

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Performance Insights to Intel® Hyper-Threading Technology (http://software.intel.com/en-us/articles/performance-insights-to-intel-hyper-threading-technology/)」の日本語参考訳です。
要旨
インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー)¹ は、インテル® アーキテクチャーに基づく多くのサーバーおよびクライアント・プラットフォームでサポートされているハードウェア機能であり、1 つのプロセッサー・コアで 2 つのソフトウェア・スレッドを同時に実行することを可能にします。
「同時マルチスレッディング」としても知られるインテル® HT テクノロジーは、スループットを高め、電力効率を向上させます。最初に HT テクノロジーが導入されたインテル® Pentium® 4 プロセッサー世代に比べ、インテル® HT テクノロジーがもたらす恩恵は、Nehalem✝ コアベースのインテル® Core™ i7 プロセッサーやほかのプロセッサー (インテル® Xeon® プロセッサー 5500 番台を含む) に一層活かされており、幅広い用途にわたって、より良いパフォーマンスと電力効率の向上を生み出しています。
あらゆるハードウェア機能がそうであるように、すべてのソフトウェアがこのテクノロジーの恩恵を享受できるわけではありません。詳細は、「制限の理解とパフォーマンスの最大化」というセクションを参照してください。
本資料では、インテル® HT テクノロジーがどのように機能するかを説明し、クライアント、ワークステーション、およびサーバーで動作するいくつかの分野におけるソフトウェアのパフォーマンス結果を示します。インテル® HT テクノロジーのパフォーマンス評価方式を紹介するとともに、パフォーマンス低下の分析についても記述しています。ある特定のアプリケーションについてインテル® HT テクノロジーの効果を測定する方法と、本テクノロジーを最大限に活用するためにどのように使用するべきか (または使用するべきではないか) について、ソフトウェア開発者とエンドカスタマーの双方に向けた指針を提供します。
ここではインテル® 64 アーキテクチャーに言及しており、特に Nehalem✝ コアをベースとするインテル® プロセッサー (インテル® Core™ i7 プロセッサー、インテル® Xeon® プロセッサー 5500 番台など) に重点を置いています。本資料の内容は、Nehalem✝ コアに由来する新しいインテル® プロセッサー SandyBridge✝ にも適用されますが、インテル® Atom® プロセッサー・ファミリーおよびインテル® Itanium® プロセッサー・ファミリーは、インテル® HT テクノロジーの実装方式が著しく異なるため、これらには適用されません。
インテル® HT テクノロジーのハードウェア機構
インテル® HT テクノロジーは、1 つの物理プロセッサー・コアで 2 つの論理コアを、オペレーティング・システム (OS) に対して提示できるようにします。これにより、1 つのコアで、2 つのスレッドを同時にサポートできるようになります。この機能の下層にある鍵となるハードウェア機構は、図 1 に示すように、ハードウェアがサポートする「もう 1 つのアーキテクチャー・ステート」です。

図 1. インテル® HT テクノロジーにより 1 つのプロセッサー・コアでそれぞれ個別のスレッドをサポートする 2 つのアーキテクチャー・ステートを維持可能。内部の多くのマイクロアーキテクチャーのハードウェア・リソースは、この 2 つ のスレッド間で共有されます。
図 2 は、Nehalem✝ コアベースのプロセッサーの複数のコアを示すブロック図です。インテル® HT テクノロジーが有効になっている場合は、複数のコアがそれぞれ 2 つのスレッドを持ちます。インテル® マイクロアーキテクチャー Nehalem✝ ベースのプロセッサーには、図に示すように、可変数のコアが存在します。
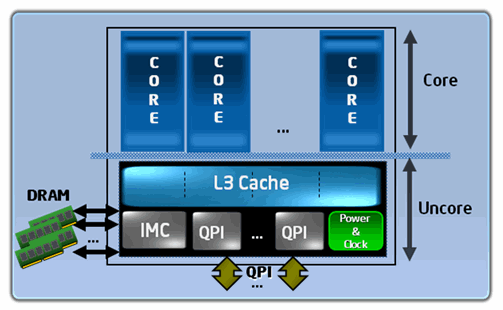
図 2. インテル® Core™ i7 プロセッサーや同様のアーキテクチャーのプロセッサーは可変数のコアを持つことができ、インテル® HT テクノロジーが有効な場合はコアごとに 2 つのスレッドに対応可能
プロセッサーは、各スレッドに対して個別の、完全なアーキテクチャー・ステートを維持します。アーキテクチャー・ステートには、インテル® 64 アーキテクチャーで定義されている専用のレジスターセットが含まれています。
オペレーティング・システム (OS) は、各スレッドがそれぞれ専用のコアで動作している場合と同じようにスレッドを管理し、OS からは、あたかも各スレッドが専用の物理コアで動作しているかのように見えます。一部の内部的なマイクロアーキテクチャー構造はスレッド間で共有されます (表 1 参照)。

表 1: インテル® マイクロアーキテクチャー Nehalem✝ はコアごとに 4 種類の実装ポリシー (Replicated (複製)、Partitioned (分割)、Competively Shared (競合的共有)、Unaware (影響なし)) を使用してスレッドリソースを処理
インテル® マイクロアーキテクチャー Nehalem✝ ベースのプロセッサーの実行パイプラインには、命令 4 つ分の幅があります。つまり、クロックサイクルあたり最大 4 つのマイクロオペレーションを実行できます。
しかしながら、図 3 に示すように、実行中のソフトウェア・スレッドで同時実行可能な命令が 4 つ揃っていないことがよくあります。クロックあたりにリタイアされる命令が 4 つに満たない一般的な理由として、1 つの命令の出力とほかの命令の入力間にある依存関係や、データがキャッシュまたはメモリーからフェッチされるまでのレイテンシーが挙げられます。
インテル® HT テクノロジーは、独立した命令ストリームを持つ 2 つのスレッドを持ち、スレッド間のデータ依存性を排除し、有効な実行ユニットの使用率を上げることによって、命令レベルの並列性を高めて、パフォーマンスを改善します。その結果、通常は、コアで一定時間内に実行される命令の数が増えます (図 3 参照)。これにより、ユーザーはスループットの向上 (クロックサイクルあたりの作業完了量が増えるため) とワットあたりのパフォーマンス改善 (パフォーマンスに貢献せずに電力を消費するアイドル実行が減るため) が得られます。
さらに、1 つのスレッドでキャッシュミス、条件分岐命令の予測ミス、その他のパイプラインのストールが発生しても、もう一方のスレッドは、同じコアで単一スレッドを実行するの場合とほぼ同じ速度で命令の処理を続行できます。インテル® HT テクノロジーは、わずかなシリコン上のスペースおよび生産コストによって、他の先進的なアーキテクチャー機能、クロック速度向上、および追加のコアを補強します。
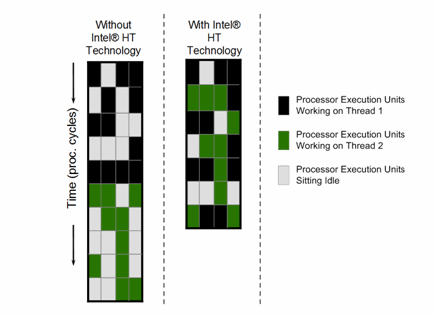
図 3. プロセッサーが同じタイムスライス内で 2 つのスレッドにアクセスできるようにすることで、インテル® HT テクノロジーはアイドル状態のハードウェア・リソースを減らし、効率とスループットを向上させる
インテル® HT テクノロジーは、インテル® Pentium® 4 プロセッサーなどの Intel NetBurst® マイクロアーキテクチャーで初めて実装され、その主要な機能は現世代のプロセッサーでもほぼ同じものが実装されていますが、表 2 に集約されるような改善に伴い、マイクロアーキテクチャー全体のパフォーマンスが進化したことで、現在のプラットフォームにおいてインテル® HT テクノロジーの有効性が飛躍的に高まりました。

