

この記事は、The Parallel Universe Magazine 50 号に掲載されている「Accelerate PyTorch with Intel® Extension for PyTorch*」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

インテルのエンジニアは、PyTorch* オープンソース・コミュニティーと協力して、ディープラーニング (DL) のトレーニングと推論のパフォーマンス向上に取り組んでいます。PyTorch* 向けインテル® エクステンションは、インテル® プロセッサー上で DL パフォーマンスを最適化するオープンソース拡張です。この最適化の多くは、最終的に将来の PyTorch* メインライン・リリースに含まれる予定ですが、この拡張機能を利用することで、PyTorch* ユーザーは最新の機能と最適化をいち早く入手できます。CPU に加えて、近い将来インテル® GPU もサポートされる予定です。
PyTorch* 向けインテル® エクステンションは、命令モードとグラフモードの両方を最適化します (図 1)。最適化は、PyTorch* の操作、グラフ、ランタイムを対象としています。最適化された操作やカーネルは、PyTorch* のディスパッチ・メカニズムを通じて登録されます。実行中、PyTorch* 向けインテル® エクステンションは ATen 操作のサブセットを最適化された操作でオーバーライドし、一般的なユースケース向けのカスタム操作とオプティマイザーを追加で提供します。グラフモードでは、パフォーマンスを最大化するため、追加のグラフ最適化パスが適用されます。ランタイムの最適化は、ランタイム拡張モジュールにカプセル化されており、ユーザーがスレッドランタイムを細かく制御できるように、いくつかの PyTorch* フロントエンド API が用意されています。
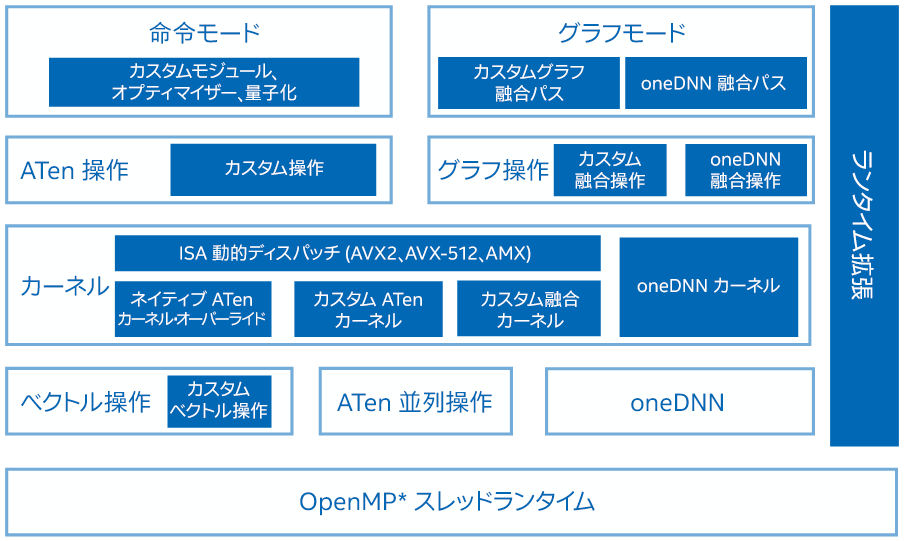
図 1. PyTorch* 向けインテル® エクステンション
最適化の概要
メモリーレイアウトはビジョン関連の操作にとって基本的な最適化です。入力テンソルに適切なメモリー・フォーマットを使用することで、PyTorch* モデルのパフォーマンスを大幅に向上できます。「Channels last memory format (チャネル・ラスト・メモリー・フォーマット)」は、一般に複数のハードウェア・バックエンドに利点をもたらします。
- PyTorch* のベータ版チャネル・ラスト・メモリー・フォーマット (英語)
- 効率的な PyTorch*: テンソル・メモリー・フォーマットの重要性 (英語)
- メモリー・フォーマットを理解する (英語)
これはインテル® プロセッサーにも当てはまります。PyTorch* 向けインテル® エクステンションは、次に示す「チャネル・ラスト・メモリー・フォーマット」を使用することを推奨します。
model = model.to(memory_format=torch.channels_last)
input = input.to(memory_format=torch.channels_last)
oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (oneDNN) (英語) では、ベクトル化とキャッシュの再利用を向上するため、重みにブロック・メモリー・レイアウトを導入しています。実行時の変換を避けるため、oneDNN 操作の実行前に、重みを事前定義された最適なブロック・フォーマットに変換します。この手法は「Weight Prepacking (重みのプレパッケージ化)」と呼ばれ、ユーザーが PyTorch* 向けインテル® エクステンションで提供される ipex.optimize フロントエンド API を呼び出すと、推論とトレーニングの両方で有効になります。
PyTorch* 向けインテル® エクステンションは、DLRM のような推薦モデルで使用される Fused Interaction (融合相互作用) や Merged Embedding Bag (マージ埋め込みバッグ)、物体検出ワークロードの ROIAlign や FrozenBatchNorm など、よく利用されるトポロジーを高速化するカスタマイズ操作をいくつか提供しています。
オプティマイザーはトレーニング・パフォーマンスに大きく影響するため、PyTorch* 向けインテル® エクステンションでは、高度にチューニングされた融合オプティマイザーと分割オプティマイザーを提供しています。Lamb、Adagrad、SGD の融合カーネルは ipex.optimize フロントエンドで提供されるため、ユーザーはモデルコードを変更する必要がありません。このカーネルは、重み更新ステップで、モデルのパラメーターとその勾配に関連する一連のメモリー依存の操作を融合し、データをメモリーから再ロードすることなくキャッシュに常駐させます。今後のリリースでより多くの融合オプティマイザーを提供できるように取り組んでいます。
BF16 混合精度のトレーニングは、計算の高速化、メモリー帯域幅とメモリー使用量の軽減により、パフォーマンスを大幅に向上します。しかし、トレーニングの後半になると、重みの更新が小さくなりすぎて、蓄積されなくなります。一般に、重みのマスターコピーは FP32 で保持されますが、これは 2 倍のメモリー量を必要とします。メモリー使用量の増加は、推薦モデルのように多くの重みを必要とするワークロードに負担をかけるため、BF16 トレーニングには「分割」最適化を適用しています。FP32 パラメーターを上半分 (上位 16 ビット) と下半分 (下位 16 ビット) に分割します。上半分は、BF16 で表した数値と全く同じように見えます。下半分は、精度を保つために保持されます。前方および後方伝播を行う場合、上半分はインテル® CPU のネイティブ BF16 サポートの恩恵を受けることができます。パラメーター更新の際には、上半分と下半分を連結してパラメーターを FP32 に戻すことで、精度の低下を回避します。
