

この記事は、インテル社のウェブサイトで公開されている「The Converged Vector ISA: Intel® Advanced Vector Extensions 10 Technical Paper」 (July 2023 Revision 1.0 資料番号: 356368-001US、更新日: 2023年7月24日) の抜粋日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
インテル® アドバンスト・ベクトル・エクステンション 10 (インテル® AVX10) では、将来のインテル® プロセッサー全体でサポートされる最新のベクトル命令セット・アーキテクチャー (ISA) が導入されています。この新しい ISA には、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) で提供される豊富な機能がすべて取り込まれており、Performance-core (P コア) と Efficient-core (E コア) 間でシームレスに実行できる追加機能が備わっており、すべてのプラットフォームでパフォーマンスと一貫性を実現します。
また、ISA のバージョンとサポートされるベクトル長に基づく新しい列挙アプローチが導入されているため、開発者がプラットフォームの機能をチェックする負担が軽減されます。インテル® AVX10 は、インテル® AVX-512 の機能を拡張および強化し、すべてのインテル製品に利益をもたらす将来的に最適なベクトル ISA です。
背景
2016年にインテルは、ハイパフォーマンス・ベクトルの導入により、ベクトル命令セットのメジャー・アップデートを開始しました。ISA 名は、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) でした。インテル® AVX-512 ISA には、512 ビット・ベクトル・レジスター、個別機能列挙手法、16 個の追加レジスター、8 個のマスクレジスター、512 ビット長の埋め込み丸め、および大規模な新命令群など、インテル® アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2) ISA を上回るいくつかの新機能が含まれています。
インテル® AVX-512 は、ベクトル長の短いバージョンの命令 (128 や 256 ビット) と多くの追加命令をサポートするように進化してきました。各命令には独自の CPUID 機能フラグがあり、 Performance-core (P コア) を対象とするワークロードのパフォーマンスと機能を向上しました。
インテル® AVX ファミリーの命令セット (インテル® AVX、インテル® AVX2、およびインテル® AVX-512) は、ビデオ処理、暗号化、HPC、AI、ゲームなどを含むさまざまなアプリケーションで広く採用されています。さらにアプリケーションを加速するため、インテルは将来の Efficient-core (E コア) および Performance-core (P コア) でサポートされる ISA の標準として、次世代インテル® AVX10 を発表しました。インテル® AVX10 により、エコシステムは製品やプラットフォーム全体でソリューションをシームレスに統合し、今後何年にもわたってインテル製品の次世代に向けた革新を可能にします。
インテル® AVX10 について
インテル® アドバンスト・ベクトル・エクステンション 10 (インテル® AVX10) は、インテル® AVX-512 導入以来、最も影響があるベクトル ISA の進化です。インテル® AVX10 には、256 ビットのベクトルレジスターを持つプロセッサーと 512 ビットのベクトルレジスターを持つプロセッサーの両方に対応する、インテル® AVX-512 ISA のすべての機能が含まれます。さらに、この ISA にはいくつかの新機能が含まれ、機能のサポートを確認する CPUID 機能フラグの数を減らす新しい列挙スキームがサポートされます。インテル® AVX10 は、将来の P コアおよび E コアベースのプロセッサーで動作するように設計されており、アプリケーションをプラットフォーム間でシームレスに移動できるようになります。
インテル® AVX10 を導入する要因は 3 つあります。
- 既存のインテル® AVX-512 ISA の豊富な機能をすべて備えた、ハイパフォーマンス・ベクトル ISA のサポートを継続する。
- 将来のすべてのインテル® プロセッサーでサポートされるインテル® AVX-512 ベースのコンバージド・ベクトル ISA を作成する。
- CPUID 機能のサポートをチェックする開発者の労力を軽減する。
インテル® AVX10 ベクトル ISA の統合バージョンには、AVX512VL 機能フラフを備えたインテル® AVX-512 ベクトル命令、256 ビットの最大ベクトルレジスター長、8 つの 32 ビット・マスク・レジスターおよび、埋め込み丸めをサポートする新しい 256 ビット命令が含まれます。この統合バージョンは、P コアと E コアの両方でサポートされます。統合バージョンのベクトル長は最大 256 ビットに制限されますが、インテル® AVX10 自体は 256 ビットに制限されることなく、サポートされる P コアではオプションで 512 ビットのベクトルが利用できます。
そのため、インテル® AVX10 は、P コア製品ラインを備えたインテル® Xeon® プロセッサーのインテル® AVX-512 の利点をすべて受け継いで、従来の ISA を構成する命令、ベクトル長およびマスクレジスター長、そして機能をサポートします。将来の P コアベースのインテル® Xeon® プロセッサーは、引き続きインテル® AVX-512 命令をサポートし、従来のアプリケーションは影響されることなく動作し続けることが保証されます。
機能列挙
