

この記事は、インテル® ソフトウェア・サイトに掲載されている「Performance Benefits of Half Precision Floats」(http://software.intel.com/en-us/articles/performance-benefits-of-half-precision-floats/) の日本語参考訳です。
半精度浮動小数点とは、16 ビットの浮動小数点値です。従来の 32 ビットの単精度浮動小数点と比べるとサイズが半分で精度は低く、範囲も小さいものです。高い精度が必要ない場合、半精度浮動小数点は容量とメモリー帯域幅が半分で済むため、浮動小数点値を格納するのに便利です。16 ビット精度でも十分な場合、第 3 世代インテル® Core™ プロセッサー・ファミリーで導入された新しい半精度浮動小数点変換命令を使用することで、浮動小数点値のロードやストアを行うアプリケーションのパフォーマンスを向上できる可能性があります。特に、32 ビット float データが L1 キャッシュに収まらない場合、half-float (半精度浮動小数点) は 32 ビット float よりもパフォーマンスが優れています。
1. 半精度浮動小数点の概要
半精度浮動小数点は 16 ビットの浮動小数点値です。従来の 32 ビットの単精度浮動小数点のサイズの半分で、(binary16 IEEE754-2008 標準規格)、float16、FP16、または単に half-float とも呼ばれます。
サイズが半分なので、単精度や倍精度浮動小数点と比べると、半精度浮動小数点の範囲は小さく、精度も低くなります。そのため、計算には適していないと一般に考えられています。しかし、half-float は 32 ビット float の半分の容量と帯域幅しか必要としないため、精度がそれほど重要ではない場合に浮動小数点値を格納するのに適しています。さらに、8 ビットまたは 16 ビットの整数型と異なり、半精度浮動小数点はダイナミック・レンジを持っています。つまり、0 に近い浮動小数点値の精度は比較的高く、0 から遠い整数の精度は低くなります。
半精度浮動小数点は、±65,504 の範囲の値を表現できます。値の精度の範囲は、0 に近い値では 0.0000000596046 (5.96046 x 10-8) と最も高く、32,768-65,536 の範囲の値では最大 32 (つまり、この範囲の値は最も近い 32 の倍数に切り捨てられます) と最も低くなります。±65,536 よりも大きな値を処理する場合は、半精度浮動小数点を使用しないでください。半精度浮動小数点形式に関する詳細は、IEEE 754-2008 標準規格を参照してください。
2. 半精度浮動小数点の使用
半精度浮動小数点は格納形式なので、half-float の操作は 32 ビット float との変換のみです。第 3 世代インテル® Core™ プロセッサー・ファミリーでは、2 つの half-float 変換命令が実装されています。32 ビット float から half-float へ変換する vcvtps2ph と、half-float から 32 ビット float へ変換する vcvtph2ps です。
対応する組込み命令を使用することで、アセンブリーを記述しなくてもこれらの命令を利用できます: 32 ビット float から half-float へ変換する場合は _mm256_cvtps_ph、half-float から 32 ビット float へ変換する場合は _mm256_cvtph_ps を使用します (128 ビット・ベクトルの場合は、それぞれ _mm_cvtps_ph および _mm_cvtph_ps を使用します)。
インテル® コンパイラーを使用すると、half-float 変換命令に対応していないプロセッサー向けにコンパイルする場合でも、これらの組込み命令を利用できます。この場合、最適化されたライブラリー呼び出しを通してソフトウェアで変換が行われます。ネイティブのハードウェア命令よりもパフォーマンスは低下しますが、複数のプロセッサー向けの製品で一貫性のあるソースコードを実装できます。
インテル® コンパイラーで第 3 世代インテル® Core™ プロセッサー・ファミリー (またはそれ以降) 向けの変換命令を生成するには、–xCORE-AVX-I オプション (Windows* の場合は /QxCORE-AVX-I) を指定してファイル全体をコンパイルするか、個々の関数でインテル固有の最適化プラグマで target_arch=CORE-AVX-I を使用します (以下を参照)。
図 1. インテル固有の最適化プラグマを使用してインテル® コンパイラーに half-float 変換命令を使用するように指示する例。生成されるアセンブリー・コードも示します。
#pragma intel optimization_parameter target_arch=CORE-AVX-I
__declspec(noinline) void float2half(float* floats, short* halfs) {
__m256 float_vector = _mm256_load_ps(floats);
__m256i half_vector = _mm256_cvtps_ph(float_vector, 0);
_mm256_store_si256 ((__m256i*)halfs, half_vector);
