

この記事は、https://www.oneapi.io/spec/ で 2023年9月14日に公開された『oneAPI 1.3 Provisional Specification Rev. 1』 (HTML、PDF) をベースにしています。原文は2000 ページ近くあり、翻訳の時間とリソースも限られるため、全文翻訳ではなく、記事形式で区切った仕様とその解説を提供することにしました。
この回では、『oneAPI 1.3 Provisional Specification Rev. 1』の「oneDNN」の「Data Model」の節を取り上げています。
データモデル
oneDNN のデータは、さまざまなデータ タイプを保持および表現し、各種形式 (レイアウト) で格納できるメモリー・オブジェクトにストアされます。
データタイプ
oneDNN は複数のデータタイプをサポートします。oneDNN の基本タイプは 32 ビット IEEE 単精度浮動小数点データタイプです。これは、実装でサポートする必要がある唯一のデータタイプです。以下で説明するデータタイプはオプションです。
単精度浮動小数点データタイプで動作するプリミティブは、同じデータタイプの中間結果を生成し格納します。
また、単精度浮動小数点データタイプの精度は十分であるため、精度が混在した計算の中間結果を保持するのに利用されます。例えば、要素全体のプリミティブと要素全体の後処理では、常に内部で単精度浮動小数点データタイプが使用されます。
注: 暗黙のダウンコンバートによる計算の高速化は、fpmath モードで制御できます。
oneDNN は、次の列挙を使用してサポートするデータタイプを参照します。
enum class dnnl::memory::data_type
データタイプ仕様。
値:
enumerator undef – 未定義データタイプ (空のメモリー記述子に使用)。
enumerator f16 – 16 ビット半精度浮動小数点。
enumerator bf16 – 非標準 16 ビット浮動小数点 (7 ビット仮数)。
enumerator f32 – 32 ビット単精度浮動小数点。
enumerator s32 – 32 ビット符号付き整数。
enumerator s8 – 8 ビット符号付き整数。
enumerator u8 – 8 ビット符号なし整数。
oneDNN は、次のデータタイプによるトレーニングと推論をサポートします。
| 使用モデル | データタイプ |
|---|---|
| 推論 | dnnl::memory::data_type::f32、dnnl::memory::data_type::bf16、dnnl::memory::data_type::f16、dnnl::memory::data_type::s8、dnnl::memory::data_type::u8 |
| トレーニング | dnnl::memory::data_type::f32、dnnl::memory::data_type::bf16 |
注: 低い精度で演算を行うため、ディープラーニング・モデルの実装の変更を考慮しなければならないことがあります。
それぞれのプリミティブには、精度要件に基づくデータタイプのサポートに対し、個別の制限がある場合があります。プリミティブがサポートするデータタイプのリストは、仕様ガイドの関連する節に含まれています。
Bfloat16
注: この節では、可読性のためデータタイプの名称を省略しています。例えば、dnnl::memory::data_type::f32 は、f32 と表記されます。
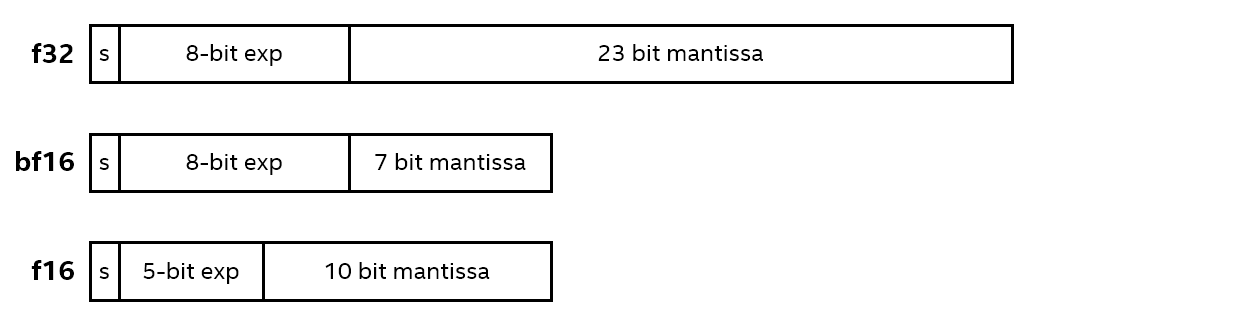
Bfloat16 (bf16) は、IEEE 32 ビット単精度浮動小数点データタイプ (f32) をベースとする 16 ビット浮動小数点データタイプです。
bf16 と f32 の指数部は 8 ビットです。ただし、f32 の仮数部は 23 ビットであるのに対し、bf16 では 7 ビットしかなく最上位ビットのみが保持されます。そのため、bf16 はデータタイプに近い数値範囲の値をサポートしますが、精度は大幅に低下します。従って、bf16 は f32と IEEE 16 ビット半精度浮動小数点データタイプ f16 の間に位置付けられます。5 ビットの指数部と 10 ビットの仮数部を持つ f16 と比較すると、bf16 は範囲を広げて精度を下げています。
bfloat16 データタイプの詳細については、こちら (英語) を参照してください。
f32 に対して bf16 を使用する利点は、メモリー使用量が減るためメモリー・アクセス・スループットが向上することです。
ワークフロー
f32 データタイプと bf16 データタイプを使用して訓練を実装する主な違いは、重みを更新する処理方法です。f32 データタイプでは、重み勾配のデータタイプは重み自体と同じです。oneDNN ではある程度の柔軟性を許容するため、これは必ずしも bf16 データタイプには当てはまりません。例えば、f32 ですべての重みのマスターコピーを保持して重みの勾配を計算し、結果を bf16 に変換することができます。
サポート
ほとんどのプリミティブでは、bf16 データタイプのソースと重みテンソルをサポートできます。デスティネーション・テンソルには、bf16 または f32 データタイプのどちらかを指定できます。後者は、bfloat16 をサポートしない操作、またはより高い精度を必要とする操作に出力を供給するケースを対象としています。