開発者コミュニティーからは、現在のインテル® AVX-512 の列挙方式が年々扱いにくくいなっている、というフィードバックが寄せられています。新しい命令が導入されると、それに対応する新しい CPUID 機能フラグが割り当てられるため、それらをチェックする必要があります。開発コード名 Granite Rapids と呼ばれる P コアを搭載した将来のインテル® Xeon® プロセッサーでは、20 を超える個別のインテル® AVX-512 機能フラグが存在すると予測されます。これに対処するため、インテル® AVX10 では列挙に対する新しいバージョン管理が採用されました。それは、インテル® AVX10 のサポートを示すベクトル ISA 機能ビット、インテル® AVX10 ISA バージョン番号、および製品のベクトル長 (128、256、512 ビット) を列挙する 3 ビットです。
インテル® AVX10 ISA のバージョン番号は、包括的で単純に増加します。開発者は、インテル® AVX10 ISA のバージョン N+1 には、バージョン N で提供されるすべての機能が含まれることを期待できます。開発者への影響を最小限に抑え、インテル® AVX10 ISA の新しいバージョンには、新しい機能を持つ重要なスイートが含まれることを期待できます。関連するソフトウェアの対応への取り組みを正当化する十分な付か価値を提供します。まれに、セグメント固有の機能や新しいインテル® AVX10 バージョン間の中間的なリリースでは、個別の CPUID 機能フラグが割り当てられることもあります。
インテル® AVX-512 ISA は、インテル® AVX10 導入時点で凍結されますが、すべての CPUID 機能フラグは、将来の P コア・プロセッサーでレガシーサポートを確認するため引き続き有効です。後続の新しいすべてのベクトル命令は、インテル® AVX10 の一部としてのみ列挙されます。いくつかの特殊なケースを除いて、これらの命令はすべてのベクトル長でサポートされます。128 ビットと 256 ビットのベクトル長はすべてのプロセッサーでサポートされ、さらに 512 ビットのベクトル長が P コア・プロセッサーでサポートされます。
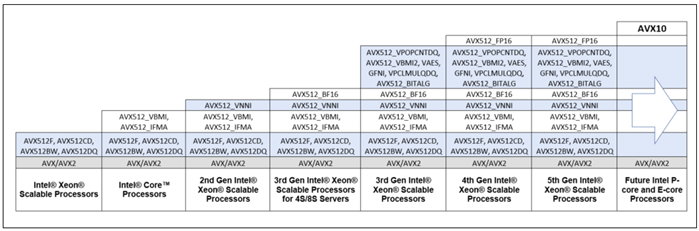
図 1-1. インテル® Xeon® プロセッサーの世代におけるインテル® AVX-512 機能フラグとインテル® AVX10 の比較
パフォーマンス上の利点
前述の機能チェックの利点に加えて、インテル® AVX10 にはパフォーマンス面でもいくつかの利点があります。
- インテル® AVX2 向けにコンパイルされたアプリケーションをインテル® AVX10 向けに再コンパイルすると、ソフトウェアのチューニングを行うことなくそのままでパフォーマンスが向上します。
- レジスター・プレッシャーに敏感なインテル® AVX2 アプリケーションは、再コンパイルによって追加された 16 個のベクトルレジスターと新しい命令によって、パフォーマンスを最大化できます。
- 高度にスレッド化およびベクトル化されたアプリケーションは、E コアベースのインテル® Xeon® プロセッサーやパフォーマンス・ハイブリッド・アーキテクチャーを備えたインテル® プロセッサーで実行すると、高い総スループットを達成できる可能性があります。
既存のインテル® AVX-512 アプリケーションは、多くがすでに最大 256 ビットのベクトルを利用していますが、ISA ベクトル長でインテル® AVX10 (256 ビット) に再コンパイルすると、同様のパフォーマンスが期待できます。より長いベクトル長を活用可能なアプリケーションでは、インテル® AVX10 (512 ビット) が P コアでサポートされるため、AI、科学技術、およびその他のハイパフォーマンス・コードに対し最高のパフォーマンスを発揮し続けます。新しいインテル® AVX10 対応のライブラリー、コンパイラー、およびツールのサポートも提供され、アプリケーション開発者はこれまでどおり、すべてのベクトル長およびターゲット・プロセッサーで達成可能な最高のパフォーマンスを実現できます。
利用可能時期
インテル® AVX10 バージョン 1 は、早期のソフトウェア開発向けに導入され、インテル® AVX10 と上位互換のある P コアを備えた将来のインテル® Xeon® プロセッサー (開発コード名 Granite Rapids) で利用可能なすべてのインテル® AVX-512 命令セットのサブセットをサポートします。このバージョンには、埋め込み丸め処理をサポートする新しい 256 ビット・ベクトル命令やそのほかの新命令は含まれておらず、インテル® AVX-512 からインテル® AVX10 への移行目的のバージョンとして機能します。
インテル® AVX10 バージョン 2 には、埋め込み丸め処理をサポートする新しい 256 ビット・ベクトル命令に加え、新しい AI データタイプと変換、データ移動の最適化、標準サポートを捕捉する新しいインテル® AVX10 命令群が含まれます。すべての新しい命令は、128 ビット、256 ビット、512 ビットのベクトル長をサポートしますが、バリエーションは限られています。すべてのインテル® AVX10 バージョンは、新しいバージョン列挙スキームを実装します。

図 1-2. インテル® ISA ファミリーと機能
まとめ
インテル® AVX10 は、将来のインテル® プロセッサー全体でハイパフォーマンス・ベクトル ISA をサポートする大きな移行を開始します。これにより、開発者は、機能サポートのチェックにかかる労力を最小限に抑えつつ、すべてのインテル® プラットフォーム間で高いパフォーマンスを達成する単一のコードパスを維持できます。インテル® AVX10 ISA の今後の開発では、サーバー製品とクライアント製品の両方を最適にサポートする、豊富で、柔軟性があり、一貫した環境を提供していきます。
CPUID 列挙の詳細については、こちらをご覧ください。
