
この記事は、The Parallel Universe Magazine 49 号に掲載されている「The SigOpt* Intelligent Experimentation Platform」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

ストリーミング・サービスから e コマース・プラットフォーム、ソーシャル・ネットワークまで、あらゆるものが成長するにつれて、利用可能なデータや効率的なアルゴリズムの必要性も高まっています。これらのプラットフォームを強化し、エンドユーザーを惹きつけるため、推薦システムに投資する企業が増えてきています。最新の推薦システムでは、複雑なディープラーニング (DL) モデルに対して高いサービスレベル契約を確保しながら、膨大なデータ処理と特徴量エンジニアリングの両方を処理する複雑なパイプラインが必要とされます。さらに、これらの複雑な DL モデルは、トレーニング・コストを抑えつつ、最高のパフォーマンスを保証するため、常に更新と再トレーニングを行う必要があります。
この記事では、最新の推薦システムを運用する上での課題を紹介し、これらの課題に取り組むため、Apache Spark* をベースにした最適化された並列データ処理と、SigOpt AutoML によるユーザーガイド付きの自動モデル大衆化を含む、エンドツーエンド (E2E) の大衆化ソリューションを提案します。そして、このソリューションにより、一般的な推薦システムのワークロードにおいて、商用クラスター上で E2E パイプライン効率がどのように改善されるかを示します。
目的
推薦システムの課題
推薦システムの目的は、ユーザーに関するコンテキストと、すべての利用可能な嗜好に関するコンテキストに基づいて、ユーザーの嗜好を自動的に予測することです。推薦システムは、小売や e コマース、ヘルスケア、交通機関などにおいて着実に増加しています。プラットフォームによっては、自動推薦システムによる推薦が売上の 30% を占めることもあります。Amazon で消費者が購入する商品の 35%、Netflix でユーザーが視聴する商品の 75% は、それぞれ自動推薦からと言われています (出展: How Retailers Can Keep Up with Consumers (英語))。
図 1 に、データ処理とモデリングという 2 つの主要なワークストリームからなる最新の推薦システムのアーキテクチャーを示します。データ処理では、データの収集と前処理を行い、特徴量エンジニアリングを用いてモデルのトレーニングに使用する特徴量を生成します。モデリングは、モデルのトレーニングと供給の 2 つのサブカテゴリーに分類されます。
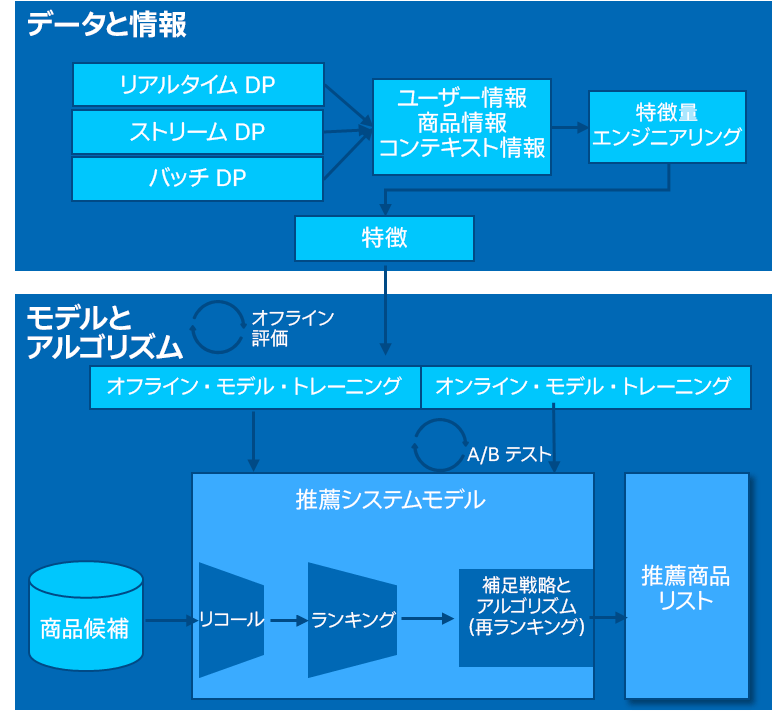
図 1. 推薦システムのアーキテクチャー
E2E 推薦システムの構築では精度が重要ですが、モデルやデータセットが大きくなりすぎると問題が発生します。
- 大規模なデータセット: 推薦システムは、しばしば大規模なデータセット (テラバイト、場合によってはペタバイト) を使ってトレーニングされるため、データの保存と処理に大規模なクラスターが必要になります。また、データ処理クラスターとトレーニング/ 推論クラスター間のデータ移動に時間がかかることも課題です。
- データの前処理: データセットの読み込み、クリーニング、前処理、および DL モデルやフレームワークに適した形式への変換が必要です。このため、処理するデータの種類に応じて、バッチ処理/ ストリーミング処理などの複雑なデータ処理が必要になります。
- 特徴量エンジニアリング: 多数の特徴量を作成し、設計し、テストする必要があるため、エラーが発生しやすく、時間がかかります。
- モデルとアルゴリズム: 企業は、最適なビジネス予測を行うため、複雑なモデルとアルゴリズムを開発します。これらのモデルには、深い専門知識と独自の能力が必要です。
- 実験の繰り返し: 最適なモデルを構築し、維持するためには、何度も実験を繰り返す必要があります。
- 膨大な埋め込みテーブル: カテゴリー特徴は、埋め込みと大量のメモリーを必要とし、帯域幅を大量に消費する傾向があります。
- 分散トレーニング: 重いモデルは通常、非常に高い計算能力を必要とするため、分散トレーニングが必須であり、ハードウェアとソフトウェアのスケーラビリティーが重要な課題となります。
人工知能 (AI) の大衆化
AI の大衆化の目的は、すべての組織やエンドユーザーが AI を安価に利用できるようにすることです。現在、AI の利用は、この分野で特別なトレーニングを受けたデータ・サイエンティストやデータアナリストに限定されています。そのため、より多くのユーザーが AI を利用できるようにすることが、AI の大衆化の目的の 1 つとなっています。さらに、AI は高価なハードウェアを必要とするため、データセンターに存在する一般的なハードウェアで AI をスケールさせることも、AI の大衆化の目的の 1 つです。
大衆化が必要な項目は複数あります。
- データ: AI はデータがなければ分析情報を生成できないため、データの大衆化が優先されます。 データ量だけでなく、データ品質の向上や容易なデータアクセスと高速化も重要です。
- インフラストラクチャー: AI の有効性は、インフラストラクチャーに依存します。 ソフトウェアとハードウェア・プラットフォームのアーキテクチャー、効率的なリソース割り当て管理、自動スケーリングは、すべてインフラストラクチャーの大衆化にとって重要な要素です。
- ハードウェア: AI は計算集約型であるため、特殊な、場合によっては高価なアクセラレーターを必要とします。 大衆化により、AI フレームワークを高価なアクセラレーターから一般的なハードウェアに移行し、コスト軽減を図ります。
- アルゴリズム: 正確な予測や推論を行うには、モデルやアルゴリズムが非常に複雑になる可能性があります。大衆化は、AI アルゴリズムの使用、開発、共有を容易にし、参入障壁を軽減します。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