表 2: インテル® Pentium® 4 プロセッサーと Nehalem✝ コアのアーキテクチャー上の主な相違点
インテル® HT テクノロジーのソフトウェアにおける使用
あるソフトウェア・アプリケーションが特定のハードウェア機能によって得られるパフォーマンスの向上は、そのソフトウェアの特性と、ソフトウェアがその機能をどのように活用するかに依存します。例えば、プロセッサーのキャッシュを効率良く利用するアプリケーションは、メモリーバンド幅が増えてもその恩恵を受けることがありません。
同様に、アプリケーションが特定の機能からどの程度のメリットを得られるかは、その機能がアプリケーションをどの程度補完するかに依存します。プロセッサーによってアプリケーションに与える処理速度の影響度が異なる理由はここにあります。
これは、インテル® HT テクノロジーにもいえることです。インテル® HT テクノロジーの利用により得られるパフォーマンスの向上は、プロセッサー自身の設計のみならず、実行するソフトウェアの特性にも依存します。インテル® HT テクノロジーによるパフォーマンスの向上に必要なアプリケーションの特性を知ることは、ソフトウェア開発者にとってもエンドユーザーにとっても役立ちます。以下に、必要な特性を示します。
- アプリケーションが並列実行向けに設計されている。つまり、アプリケーションがマルチスレッド化され、複数のプロセスで実行可能である、あるいはそのいずれかです。複数のプロセスを持つアプリケーションは通常、個々のタスクを並列で実行します。スレッド化されているアプリケーションは、タスクを分割し、複数のソフトウェア・スレッドで並列に実行することができます。この種類のスレッド化モデルは、ドメイン分解またはデータ分解と呼ばれます。ほかのスレッド化モデルもありますが、ドメイン分解は多くの場合、アプリケーションが自らを調整して、複数のハードウェア・スレッドを持つ各種プラットフォームで動作できるようにするため、最も柔軟性があります。スレッド化については、インテル® ソフトウェア・ネットワークの Parallel Programming and Multi-Core™ Developer Community (http://software.intel.com/en-us/multi-core/ (英語)) を参考にしてください。
- アプリケーションがハードウェア・スレッド数に応じてスケーリングする。多くのアプリケーションには、それ以上ソフトウェア・スレッドを生成しても、パフォーマンスの向上につながらない限界点があります。これは、アプリケーションやシステム、あるいはその両方のボトルネックによります。システムリソースのボトルネックに影響を受けるアプリケーションの設計上のボトルネックが存在する場合、さらに多くのスレッドを生成しても、パフォーマンスは向上せず、むしろオーバーヘッドが増大し、パフォーマンスが低下する可能性があります。インテル® HT テクノロジーによりアプリケーションを十分にスケーリングさせるためには、コア数の増加に対応する優れたスケーリングが必要です。そのためには、アプリケーションを最適化して、十分にスケーリングさせるための各種ツールを利用します。例えば、インテル® VTune™ Analyzer XE は、ボトルネック、ロードバランスの問題、および並列処理の可能性を特定するのに役立ちます。
- アプリケーションでハードウェアの並列機能を最大限に活用する。アプリケーションは、適切な数のソフトウェア・スレッドを生成することで、ハードウェアの並列機能を最大限に活用できます。ほとんどの場合、これは「フルサブスクリプション 」モデルを利用することを意味します (ハードウェア・スレッドと同数のソフトウェア・スレッドを使用)。特にサーバータイプのアプリケーションでは、オーバーサブスクリプション (ハードウェア・スレッドの数よりもソフトウェア・スレッドの数が多い) にするとパフォーマンスが向上することがあります。アンダーサブスクリプション (ハードウェア・スレッドの数よりもソフトウェア・スレッドの数が少ない) は、プラットフォームの並列機能を十分に活用しておらず、パフォーマンスの低下につながる恐れがあります。前述のとおり、ソフトウェア・スレッド数を増やす前に、アプリケーションがスケーリング可能であることを確認する必要があります。OS の API または CPU のポロジー判定ルーチンを使用して、適切な数のソフトウェア・スレッドを生成してください。
インテル® HT テクノロジーのパフォーマンスの測定と分析
コアとインテル® HT テクノロジー・スレッドの識別
OS は、どのスレッドが同じコアに配置されているかは通知しません。図 4 の Windows* タスク マネージャーのスクリーンショットは、システムで実行されている 4 つのスレッド (インテル® HT テクノロジーが有効な 2 つのコア) を表示していますが、 どのスレッドがどのコアに属しているかは示されていません。ここでは Linux* の画面はありませんが、Linux* の場合も同様です。
この図では、2 つ目と 4 つ目のハードウェア・スレッドが最も利用されています。これらのハードウェア・スレッドは同じコアにあるインテル® HT テクノロジー・スレッドでしょうか。あるいは別々のコアにあるものでしょうか。これは、タスク マネージャーでは分かりませんが、別の方法でどのスレッドがどのコアに属しているのかを判定できます。
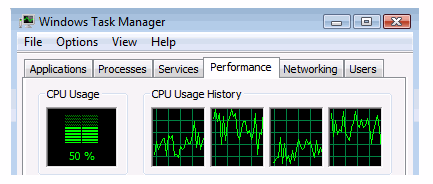
図 4. インテル® HT テクノロジーが有効なインテル® Core™ i7 プロセッサー (Nehalem✝ コア) ベースのシステムで 2 つのソフトウェア・スレッドを実行中のアプリケーションを示す Microsoft* Windows* タスク マネージャー
CPUID インターフェイスと APIC ID を使用して CPU トポロジーを列挙することにより、別々のコアなのか、同じコアにあるインテル® HT テクノロジー・スレッドなのかを識別できます。各論理プロセッサーには固有の ID が割り当てられます。CPUID は、APIC ID (図 5 参照) を各階層レベルに対応するサブフィールドに分解するインターフェイスを提供します。サンプルプログラムと詳しい説明については、『Intel® 64 Architecture Processor Topology Enumeration』 (http://software.intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration/) を参照してください。
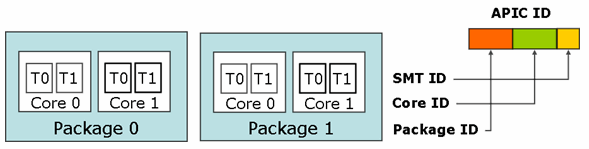
図 5. それぞれのハードウェア・スレッドには固有の APIC ID が付いている
コアおよびインテル® HT テクノロジー・スレッドの使用率のロギング
スレッドとコアのマッピングを理解すれば、一般的な OS ユーティリティー (perfmon/typeperf/sar など) を使用して CPU アクティビティーのログをとり、それをハードウェア・スレッドとコアにマッピングできます。このアプローチにより、別々のコアではなく、同じコアにあるインテル® HT テクノロジー・スレッドが利用されているかどうかを知るデータが得られます。図 6 および 7 に示すように、Microsoft* Typeperf* ユーティリティー (http://technet.microsoft.com/en-us/library/bb490960.aspx) では、ハードウェア・スレッドごとの CPU 使用率のログをとることができます。
図 6. Microsoft* Typeperf* ユーティリティーの実行