Int8
推論計算のパフォーマンスを向上させるため、最近のワークでは高いスループットを実現する低精度で格納された活性化と重みを採用する計算が注目されています。Int8 による計算は、精度の低下 (ただし許容範囲で) と引き換えにさらに多くの計算を単一命令にパックできるため、高精度のタイプと比べパフォーマンスが向上します。
ワークフロー
oneDNN は対称量子化モデルと非対称量子化モデルをサポートします。
量子化モデル
int8 テンソルごとに、oneDNN ライブラリーはスケーリング係数とゼロポイント (量子化パラメーターとも呼ばれる) を指定でき、次の数学的関係を想定します。
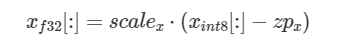
ここで、scalex は float 形式のスケーリング係数で、zpx は int32 形式のゼロポイント、そして配列に数式を要素ごとに適用する場合は [:] を使用します。最高のパフォーマンスを発揮するため、oneDNN はプリミティブ計算の一部であるこれらのスケーリング係数とゼロポイントを計算しません。これらは、ユーザーが属性メカニズム (英語) を通じて提供する必要があります。
これらの量子化パラメーターは、キャリブレーション・ツールを使用して事前に計算することも (静的量子化)、テンソルの最小値と最大値から実行時に計算することもできます (動的量子化)。量子化パラメーターは実行時に oneDNN プリミティブに渡されるため、どちらの方法でも oneDNN と組み合わせて使用できます。
int8 の量子化をサポートするには、次のようにプリミティブを作成し実行する必要があります。
プリミティブを作成する際に、1 つまたは複数の入力が int8 (符号付きまたは符号なし) である場合、プリミティブは量子化された整数演算として動作します。
プリミティブの作成中にも、スケーリング係数とゼロポイントの次元はマスクを介して提供される必要があります (例: テンソルごとに 1 つのスケール、チャネルごとに 1 つのスケールなど)。
最後に、プリミティブの実行中に、ユーザーは実際の量子化パラメーターを引数として実行する関数に渡す必要があります。スケールは f32 値、ゼロポイントは int32 値とします。
注: パフォーマンス上の理由から、それぞれのプリミティブの実装は、量子化パラメーター・マスクのサブセットのみをサポートします。例えば、通常、畳み込みは重みチャネルごとのスケール (ゼロポイントなし) と、活性化のテンソルごとのスケーリング係数とゼロポイントをサポートします。
注: 一部のプリミティブは、中間値を逆量子化/量子化するため、量子化パラメーターを使用することがあります。これは、非線形関数を適用する前に逆量子化され、行列乗算を実行する前に再量子化される RNN プリミティブ (英語) に当てはまります。
数値的な動作
プリミティブの実装では、int8 入力を int16 や int32 などのより広範囲のデータタイプに変換することが許されています。この変換は精度には影響しません。
実行中、プリミティブは整数のオーバーフローを回避し、中間値とアキュームレーターに広範囲のデータタイプ (int32 など) を使用して整数の精度を維持する必要があります。これは、結果が出力メモリー・オブジェクトに書き込まれる前に、必要に応じて変換されます。変換中にアンダーフローやオーバーフローが発生すると、動作は未定義となります (例: s32 を int8 に変換など)。実装では、値を飽和させるとこが推奨されます。
ポスト操作メカニズム (英語) を使用して複数の演算が単一のプリミティブに融合される場合、それらは f32 精度で計算されると推測されます。その結果、ディストリビューション量子化パラメーターは、ポスト操作の後で次のように適用されます。
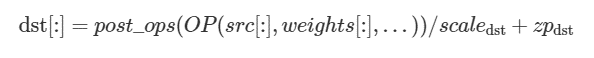
ポスト操作間の量子化/逆量子化は、要素単位のポスト操作 (英語)、バイナリーポスト操作 (英語)、または適切なポスト操作のスケーリング・パラメーターのいずれかを使用して実現できます。
例: 畳み込み量子化のワークフロー
バイアスなしの畳み込みを考えてみます。テンソルは次のように表現されます。
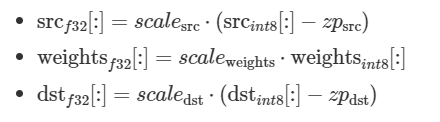
ここで、srcf32、weightsf32、dstf32 は計算されず、ワーク全体が int8 テンソルで実行されます。そのため、タスクは実行時渡される src_{int8}、weights_{int8} テンソルを使用して dstint8 テンソルを計算します。対応する量子化パラメーターとして、scale_{src}、scale_{weights}、scale_{dst} および zero_point{src}、zero_point_{dst} があります。数学的には次のように計算します。
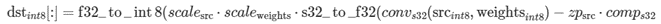
説明:
convs32は、int8 データタイプでソースと重みを取得し、結果を int32 データタイプで計算する通常の畳み込みです (int32 は計算中のオーバーフローを回避するために使用されます)。comps32は、srcの非ゼロのゼロポイントを考慮する補間項です。この項は、oneDNN プリミティブによって計算され、通常は重みの並べ替えを行う際に事前計算できます。f32_to_s8()は、値が int8 データタイプの範囲外にある場合、f32 値を飽和して s8 に変換します。s32_to_f32()は、潜在的な丸めにより int8 値を f32 に変換します。この変換は通常、f32 スケーリング係数を適用する際に必要になります。
チャンネルごとのスケーリング
プリミティブは、量子化テンソルの複数スケールのサポートが制限されていることがあります。最も一般的な使い方は、重み出力チャンネルごとのスケーリング係数をサポートする畳み込みと逆畳み込み (英語) プリミティブです。実際の畳み込み計算では、異なる出力チャンネルに異なるスケーリングを行う必要があります。
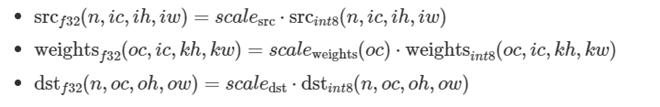
ここで、weights’ スケーリング係数は oc 依存であることに注意してください。
dstint8 を計算するには、以下を行う必要があります。
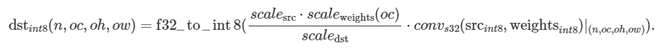
ユーザーは、それぞれに量子化された重みを用意する必要があります。そのため、oneDNN ではチャネルごとのスケーリングを行う並べ替えが提供されています。
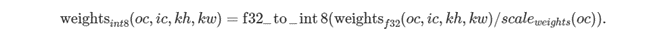
量子化 (英語) では、oneDNN がサポートする量子化モデルの種類を説明します。
サポート
oneDNN は、プリミティブの入力および出力メモリー・オブジェクトを int8 データタイプに指定できるようにすることで、推論で int8 計算をサポートします。
法務上の注意書き
The content of this oneAPI Specification is licensed under the Creative Commons Attribution 4.0 International License (英語). Unless stated otherwise, the sample code examples in this document are released to you under the MIT license (英語).
This specification is a continuation of Intel’s decades-long history of working with standards groups and industry/academia initiatives such as The Khronos Group*, to create and define specifications in an open and fair process to achieve interoperability and interchangeability. oneAPI is intended to be an open specification and we encourage you to help us make it better. Your feedback is optional, but to enable Intel to incorporate any feedback you may provide to this specification, and to further upstream your feedback to other standards bodies, including The Khronos Group SYCL* specification, please submit your feedback under the terms and conditions below. Any contribution of your feedback to the oneAPI Specification does not prohibit you from also contributing your feedback directly to other standard bodies, including The Khronos Group under their respective submission policies.
By opening an issue, providing feedback, or otherwise contributing to the specification, you agree that Intel will be free to use, disclose, reproduce, modify, license, or otherwise distribute your feedback at its sole discretion without any obligations or restrictions of any kind, including without limitation, intellectual property rights or licensing obligations.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice.
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
