
この記事は、The Parallel Universe Magazine 48 号に掲載されている「Optimize End-to-End Artificial Intelligence Pipelines」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

エンドツーエンド (E2E) の人工知能 (AI) パイプラインは、特定のデータセットとモダリティーで問題を解決する 1 つ以上のマシンラーニング (ML)/ディープラーニング (DL) モデルと、複数の前処理および後処理ステージで構成されています。DL/ML モデルのトレーニングと推論、最適化されたデータ取り込み、特徴エンジニアリング、メディアコーデック、トークン化などとともに、ML、自然言語処理 (NLP) 、推薦システム、ビデオ解析、異常検知、顔認識を行うさまざまな最新の AI パイプラインに包括的な最適化アプローチを適用し、E2E パフォーマンスを向上させます。対象パイプラインすべて (ほとんどは推論ベース) にわたる結果から、最適な E2E スループットを得るには、すべてのフェーズを最適化する必要があることが分かります。大容量メモリー、AI アクセラレーション (インテル® ディープラーニング・ブースト (インテル® DL ブースト) (英語) など) 、汎用コードの実行に対応しているインテル® Xeon® プロセッサーは、これらのパイプラインに適しています。
最適化の内容は、(1) アプリケーション、フレームワーク、およびライブラリー・ソフトウェア、(2) モデルのハイパーパラメーター、(3) モデルの最適化、(4) システムレベルのチューニング、および (5) ワークロードの分割、に分けることができます。インテル® Neural Compressor (英語) などのツールは、量子化、蒸留、プルーニング、そしてインテル® DL ブーストやインテル® Xeon® プロセッサーに搭載されているほかの AI アクセラレーションを利用できるようにします。これにより、さまざまな E2E パイプラインで 1.8~81.7 倍のスピードアップを実現します。さらに、1 つまたは非常に限られた数の並列ストリームしかホストできないメモリー制限のあるアクセラレーターと比較して、インテル® Xeon® プロセッサーの高いコア数とメモリー容量により、これらのパイプラインの複数の並列ストリームまたはインスタンスをホストできます。多くの場合、ワークロードを CPU に統合可能であり、TCO と消費電力の面でもメリットがあります。
E2E AI アプリケーション
インテルでは、多くの E2E AI ユースケースとワークロードを紹介しています。それぞれが独自の前処理/後処理ステージを含み、ビデオ、画像、表、テキスト、その他のデータタイプに対して、異なる ML/DL アプローチを使用して実装されています (表 1)。