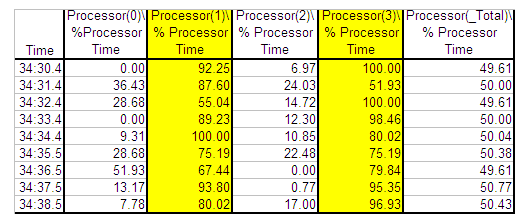
図 7. ハードウェア・スレッドごとの CPU 使用率が示されている TypePerf 出力 (foo.csv file)
Perfmon および sar 出力の解釈
Perfmon および sar は、それぞれ Windows* OS および Linux* OS に付属するユーティリティーで、CPU 使用率のデータを提供します。インテル® HT テクノロジーを有効/無効に切り替えることで、興味深い動作が見られるでしょう。これらのツールは単純に、システム内の各プロセッサーのアクティブ時間をカウントし、それを (ユーザーが設定可能な) 一定の期間に基づいてレポートします。また、合計 CPU 使用率 (%) もレポートします。これは単純に、その期間の全 CPU の平均値です。
ここでいう CPU 使用率とは、実際には CPU 使用率の平均値であることに注意してください。スレッド単位では、1 つのスレッドがそのときにコードを実行しているか、またはアイドル状態であるかのいずれかです。どちらのツールも、特定の期間において、そのスレッドがアクティブとなった時間の割合 (%) の平均を示します。合計使用率は、例えば、そのときにスレッドのうち 3 つがアイドル状態で 1 つがアクティブ状態であれば、25 パーセントの使用率になることが見込まれます。
ここでは、インテル® HT テクノロジー対応のデュアルコア・プロセッサーを例に考えてみましょう。perfmon も sar も、インテル® HT テクノロジーが無効な場合は 2 つの CPU、有効な場合は 4 つの CPU の CPU 使用率をレポートします。
サンプル・パフォーマンス・データの分析
以下の例では、1 コアで 1 スレッドが動作する場合と比べ、1 コアで 2 スレッドが動作する場合、インテル® HT テクノロジーによりパフォーマンスが 1.25 倍向上すると仮定します。さらに、同じコアで実行中のスレッドが 1 つだけの場合は、毎秒 1 作業単位 (1 u/s) の能力があると想定します。
図 8 に示すケースでは、それぞれ個別のコアで動作する 2 つのスレッドが、どちらも 100% の使用率で動作しています。perfrmon と sar によって計算される合計 CPU 使用率は 100%、つまり (100+100)/2 で、このシステムは毎秒 2 作業単位 (2 u/s) を完了します。
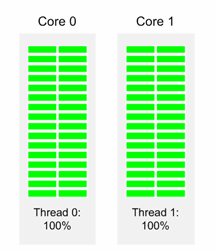
図 8. インテル® HT テクノロジーが無効で、2 つのスレッドがどちらも 100% の使用率で動作しているシステム
図 9 に示すケースでは、2 つのスレッドが 100% の使用率で動作し、2 つのスレッドがアイドル状態にあります。そして、アクティブなスレッドはそれぞれ個別のコアで動作していることが分かります。perfrmon と sar によって計算される合計 CPU 使用率は 50%、つまり (100+0+100+0)/4 で、このシステムも、やはり、毎秒 2 作業単位 (2 u/s) を完了します。
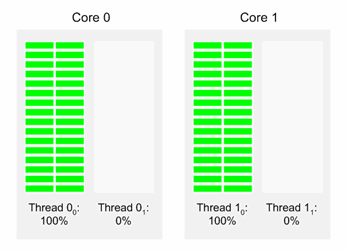
図 9. インテル® HT テクノロジーが有効で、2 つのスレッドが 100% の使用率で動作し、2 つのスレッドがアイドル状態 (0% の使用率) のシステム。それぞれのコアには、使用率 100% の論理プロセッサーと 0% の論理プロセッサーが 1 つずつある。
図 10 に示すケースでは、2 つのスレッドが 100% の使用率で動作し、2 つのスレッドがアイドル状態にあります。そして、アクティブなスレッドが同じコアで動作していることが分かります。perfrmon と sar によって計算される合計 CPU 使用率は 50%、つまり (100+100+0+0)/4 で、このシステムは毎秒 1.25 作業単位 (1.25 u/s) を完了します。(仮定したワークロードが 1 スレッドにつき 1 u/s で、インテル® HT テクノロジーによりパフォーマンスが 1.25 倍に向上するため、1.25 u/s となる)。
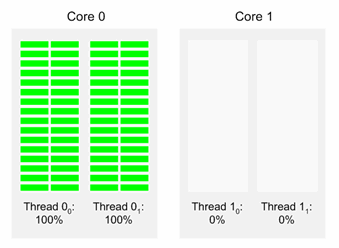
図 10. 図 9 と同様に、インテル® HT テクノロジーが有効で、2 つのスレッドが 100% の使用率で動作し、2 つのスレッドがアイドル状態 (0% の使用率) のシステム。ただし、1 つのコアには 100% で動作するスレッドが 2 つあり、もう一方のコアには 0% のスレッドが 2 つある。
ここで注意しなければならないのは、図 9 および 図 10 のどちらのケースについても、Perfmon と sar はともに合計平均 CPU 使用率を 50% とレポートしますが、毎秒あたりの作業量は大きく異なります (2 u/s 対 1.25 u/s)。
上記の例から、次の 3 つの事が分かります。
- パフォーマンスを最大限に引き出すためには、同じコアのスレッドにスケジュールするより、ほかのコアにスケジュールしたほうが良いでしょう。これは OS にまかせるのが最善です。すべてのマルチスレッド OS はインテル® HT テクノロジーをサポートしており、最近のバージョンでは、パフォーマンスを最大限に引き出すために最も理想的な方法でスレッドをスケジュールできるよう、より多くのサポートが提供されています。
- CPU 使用率は、システムの負荷やシステムが追加作業用に残してあるヘッドルームの推定には適していません。図 9 および図 10 から分かるように、どちらも 50% の使用率をレポートしますが、実際に行われる作業量は、スレッドのスケジュールによって異なります。図 9 のシステムが実行しているのは 2 u/s であり、図 10 のシステムが実行しているのは 1.25 u/s です。
- CPU 使用率を基に作業量をスケーリングし、使用率 100% のスループットを見積もる方法では、システムの最大スループットを正確に見積もることはできません。この方法は、インテル® HT テクノロジーの有無にかかわらず、一般に困難が伴います。
CPU のヘッドルーム、あるいは CPU の使用率低下の測定に対するインテル® HT テクノロジーのパフォーマンス測定と時間またはレートのパフォーマンス評価基準
ほかのアプリケーションの中間層として使用されるアプリケーションについて考えてみましょう。便宜上、この中間層のアプリケーションを AppX と呼ぶことにします。
AppX の開発者は、CPU 使用率を最小に抑えることに努め、何年もの間、CPU 使用率をパフォーマンス指標の 1 つとしてきました。ここで CPU 使用率とは、AppX の実行中にサードパーティー・アプリケーションで使用可能な CPU ヘッドルームがどの程度あるかを意味します。図 11 は、インテル® Core™ i7 でインテル® HT テクノロジーを有効/無効にした場合の AppX の CPU 使用率のデータを示したものです。
このデータから、開発者は、CPU 使用率が 45.5% から 21.6% に低下していたため、インテル® HT テクノロジーにより AppX のパフォーマンスが 2 倍以上になったと勘違いしました。

図 11. AppX の CPU 使用率。このデータから、インテル® HT テクノロジーによりパフォーマンスが 2 倍向上したとの勘違いが発生。
インテルのエンジニアを交えた議論の結果、AppX の開発者は、CPU 使用率がインテル® HT テクノロジーによるパフォーマンス向上を測定するための最善の方法ではなかったことに気付きました。