}
vmovups (%rax), %ymm0
vcvtps2ph $0x0, %ymm0, (%rbx)
vcvtps2ph 命令と _mm[256]_cvtps_ph 組込み命令には、丸めを制御する即値バイト引数があります。これは、以下のようにエンコードされます。
表 1.half-float 変換命令の即値バイトのエンコード
| ビット | 値 (バイナリー) | 説明 |
| imm[1:0] | 00 | 最も近い偶数に丸める |
| 01 | 切り捨てる | |
| 10 | 切り上げる | |
| 11 | 切り詰める | |
| imm[2] | 0 | 丸めに imm[1:] を使用する |
| 1 | 丸めに MXCSR.RC を使用する |
3. パフォーマンスの向上
3.1. 背景
半精度浮動小数点には、32 ビット float と比べて、メモリーアクセスに関する利点があります:
- サイズが半分なので、低レイテンシーのコアに近いキャッシュに収まります。
- 使用するキャッシュ領域が半分で済むため、プログラムのほかのデータがキャッシュ領域を利用できます。
- 必要なメモリー帯域幅も半分なので、プログラムのほかの処理が帯域幅を利用できます。
さらに、半精度浮動小数点は、ディスクに格納する場合も、容量と ディスク I/O が半分で済むというメリットがありますが、欠点は、操作の前に 32 ビット float との変換が必要になることです。ただし、新しい half-float 変換命令は非常に高速なため、状況によっては、浮動小数点値の格納に half-float を使用することで、32 ビット float を使用するよりもパフォーマンスが向上することがあります。
浮動小数点データを配列から繰り返しロードし、処理を行い、配列に格納する一般的なジェネリック操作について考えてみましょう。32 ビット float を使用してこのジェネリック操作を行うコードを以下に示します。インテル® AVX を使用することで、256 ビット (8 つの単精度浮動小数点) を 1 つの操作でロード/ストアすることができます。サイズが 8 の倍数でない場合、残りの要素の処理にプロローグとエピローグが必要になります。
図 2. 単精度データのジェネリック操作
float* array; size_t size;
for (size_t i = 0; i < size; i += 8) {
__m256 vector = _mm256_load_ps(array + i);
// ここでベクトルの計算
_mm256_store_ps(array + i, vector);
}
同じ数の配列要素に対する同じ操作を、128 ビットのロード/ストア (8 つの half-float) を使用して half-float で実装し、32 ビット float の変換処理を追加したコードを以下に示します。
図 3. 128 ビットのロード/ストアを使用する半精度データのジェネリック操作
uint16_t* array; size_t size;
for (size_t i = 0; i < size; i += 8) {
__m256 vector = _mm256_cvtph_ps(_mm_load_si128((__m128i*)(array + i)));
// ここでベクトルの計算
_mm_store_si128((__m128i*)(array + i), _mm256_cvtps_ph(vector, 0 /*rounding*/));
}
配列のサイズによっては、half-float を使用するこのジェネリック操作は、32 ビット float を使用する場合よりもパフォーマンスが向上します。
3.2. 結果
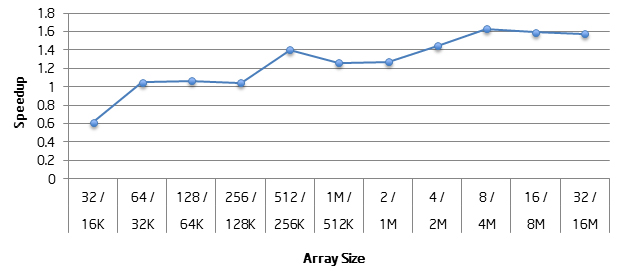
32 ビット float データが L1 キャッシュに収まらない場合、half-float を使用するほうが、32 ビット float データを使用するよりもパフォーマンスが向上します。特に、half-float の使用による平均スピードアップは、32 ビット・データが L2 キャッシュに収まる場合は 1.05 倍、L3 キャッシュに収まる場合は 1.3 倍、メモリーに収まる場合は 1.6 倍になります。さらに、32 ビット・データが L1 キャッシュに収まる場合、half-float により直接パフォーマンスが向上することはないかもしれませんが、half-float はキャッシュ領域を半分しか使用しないため、より多くのプログラムデータを L1 に配置でき、これによる付随的な利点が得られます。
以下のグラフは、配列要素が 8K から最大 8M までの配列のスピードアップを示したものです。ここで、各 32 ビット float 要素は 4 バイト、各 half-float 要素は 2 バイトです。
これらのパフォーマンス統計は、第 3 世代インテル® Core™ プロセッサー 1.80GHz、32KB L1 データキャッシュ、256KB L2 キャッシュ、4MB L3 キャッシュ、4GB RAM を搭載するマシンで行ったテストに基づいています。コードは、インテル® コンパイラー 12.1 で、/O3 /QxCORE-AVX-I オプションを指定してコンパイルされました。
