUI で結果を調査します。
変更を検証してパフォーマンスへの影響を解析
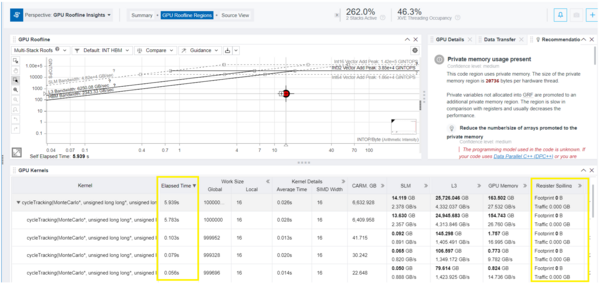
- [GPU Roofline Insights (GPU ルーフラインの調査)] パースペクティブの [GPU Roofline Regions (GPU ルーフライン領域)] タブで、GPU カーネルの [Elapsed Time (経過時間)]、[SIMD Width (SIMD 幅)]、[Register Spilling (レジスタースピル)] メトリックを確認します。
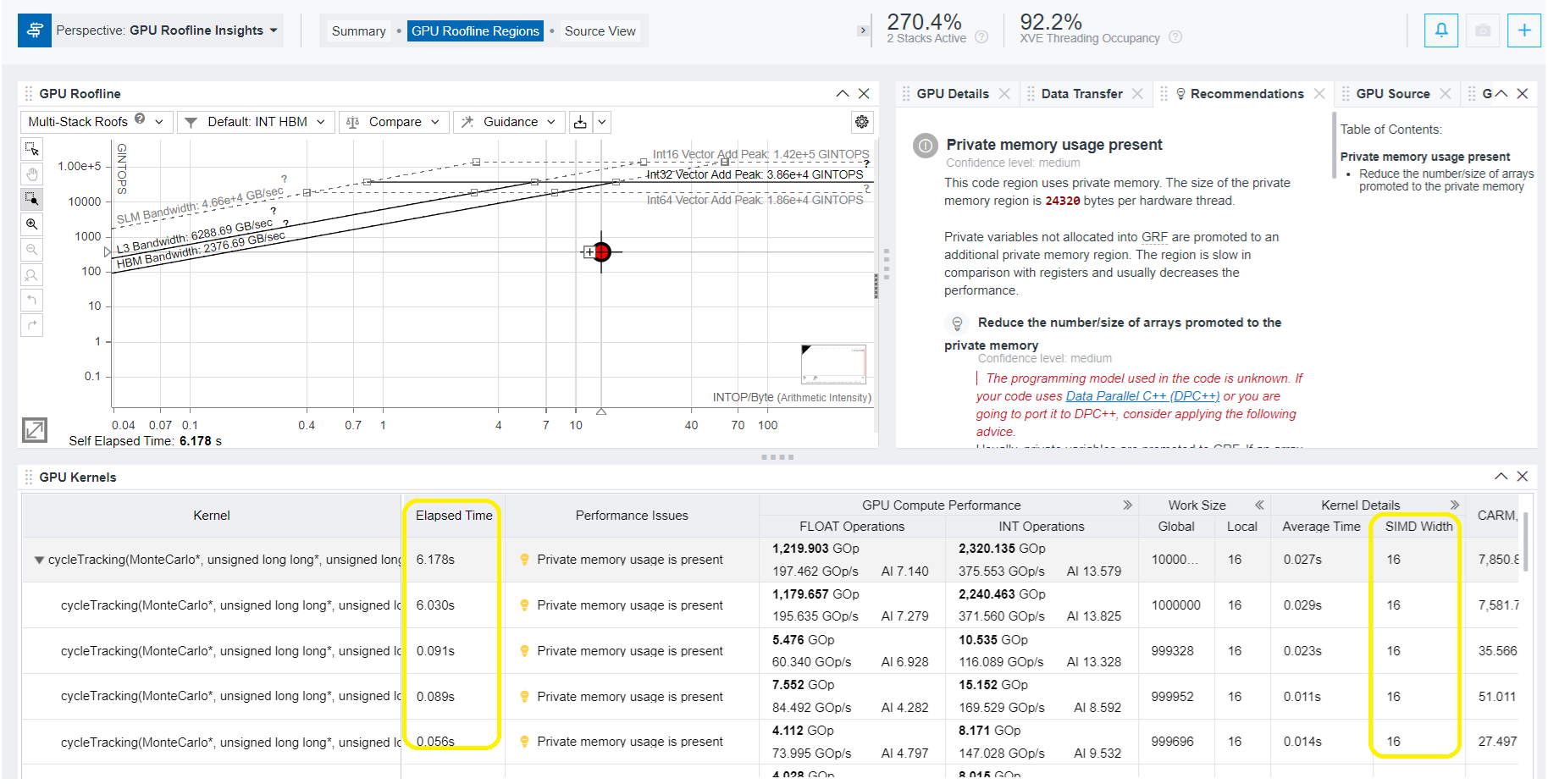
- [Kernel Details (カーネルの詳細)] で、SIMD Width (SIMD 幅) 値が 16 であることを確認します。この例では、最初のカーネル呼び出しの Elapsed Time (経過時間) は 9.003 秒から 6.030 秒に短縮されました。
レジスターのスピルを回避
[GPU Roofline Regions (GPU ルーフライン領域)] タブには、Register Spilling (レジスタースピル) メトリックも含まれています。レジスターのスピルがホットなループ内で発生すると、パフォーマンスが大幅に低下する可能性があります。変数をレジスターに格納していない場合、その変数へのアクセスによりメモリー・トラフィックが大幅に増加することがあります。この例では、このメトリックの値は 1408 B です。

デフォルトでは、スモール・レジスター・モード (128 GRF) が使用されます。レジスタースピルを回避するには、ラージ・レジスター・モード (256 GRF) を使用することを推奨します。これには以下を行います。
- このコマンドを CMake ファイルに追加します。
"-fsycl-targets=spir64 -Xs \"-options -ze-opt-large-register-file\" "
- バイナリーをリビルドします。
$ make -sj - 最新のバイナリーの [GPU Roofline Insights (GPU ルーフラインの調査)] パースペクティブを表示するには、次のコマンドを実行します。
$ QS_DEVICE=GPU advisor -collect roofline --profile-gpu -gpu-sampling-interval=0.1 --project-dir=qs_larger_grf_change -- ./qs_simd_16 -i ../../Examples/AllScattering/scatteringOnly.inp - インテル® Advisor GUI で結果を調査します。
- [GPU Roofline Insights (GPU ルーフラインの調査)] の [GPU Roofline Regions (GPU ルーフライン領域) タブで、ラージ GRF モードを適用した GPU カーネルの Elapsed Time (経過時間) と Register Spilling (レジスタースピル) メトリックを確認します。Register Spilling (レジスタースピル) 値が 0 B になり、Elapsed Time (経過時間) がさらに短縮されていることを確認します (この例では 6.030 秒から 5.763 秒に短縮)。
次のステップ
ルーフラインのパースペクティブから見た現在のワークグループのサイズは 16 です。この値を 32 または 64 に増やしてパフォーマンスへの影響を確認できます。
[GPU Roofline Regions (GPU ルーフライン領域)] タブには、プライベート・メモリーの使用状況に関するもう 1 つの推奨事項があり、変数にはグローバルメモリーではなくローカルメモリーを使用することが推奨されています。