AppX は、インテル® HT テクノロジーを有効にしても無効にしても、同じ数のソフトウェア・スレッドを使用していたのです。CPU 使用率の違いは、実行時にインテル® HT テクノロジーのスレッドが使用されていたかどうかを示したものに過ぎませんでした。つまり、ほかのハードウェア・スレッドの平均 CPU 使用率は、インテル® HT テクノロジーの有効/無効にかかわらず、同じだったのです。CPU の使用率が半減したというのは確かですが、スピードが 2 倍になったわけではありません。
インテル® HT テクノロジーによるスピードアップを正確に評価するため、AppX の開発者は、使用されるハードウェア・スレッドの数までスケーリングするいくつかの顧客のマルチスレッド・アプリケーションを実行してみました。インテル® HT テクノロジーを有効/無効の設定にし、(CPU 使用率ではなく) 時間またはレートなどのパフォーマンス評価基準を使用して、これらのアプリケーションをテストしました。インテルでは、経過時間または単位時間あたりの作業量によって、最適化によるパフォーマンスの変化を評価することを推奨しています。
レイテンシー対スループット
インテル® HT テクノロジーがパフォーマンスにどのような影響を与えるのか理解するため、4 コアを搭載したシングルソケットのインテル® Core™ i7 プロセッサー・ベースのシステムについて考えてみましょう (ソケットの数が 2 つ以上でも、またソケットあたりのコアの数がこれより多くても少なくても、同じことがいえます)。
インテル® HT テクノロジーが無効な場合、4 つのスレッドがそれぞれのプロセッサー・コアで 1 つずつ実行されます。インテル® HT テクノロジーを有効にすると、プロセッサー・コアあたり 2 スレッドに増えます。すべての CPU スレッドの使用率を 100% に維持できるだけの十分な数のスレッドを生成するアプリケーションが実行され、また、すべてのスレッドが互いに独立していると仮定します。(これは多くのアプリケーションにとって、とりわけサーバーでは妥当な仮定です。これが当てはまらないアプリケーションについても後で検証します。)
インテル® HT テクノロジーが無効で、4 つのスレッドがそれぞれ毎秒 1 作業単位を行うと仮定してみましょう。つまり、このシステムで実行される毎秒あたりの作業単位 (u/s) は 4 です。また、このアプリケーションは良好なスケーリングを示していると仮定します。前述の仮定を使用したさまざまなケースを以下に示します。
ケース 1: インテル® HT テクノロジーが有効な場合 (ソフトウェア・スレッド数 = 8): パフォーマンスの向上なし
最初に、インテル® HT テクノロジーによるパフォーマンスの向上を 0 と仮定した場合のアプリケーションへの影響を考えます。この場合、同時に実行されるスレッドの数は 2 倍になります。パフォーマンスの向上がないということは、各スレッドが 2 秒ごとに 1 作業単位を完了することになり、毎秒あたりの作業単位 (u/s) は 0.5 となります。言い換えれば、それぞれのスレッドで同量の作業を完了するのにかかる時間が 2 倍になりますが、スレッドの数が 2 倍になっているので、全体的なスループットは同じです。
ケース 2: インテル® HT テクノロジーが有効な場合 (ソフトウェア・スレッド数 = 8): パフォーマンスが 1.25 倍向上
このケースでは、インテル® HT テクノロジーが有効で、アプリケーションは 8 スレッドで実行されます。パフォーマンスは、インテル® HT テクノロジーが無効になっている場合と比べて 1.25 倍向上します。
1 スレッドの 1 作業単位の実行にかかる時間への影響はどうでしょうか。インテル® HT テクノロジーが無効な場合のパフォーマンスは 4 u/s でしたが、インテル® HT テクノロジーが有効になったことで 4 * 1.25 = 5.0 u/s になりました。8 スレッドあるため、1 スレッドで 1 作業単位を完了するための時間は 8 / (5.0 u/s) = 1.6 秒 となります。このケースでは、スループットが 25% 向上し、スレッドのレイテンシーは 1.6 秒に向上しています。
インテル® HT テクノロジーが有効な場合、さまざまなサーバーのワークロードにおいて応答時間が増えるように思われがちですが、一般にはそうではありません。CPU 時間は増えますが、通常、OS のキュー内の待ち時間が減少します。これについては、後ほど説明します。インテル® HT テクノロジーがエンドユーザーのサーバー応答時間に与える影響についての詳細は、『Hyper-Threading: Be Sure You Know How to Correctly Measure Your Server’s End-User Response Time』 (英語) を参照してください。
インテル® HT テクノロジーによるさまざまなパフォーマンス向上について、インテル® HT テクノロジーが有効な場合と無効な場合の実行スレッドの相対的な計算レイテンシーを図 12 に示します。すべてのスレッドが 100% 使用された場合のみ、このグラフに示す結果が得られます。
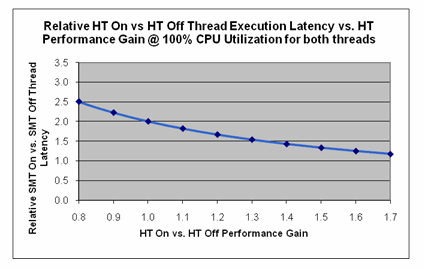
図 12. インテル® HT テクノロジーが有効な場合に達成可能なパフォーマンスの向上に対する単一スレッドの実行レイテンシーの変化
補足: このグラフに示すスレッドのレイテンシーとパフォーマンスの向上は、CPU 使用率が 100%、またはほぼ 100% である場合にのみ得られます。
コア CPI (Cycles Per Instruction) とスレッド CPI
CPI (Cycles Per Instruction) は、一定の期間内に所定の数の命令を実行するのに必要なクロックサイクル数の平均で、単純にその期間のクロックサイクル数 ÷ 命令数で計算されます。
コードセクション内のすべての CPI は、多くの要因の影響を受けます。例えば、コードにおける命令レベルでの並列性の割合などがあります。Nehalem✝ コアベースのプロセッサーは、クロックあたり 4 つの命令をリタイアでき、これは 0.25 CPI に相当します。ソフトウェアによっては命令レベルの並列性がほとんどなく、キャッシュミス、条件分岐命令の予測ミスといったほかの要因によってサイクルが追加され、結果として CPI の平均値が 1.0 または 2.0 に近い数字になります。
インテル® HT テクノロジーが CPI に与える影響を理解するには、コア CPI とスレッド CPI を区別することが重要です。最初に、インテル® HT テクノロジーが無効なケースを分析してみましょう。この場合、1 つのスレッドが 1 つのコアで動作します。コアで動作するスレッドが 1 つしかないため、どの期間においても、コアまたはスレッドあたりの命令数とサイクル数は同じになります。そのため、コア CPI = スレッド CPI であるといえます。
インテル® HT テクノロジーが有効な場合は、1 つのコアで実行されるスレッドが 2 つになります。両方のスレッドがアクティブな期間では、それぞれのスレッドの実行サイクル数は同じですが、それぞれのスレッドで実行される命令の数は異なります。そのため、スレッド CPI を計算するには、各スレッドで実行された命令の数を知る必要があります。このケースでは、この 2 つのスレッドの CPI は異なります。コア CPI は、期間のサイクルの数 ÷ そのコアでリタイアされたすべての命令 (各スレッドでリタイアされた命令の合計) となります。
ある期間において、1 つのコアで 2 つのインテル® HT テクノロジー・スレッドが 1,000,000 サイクルの間に、スレッド 1 は 750,000 命令を実行し、スレッド 2 は 500,000 命令を実行したと仮定します。この場合、スレッド CPI は、スレッド 1 が 1.33 で、スレッド 2 が 2.0 となります。コア CPI は、1,000,000 ÷ 1,250,000x(750,000 + 500,000) = 0.80 となります。