図 4. 32 ビット float と比較した half-float のスピードアップ
4. 推奨事項
単精度浮動小数点の精度と範囲が必要なければ、例で紹介したロード-処理-ストアというジェネリック操作パターンと同様のデータアクセスを行うプログラムで、32 ビット・データが L1 キャッシュに収まらない場合に half-float を使用することを推奨します。また、常に配列を適切な境界 (128 ビット・データは 16 バイト、256 ビット・データは 32 バイト) でアライメントすると良いでしょう。
5. まとめ
半精度浮動小数点とは、16 ビットの浮動小数点値です。従来の 32 ビットの単精度浮動小数点と比べるとサイズが半分で精度は低く、範囲も小さいものです。高い精度が必要ない場合、半精度浮動小数点は容量とメモリー帯域幅が半分で済むため、浮動小数点値を格納するのに便利です。第 3 世代インテル® Core™ プロセッサー・ファミリーで実装された新しい半精度浮動小数点変換命令を使用することで、浮動小数点値を格納するアプリケーションの特定の状況下でパフォーマンスを向上できる可能性があります。
6. 著者紹介
 |
Patrick Konsor は、米国カリフォルニア州サンタクララにあるインテルの Apple 推進チームのアプリケーション・エンジニアとして、ソフトウェアの最適化に取り組んでいます。ウィスコンシン大学オークレア校でコンピューター・サイエンスの学士号を取得しています。趣味はサイクリングです (Go Schlecks!)。 |
7. 著作権と商標について
本資料に掲載されている情報は、インテル製品の概要説明を目的としたものです。本資料は、明示されているか否かにかかわらず、また禁反言によるとよらずにかかわらず、いかなる知的財産権のライセンスを許諾するものではありません。製品に付属の売買契約書『Intel's Terms and Conditions of Sale』に規定されている場合を除き、インテルはいかなる責任を負うものではなく、またインテル製品の販売や使用に関する明示または黙示の保証 (特定目的への適合性、商品適格性、あらゆる特許権、著作権、その他知的財産権の非侵害性への保証を含む) に関してもいかなる責任も負いません。
インテルによる書面での合意がない限り、インテル製品は、その欠陥や故障によって人身事故が発生するようなアプリケーションでの使用を想定した設計は行われていません。
インテル製品は、予告なく仕様や説明が変更される場合があります。機能または命令の一覧で「留保」または「未定義」と記されているものがありますが、その「機能が存在しない」あるいは「性質が留保付である」という状態を設計の前提にしないでください。これらの項目は、インテルが将来のために留保しているものです。インテルが将来これらの項目を定義したことにより、衝突が生じたり互換性が失われたりしても、インテルは一切責任を負いません。この情報は予告なく変更されることがあります。この情報だけに基づいて設計を最終的なものとしないでください。
本資料で説明されている製品には、エラッタと呼ばれる設計上の不具合が含まれている可能性があり、公表されている仕様とは異なる動作をする場合があります。現在確認済みのエラッタについては、インテルまでお問い合わせください。
最新の仕様をご希望の場合や製品をご注文の場合は、お近くのインテルの営業所または販売代理店にお問い合わせください。
本資料で紹介されている資料番号付きのドキュメントや、インテルのその他の資料を入手するには、1-800-548-4725 (アメリカ合衆国) までご連絡いただくか、インテルの Web サイトを参照してください。
Intel、インテル、Intel ロゴは、アメリカ合衆国およびその他の国における Intel Corporation の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
© 2012 Intel Corporation. 無断での引用、転載を禁じます。
最適化に関する注意事項
インテル® コンパイラーは、互換マイクロプロセッサー向けには、インテル製マイクロプロセッサー向けと同等レベルの最適化が行われない可能性があります。これには、インテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2)、インテル® ストリーミング SIMD 拡張命令 3 (インテル® SSE3)、ストリーミング SIMD 拡張命令 3 補足命令 (SSSE3) 命令セットに関連する最適化およびその他の最適化が含まれます。インテルでは、インテル製ではないマイクロプロセッサーに対して、最適化の提供、機能、効果を保証していません。本製品のマイクロプロセッサー固有の最適化は、インテル製マイクロプロセッサーでの使用を目的としています。インテル® マイクロアーキテクチャーに非固有の特定の最適化は、インテル製マイクロプロセッサー向けに予約されています。この注意事項の適用対象である特定の命令セットの詳細は、該当する製品のユーザー・リファレンス・ガイドを参照してください。
改訂 #20110804
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