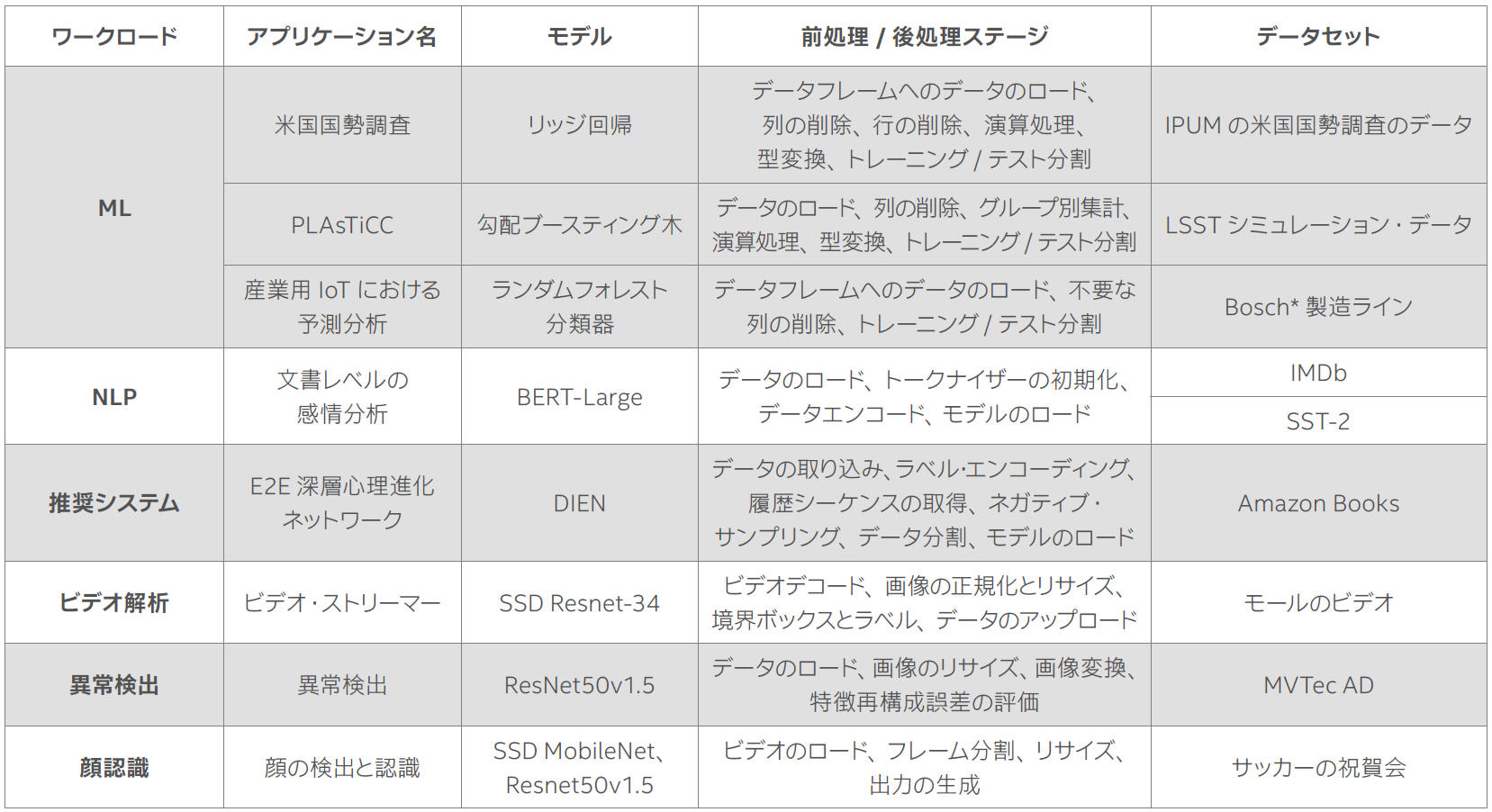
表 1. E2E AI アプリケーション
E2E AI アプリケーションは、通常、大きく分けて前処理/後処理と AI の 2 つの処理を行います。図 1 は、E2E の総実行時間に占めるそれぞれの処理の割合を示しています。前処理/後処理は 4~98% で、AI は 2~96% です。
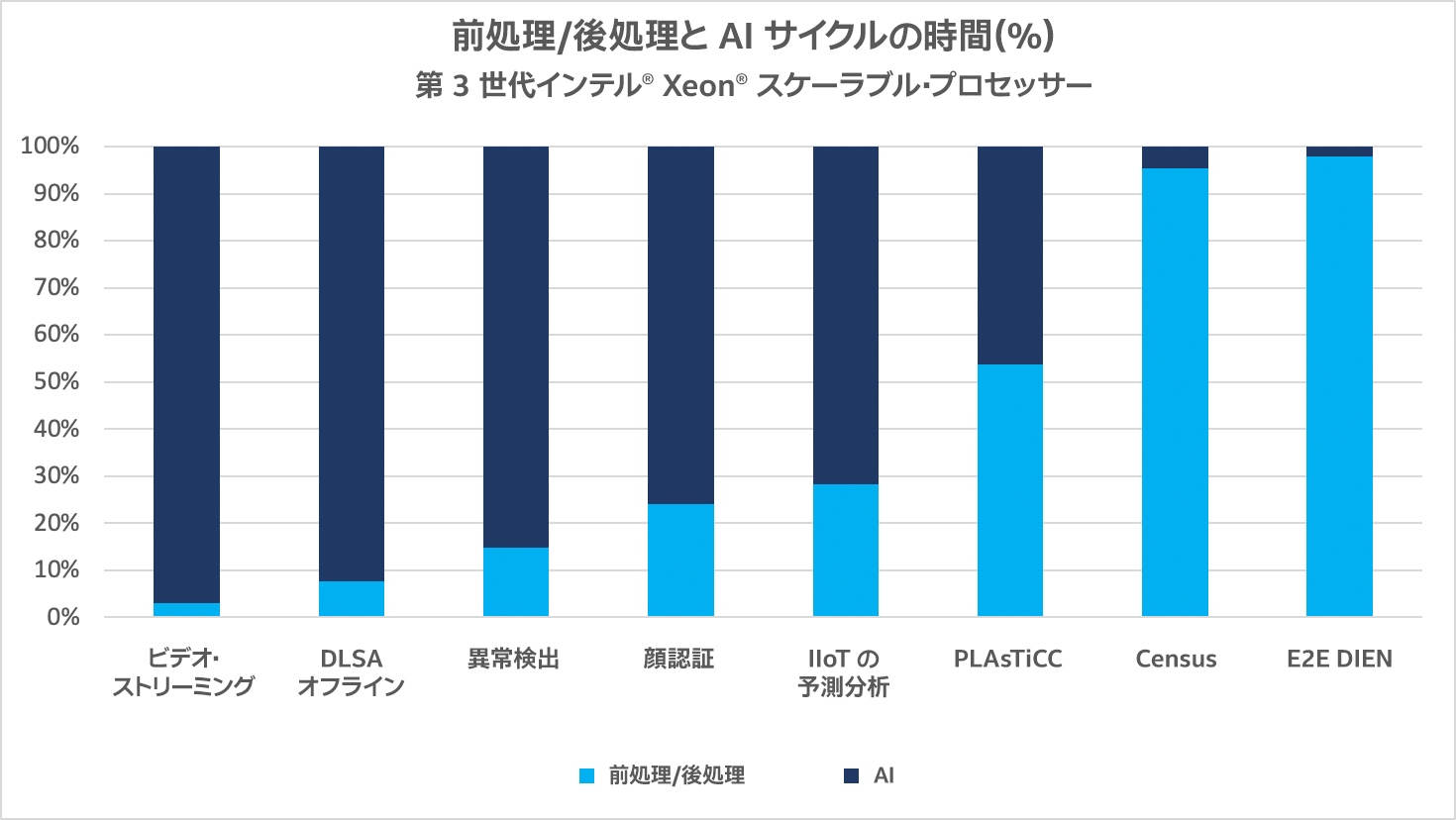
図 1. 前処理/後処理と AI の時間 (%)
米国国勢調査
Census (米国国勢調査) ワークロードは、1970年から 2010年までの米国国勢調査のデータを用いて、リッジ回帰モデルをトレーニングし、個人の教育水準と所得の相関を予測します (図 2)。ML に先立ち、データを取り込み、データフレーム操作を行い、モデルのトレーニング用の入力を準備し、特徴セットとそれに続く出力セットを作成します。
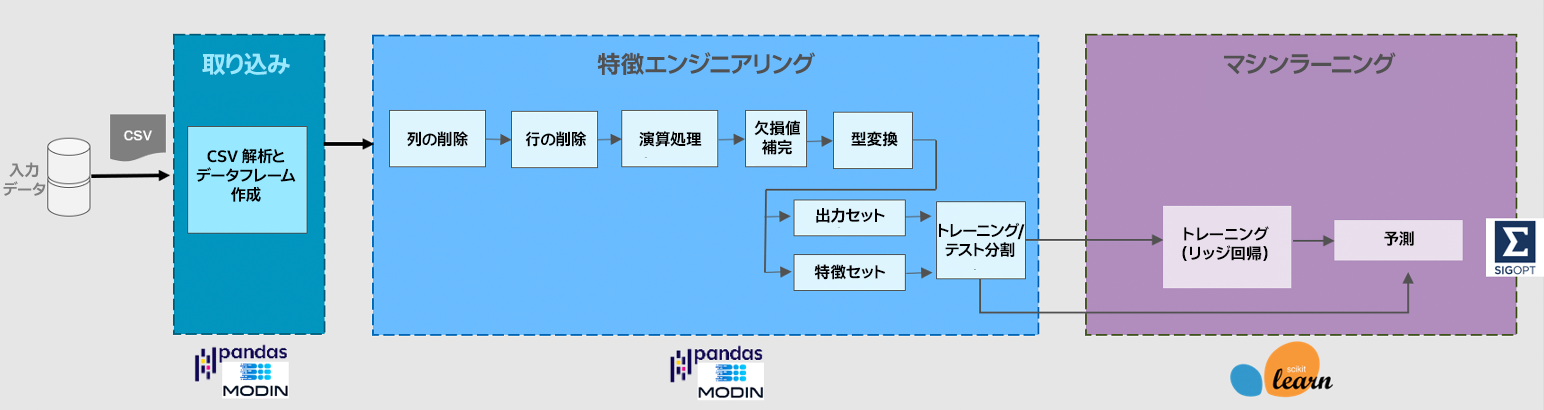
図 2. 米国国勢調査アプリケーションのパイプライン
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