正しいデータを使用して、スレッドあたりのコア CPI を計算することは可能ですが、 コアのサイクル数と命令数から、インテル® HT テクノロジーが有効な場合のスレッド CPI を計算することはできません。コア CPI を 2 倍にすることでスレッド CPI の加重平均を計算することはできますが、この結果は加重平均にすぎず、2 つのスレッドの実際の CPI とは大きく異なる場合があります。
インテル® HT テクノロジーが有効なシステムで収集したプロファイル・データを使用して、ある機能に対するコア CPI の見積もりや計算をした場合も、そのときにほかのスレッドで何が実行されていたのかを知るすべがないため、正確ではありません。実際、関数内のプロファイル・データは、毎回別のスレッドで実行された別々のルーチンでサンプリングされたものである可能性があります。
制限の理解とパフォーマンスの最大化
インテル® HT テクノロジーがスレッドレベルの並列処理を引き出す一方、それぞれの物理プロセッサー・コアにある 2 つの論理プロセッサーは、大半の実行リソースを共有します。これにより、命令のスケジューリング効率を向上させることで、実行リソースをビジーにし、命令レベルの並列性を増やして、マイクロアーキテクチャーにストールがあっても実行ユニットを常にビジーにしておくことができます。その結果、ほとんどのアプリケーションでパフォーマンスが大幅に向上します。ただし、環境によっては、インテル® HT テクノロジーの恩恵を妨げてしまったり、まれにパフォーマンスの低下を招いてしまうことがあります。以下に例を挙げます。
- アプリケーションのスケーリング: インテル® HT テクノロジーは、システムにハードウェア・スレッドを追加します。そのため、インテル® HT テクノロジーを活用するためには、追加の並列処理を生成できるよう、アプリケーションが追加のスレッドを利用しなければなりません。インテル® HT テクノロジーが無効な状態で十分なスケーリングが得られないアプリケーションは、インテル® HT テクノロジーを有効にした場合にパフォーマンス問題が発生する可能性が高くなります。この場合、まずスケーリングの問題を特定し、それらに対処するのが最良の方法といえるでしょう。重要なリソース処理 (ロック、同期) で処理時間が増えるアプリケーションは、命令が多い、パイプラインに競合がある、といったことが原因で、インテル® HT テクノロジーによる CPI の向上を打ち消してしまいます。この他にも、スケーリングの問題には、前述のような特定のプラットフォームの全リソースの使用率に起因するものもあります。スケーリングを制限する要因については、以下で説明します。
- メモリー帯域幅の利用が極端に高い: インテル® HT テクノロジーでは、2 つのスレッドを動作させる際に、メモリー・サブシステムに出す要求が増えます。インテル® HT テクノロジーが無効な状態でアプリケーションが大部分のメモリー帯域幅を利用している場合、インテル® HT テクノロジーを有効にしても、パフォーマンスは向上しません。場合によっては、メモリー要求やデータ・キャッシングの増加により、パフォーマンスが低下することもあります。幸いにも、統合メモリー・コントローラーおよび インテル® QuickPath Interconnects を搭載した Nehalem✝ コアベースのシステムでは、インテル® HT テクノロジー対応の以前のインテル® プロセッサーと比べて、使用可能なメモリー帯域幅が大幅に増えています。その結果、Nehalem✝ コアでは、インテル® HT テクノロジーの使用によるメモリー帯域幅不足でパフォーマンスが低下するアプリケーションの数は大きく減っています。
- 計算効率が極端に高い: プロセッサーの実行リソースがすでに十分に利用されている場合、インテル® HT テクノロジーを有効にしてもパフォーマンスの向上は見込めません。例えば、すでにサイクルあたり 4 つの命令を実行しているコードは、インテル® HT テクノロジーを有効にしても、パフォーマンスが向上しません。なぜならば、コアで実行可能な命令は最大でサイクルあたり 4 つであるためです。
- スレッドの負荷バランスが悪い: 並列性が向上しても、ワークロードの平行レベルがそれに応じていなければ意味がありません。数スレッド分の作業しか発生しないのであれば、ハードウェアの並列性が向上しても、パフォーマンスの向上はほんのわずかであるか、または皆無です。インテル® ソフトウェア開発製品には、スレッドのバランスを診断し、平行性を改善するためのツールがあります。
- 並行性のボトルネック: スレッドのスケーリングを制限し、並行性を妨げる要因はたくさんあります。例えば、フォルス・シェアリング、ロック/同期が多すぎる、シリアル領域に比べて並列領域が小さい、などです。全体の作業量 (ひいてはスレッドあたりの作業量) のような要因は、変更が困難または不可能ですが、ほかの要因 (フォルス・シェアリングなど) は修正可能です。補足: フォルス・シェアリングは、2 つの論理プロセッサーが意図せずに同じキャッシュラインを共有している状態です。これは一般にグローバル変数/静的変数で発生しますが、動的メモリーでも発生する場合があります。フォルス・シェアリングの最悪のシナリオは、両プロセッサーがメモリーに書き込んでいる場合です。インテルの Nehalem✝ コアは、ライトアロケート (write allocate) というライト・アロケーション・ポリシーを使用しています (インテルのほかの CPU と同じ)。つまり、キャッシュをフェッチしてから書き込む (フェッチオンライト) 方法です (RFO: read for ownership とも呼ばれます)。インテル® Core™ i7 プロセッサーの一次キャッシュメモリーはライトバック・キャッシュです (SandyBridge✝、Yonah✝、Merom✝、Penryn✝ といったほかのインテル® Core™ プロセッサー・ファミリーと同じ。ただし インテル® Pentium® 4 プロセッサーはライトスルー・キャッシュ)。ライトバック方式の一次キャッシュメモリーでは、削除 (evict) されるまでデータが一次キャッシュに保持されます。そのため、プロセッサー (便宜上 P1 とする) がメモリーに書き込んだデータは、一次キャッシュに変更状態で保持されます。この状態で別のプロセッサー (P2) が RFO を行うと、プロセッサー P1 はその L1D キャッシュラインを書き戻し、保持しているコピーを無効にして、プロセッサー P2 がそのラインを取得し排他的状態で保持できるようにする必要があります。プロセッサー P1 が再度キャッシュラインに書き込む必要が生じた場合は、再度 RFO を行い、プロセッサー P2 にそのキャッシュラインの書き戻しと、コピーの無効化を行います。
フォルス・シェアリングのサンプルコード:
int sum[THREAD_NUM];
/* each thread uses its thread number as index to global sum array */
int inc_sum () {
sum[my_thr_num]++;
return sum[my_thr_num];
}
上記の例では、プロセッサー(n) は sum[n] のみに書き込み、プロセッサー(n+1) は sum[n+1] のみに書き込みます。そのため、それぞれのプロセッサーは実際には同じメモリー位置を共有しているわけではなく (同期も不要)、同じキャッシュライン・サイズ (64 バイト) のメモリー範囲を共有しています。
ここで問題となるのは、キャッシュライン・サイズ (64 バイト) はプロセッサーに管理されるため、意図せずに共有が発生してしまいます。フォルス・シェアリングは、インテル® パフォーマンス・チューニング・ユーティリティーやインテル® VTune™ Amplifier XE のメモリーアクセス分析機能を使用して、簡単に見つけることができます。この機能はインテル® Core™ i7 プロセッサーの HITM イベントをストアして、競合するキャッシュライン・アクセスを特定します。
フォルス・シェアリングは、Microsoft* またはインテルのコンパイラーを使用し、以下に示すように、フォルス・シェアリングの原因となっている変数をキャッシュライン・サイズ (64 バイト) ごとに配置することで、簡単に修正することができます。
修正前:
int sum1; int sum2;
修正:
declspec(align(64)) int sum1;
declspec(align(64)) int sum2;
- アンダーサブスクリプション: これは、実行可能なソフトウェア・スレッドの数が、システム上のすべての論理コアを活用できるだけの数に満たない状況を指します。OS スケジューラーは、アイドルコアを使用する代わりに、1 つのコアに 2 つのワーカースレッドをスケジュールすることがあります。例えば、インテル® HT テクノロジーが有効なデュアルコア・プロセッサー (2 つの物理コアで最大 4 つのスレッドをサポート) について考えてみましょう。ある期間において実行可能なソフトウェア・スレッドが 2 つだけで、それらが同じ物理コアで実行するようにスケジュールされている場合 (もう一方の物理コアがアイドル状態の場合)、その期間ではインテル® HT テクノロジーが無効な場合よりもスループットが下回ります。アンダーサブスクリプションを改善するには、一般的なスレッディング・アプローチの使用を検討してみてください。
- OpenMP* は、共有メモリー・アプリケーションを並列化するためのコンパイラー宣言子とアプリケーション・プログラミング・インターフェイス (API) のセットです。インテル® コンパイラーも含め、ほとんどのコンパイラーは OpenMP* をサポートしています。OpenMP* の最も一般的な用途は、ループの並列化です。各反復が 1 つの作業単位となり、スレッドに配布されます。
- インテル® スレッディング・ビルディング・ブロックは、スレッド管理を抽象化して C++ を拡張する、移植性に優れた C++ テンプレート・ライブラリーです。ユーザーはスレッドではなくタスクを指定し、スレッドへのタスクのマップ/スケジュールは、ライブラリーが行います。インテル® スレッディング・ビルディング・ブロックを使用することで、パフォーマンス、移植性 (Windows*、Linux*、Mac OS*)、およびスケーラビリティーの向上を効率良く行うことができます。
- アフィニティー: アフィニティーの誤実装は、パフォーマンス低下の原因となります。アフィニティー・マスクは、OS ごとに異なります。また同じ OS でも、32 ビット版か 64 ビット版かによって異なる場合があります。また、同じ OS や BIOS 実装でも、バージョンが違えば、OS の実装が変わる場合があります。プロセッサーごとのコアの数も、システムごとに異なる場合があります。開発者はこれらの状況を考慮する必要があります。インテルでは、以下のアフィニティー対策をとることを推奨します。
- NUMA 以外のプラットフォームでは、アフィニティーを使用しないようにしてください。
- NUMA プラットフォームでは、リモートメモリーに対し、ローカルメモリーへのアクセスを向上させるために、アフィニティーが必要になる場合があります。アフィニティーを使用する場合は、OpenMP* または MPI 環境変数などのミドルウェアを使用すると良いでしょう。アフィニティーを使用する場合は、アプリケーションで正しい CPU トポロジーと列挙型情報が必要になります。詳しくは、『Intel® 64 Architecture Processor Topology Enumeration』 (http://software.intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration/) を参照してください。
- CPU 列挙のショートカット: これまで、パッケージあたりのコア数を取得するには CPUID leaf4 (CPUID.4.EAX[31:26]) を使用していました。しかし、この方法は、インテル® Core™ i7 および Nehalem✝ コア (派生プロダクト含む) や SandyBridge✝ベースのプロセッサーでは使用できません。この方法を使用すると、誤った数のソフトウェア・スレッドが生成される恐れがあります。パッケージあたりのコアの数を取得する正しい方法は、OS の API を使用することです。インテルの CPU トポロジー・エミュレーションを使用することもできます。詳しくは、『Intel® 64 Architecture Processor Topology Enumeration』 (http://software.intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration/) を参照してください。
- OS サポート: 最新の OS は、インテル® HT テクノロジーが有効な状態で動作します。各 OS は、インテル® HT テクノロジーを最大限に活用できるよう、スケジュール・エンジンへの機能強化を実装しています。一般的に、OS は新しければ新しいほど、スケジューラーのインテル® HT テクノロジーへの対応が良く、インテル® HT テクノロジーの追加機能を最大限に活用するよう意識されています。Microsoft* Windows* 7 では、インテル® HT テクノロジー対応のインテリジェント・スケジューラーが処理を行います。このスケジューラーには、インテル® HT テクノロジーのスケジューリング用に設計された以下の機能があります。
- スケジュール時に論理プロセッサー/コアの関係を認識してソフトウェア・スレッドを配置
- 別のコアがアイドル状態であるにもかかわらず、1 つのコアで 2 つのアクティブ・スレッドが実行されている場合、それを検知し、作業の移動を行う
- ワークロードとシステム使用率のニーズにマッチングさせるため、コア単位で第 2 論理プロセッサーのパーキングおよびパーキング解除を行う
- 同期のスピンループ: ループがいつ有効な処理を行っているのか、あるいはリソースが利用可能になるのを待機するためだけに作成されたループかどうか、ハードウェアには分かりません。そのため、代わりに、スピンループで pause 命令を使用するか、OS API を使用することを検討したほうが良いでしょう。
インテルでは、インテル® HT テクノロジー向けに最適化されている新しい OS へのアップグレードを推奨します。
ケーススタディー
このセクションでは、役立つケーススタディーをいくつか紹介し、結果をどのように解釈するかについて説明します。また、インテル® HT テクノロジーによってパフォーマンスを向上させる方法も説明します。
ケーススタディー: インテル® HT テクノロジーが有効な場合、物理メモリー不足はパフォーマンスの低下を引き起こす
あるベンダーでは、インテル® HT テクノロジーが有効な場合に、HPC 向け (ハイパフォーマンス・コンピューティング) アプリケーションの実行において、全体のパフォーマンスの低下が見られました。perfmon を使ってシステムのデータをキャプチャーしたところ、インテル® HT テクノロジーを有効にすると、システムがページングファイルへのスワッピングを開始することが分かりました。このアプリケーションは、スレッドごとにメモリーを割り当てるように設計されていたため、インテル® HT テクノロジーを有効にした結果、スレッドが 2 倍になり、割り当てメモリーも 2 倍に増えました。
この問題は、スワップを行う必要がないように、メモリー (RAM) を追加することで解決できました。さらに、アプリケーション側でメモリー割り当てポリシーも変更しました。ここで興味深い点は、物理 RAM を増やさずに物理コアを倍増しても、ページングによるパフォーマンスの問題が起きたであろうことです。
この例は、評価するテクノロジーに関係なく、あらゆるパフォーマンス分析で重要なコンセプトを示しています。つまり、CPU のパフォーマンスを最大限に引き出すためには、プロセッサーが利用するための十分なプラットフォーム・リソース (例: メモリー、ディスク I/O、ネットワーク I/O) が必要ということです。
ケーススタディー: 並列性が不十分であると、インテル® HT テクノロジーから得られるパフォーマンス・ゲインは非常に小さくなる
あるベンダーでは、Nehalem✝ ベースのインテル® Xeon® プロセッサーを搭載したデュアルソケット・システムでインテル® HT テクノロジーを有効にしたところ、計算エンジンの実行において、パフォーマンスの向上が全く見られませんでした。テストでは、8 スレッド (インテル® HT テクノロジーが無効な状態) と、16 スレッド (インテル® HT テクノロジーが有効な状態) を使用しました。詳細な分析の結果、4 スレッドから 8 スレッドに移行した場合は、インテル® HT テクノロジーの有効/無効にかかわらず、パフォーマンスの向上はわずかであったことが分かりました。また、このワークロード実行中の平均 CPU 使用率はわずか 55% でした。
プロファイル・データのキャプチャーにはインテル® VTune™ Amplifier XE が使用され、データの確認には「スレッドのタイムライン」ビューが使用されました。このケースでは、アプリケーションが長時間に渡って単一のシリアルスレッドを実行することが何度かありました。並列処理が行われたのは、シリアル処理に比べるとわずかな時間でした。また、スレッドを増やしたわりには、パフォーマンスの向上はわずかでした。これはアムダールの法則に一致しています。
ここでは、シリアル領域を並列化できるようにアプリケーション・アーキテクチャーを変更することで問題を解決しました。このスケーリング問題は、インテル® HT テクノロジーが有効でなくても存在していました。
CPU の使用率は「低」、または「低」と「高」を繰り返していて、これは、コードのシリアル領域、またはスケーリング不良の原因となっている共有リソースの競合を示しています。
ケーススタディー: 並列性が不十分であると (#2)、インテル® HT テクノロジーから得られるパフォーマンス・ゲインはゼロ
インテル® HT テクノロジーによりパフォーマンスの向上が見られないいくつかの例では、単純にアプリケーションで動作しているスレッドの数が不十分であることが分かっています。最も極端な例はシングルスレッドのアプリケーションです。スレッドを増やさない限りパフォーマンスの向上はありません。
今後、プロセッサーのコアとスレッドの数は増え続けることが予測されます。新しいプロセッサーの処理能力を活用するには、スケーラブルなマルチスレッド・アプリケーションが必要です。インテル® HT テクノロジー対応の将来のシステムでは、スレッドとコアの数は 2 の累乗ではないスレッド/コア数になるでしょう。コア/スレッドの数が常に 2 の累乗と想定したアプリケーションも一部ありますが、利用可能なすべてのプロセッサー・スレッドを活用できるようにしない限り、プロセッサーの性能を最大限に引き出すことはできません。
ケーススタディー: インテル® HT テクノロジーが有効な場合と無効な場合のプロファイル・データの解釈
このケーススタディーでは、インテル® HT テクノロジーが有効な場合のプロファイル・データの正しい解釈方法を示すとともに、インテル® HT テクノロジーが無効な場合との比較方法を説明します。詳しくは、『Intel® Hyper-Threading Technology: Analysis of the HT Effects on a Server Transactional Workload』(http://software.intel.com/en-us/articles/intel-hyper-threading-technology-analysis-of-the-ht-effects-on-a-server-transactional-workload/ (英語)) を参照してください。
ここで注目するべきポイントは次のとおりです。
- インテル® HT テクノロジーを有効にすると、パフォーマンスが 30% アップ
- エンドユーザーの応答時間は 50ms から 37ms に短縮
- 処理完了までの平均サイクル数は 49% に向上
この 30% のパフォーマンスの向上と 49% の計算サイクルの向上は、図 12 の曲線とほぼ一致します。
エンドユーザーの応答時間も短縮されましたが、これは必ずしも直感的な結果ではありません。前述のとおり、このトピックの詳細については、『Hyper-Threading: Be Sure You Know How to Correctly Measure Your Server’s End-User Response Time』 (http://software.intel.com/en-us/articles/hyper-threading-be-sure-you-know-how-to-correctly-measure-your-servers-end-user-response-time-1) を参照してください。
推奨事項
ソフトウェア開発者とパフォーマンス・チームへの推奨事項
インテル® HT テクノロジーにより得られるパフォーマンスの向上は、アプリケーションまたは実行プラットフォームの特性によって異なります。通常、インテル® HT テクノロジーはパフォーマンスの向上をもたらします。インテル® HT テクノロジーを有効または無効にしてパフォーマンスを測定することで、インテル® HT テクノロジーのメリットを評価できます。
インテル® HT テクノロジーによるメリットが少ない、または全くない場合は、ソフトウェアのスケーリングを向上できる可能性があります。そうすることで、多くの場合、インテル® HT テクノロジーの有効/無効に関係なく、パフォーマンスの向上につながります。入出力と OS のアクティビティーを評価し、期待どおりのパフォーマンスが得られない原因を特定するには、プラットフォームのパフォーマンス・データを十分に収集することが重要です。
また、インテル® HT テクノロジーが有効/無効な場合のテストと、最適化を組み合わせることで、大幅な効果が得られます。インテル® VTune™ Amplifier XE を使ってスレッドのプロファイリングとチューニングを行うことで、スレッド化によるパフォーマンスを引き出し、アプリケーションにおいてインテル® HT テクノロジーを使用するメリットを阻む問題に対処して、アプリケーションの価値を向上させることが可能です。
ソフトウェア・ベンダーは、自社のアプリケーションでインテル® HT テクノロジーから最高のパフォーマンスを引き出せるよう、テスト結果を基にソフトウェアおよびハードウェアの推奨設定を顧客に提供すると良いでしょう。さらに、特定の実装に対するガイドラインや、インテル® HT テクノロジーを活用するためのシステム要件 (システムメモリーやプラットフォームなど) なども顧客にとって有益な情報といえるでしょう。
インテル® HT テクノロジーのメリットを評価する際は、タスク完了までの経過時間、単位時間あたりの作業量といった評価基準を使用し、単純に CPU 使用率だけに依存しないことが重要です。ただし、低 CPU 使用率は、ほかのスケーリングの問題、例えば、スレッドの数が不十分でプロセッサーを十分活用できない、プラットフォームのリソース不足、プログラムの共有リソースの競合、コードのシリアル領域が多すぎる、といった問題を示唆している可能性があります。
エンドユーザーに対する推奨事項
エンドユーザーは最初に、ソフトウェア・ベンダーが推奨するアプリケーションやハードウェアの最適な設定を試してみるべきです。インテル® HT テクノロジーのパフォーマンスの評価は、開発者向けと同じガイドラインに従って行うことができます。
まとめ
インテル® HT テクノロジーを使用することで、多くのアプリケーションではパフォーマンスと効率が向上します。コア数に応じて十分にスケーリングするアプリケーションは、一般に、インテル® HT テクノロジーを使用することで十分にスケーリングします。Nehalem✝ や SandyBridge✝ コアには、インテル® HT テクノロジーを補完する数多くの拡張が含まれているため、パフォーマンスが大幅に向上します。
今後もコアとスレッドの数は増え続けることが考えられるため、マルチコアに対応した優れたスケーリングは、これからも重要になるでしょう。
インテル® HT テクノロジーが有効な場合のアプリケーションのパフォーマンスを評価する際には、パフォーマンス・ツールで収集したデータの差異を理解することが重要です。また、インテル® HT テクノロジーが有効な場合と無効な場合のデータの比較では、多くの場合、直感的な理解だけではパフォーマンスが示唆していることを正しく理解することはできません。
最後にインテルでは、インテルのシステムで最高のパフォーマンスを達成していただけるよう、ISV コミュニティーおよびシステムユーザーへの支援に尽力しています。インテル® HT テクノロジーおよびその他のインテル製品に関する詳細は、インテル® ソフトウェア・ネットワークの Parallel Programming and Multi-Core Developer Community (http://software.intel.com/en-us/multi-core/ (英語)) を参照してください。
著者紹介
 Garrett Drysdale: インテルのシニア・ソフトウェア・パフォーマンス・エンジニア。1995 年以来、インテル® プラットフォームにおけるソフトウェアの分析と最適化に取り組んでおり、その範囲はクライアント、ワークステーション、エンタープライズ・サーバーにわたります。現在は、エンタープライズ・ソフトウェアの開発者と協力して、サーバー・アプリケーションの分析と最適化に携わっています。またインテル内部の設計チームと協力し、将来のインテル® プラットフォームのために、新しいテクノロジーがソフトウェアのパフォーマンスに与える影響を評価する支援をしています。Garrett は、ミズーリ大学ローラ校で電気工学の学士号と、ジョージア工科大学で電気工学の修士号を取得しています。メールアドレス: garrett.t.drysdale@intel.com
Garrett Drysdale: インテルのシニア・ソフトウェア・パフォーマンス・エンジニア。1995 年以来、インテル® プラットフォームにおけるソフトウェアの分析と最適化に取り組んでおり、その範囲はクライアント、ワークステーション、エンタープライズ・サーバーにわたります。現在は、エンタープライズ・ソフトウェアの開発者と協力して、サーバー・アプリケーションの分析と最適化に携わっています。またインテル内部の設計チームと協力し、将来のインテル® プラットフォームのために、新しいテクノロジーがソフトウェアのパフォーマンスに与える影響を評価する支援をしています。Garrett は、ミズーリ大学ローラ校で電気工学の学士号と、ジョージア工科大学で電気工学の修士号を取得しています。メールアドレス: garrett.t.drysdale@intel.com
 Antonio C. Valles: インテルのシニア・ソフトウェア・エンジニア。主にインテルのマイクロプロセッサーおよびチップセットのプリシリコンと初期シリコンのテストに従事しています。プリシリコンとポストシリコン用の内部ツール、およびパフォーマンス・アナリスト向けのミニベンチマークの作成に携わるとともに、設計者、バリデーション・エンジニア、ソフトウェア・エンジニアと協力して、プロセッサー向けのチューニング・ガイドラインの作成に取り組んでいます。Antonio は、1997 年にアリゾナ州立大学から電気工学の学士号を取得しています。メールアドレス: antonio.c.valles@intel.com
Antonio C. Valles: インテルのシニア・ソフトウェア・エンジニア。主にインテルのマイクロプロセッサーおよびチップセットのプリシリコンと初期シリコンのテストに従事しています。プリシリコンとポストシリコン用の内部ツール、およびパフォーマンス・アナリスト向けのミニベンチマークの作成に携わるとともに、設計者、バリデーション・エンジニア、ソフトウェア・エンジニアと協力して、プロセッサー向けのチューニング・ガイドラインの作成に取り組んでいます。Antonio は、1997 年にアリゾナ州立大学から電気工学の学士号を取得しています。メールアドレス: antonio.c.valles@intel.com
 Matt Gillespie: シカゴを拠点とするフリーのテクニカルライター。専門は、最先端のハードウェア/ソフトウェア・テクノロジーで、特にインテルの最新情報に注目しています。また、音声とデータ・ネットワークを融合した IT の実践本も手がけてます。若い頃は、金融関係の出版社 Morningstar とカリフォルニア大学の神経化学センターで調査員を務めていました。
Matt Gillespie: シカゴを拠点とするフリーのテクニカルライター。専門は、最先端のハードウェア/ソフトウェア・テクノロジーで、特にインテルの最新情報に注目しています。また、音声とデータ・ネットワークを融合した IT の実践本も手がけてます。若い頃は、金融関係の出版社 Morningstar とカリフォルニア大学の神経化学センターで調査員を務めていました。
性能に関するテストや評価は、特定のコンピューター・システム、コンポーネント、またはそれらを組み合わせて行ったものであり、このテストによるインテル製品の性能の概算の値を表しているものです。システム・ハードウェア、ソフトウェアの設計、構成などの違いにより、実際の性能は掲載された性能テストや評価とは異なる場合があります。システムやコンポーネントの購入を検討される場合は、ほかの情報も参考にして、パフォーマンスを総合的に評価することをお勧めします。インテル製品の性能評価についてさらに詳しい情報をお知りになりたい場合は、http://www.intel.com/performance/resources/benchmark_limitations.htm (英語) を参照してください。
1 インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) には、インテル® HT テクノロジー対応のインテル® プロセッサー、チップセット、BIOS、およびオペレーティング・システム (OS) を搭載したコンピューター・システムが必要です。パフォーマンスは、ご使用のハードウェアおよびソフトウェアによって異なる場合があります。インテル® HT テクノロジー対応プロセッサーの詳細については、www.intel.com/products/ht/hyperthreading_more.htm (英語) を参照してください。
2 出典: 2008 年秋インテル・デベロッパー・フォーラム。インテル® Core™ i7 プロセッサー 2.66GHz、QPI 6.4、メモリークロック 1066MHz、Stream BW (TRIAD) を使用。
✝開発コード名
インテル® ソフトウェア製品のパフォーマンス/最適化に関する詳細は、最適化に関する注意事項 (英語) を参照してください。
