
この記事は、インテル® デベロッパー・ゾーンに掲載されている「Lowering Numerical Precision to Increase Deep Learning Performance」(https://www.intel.ai/lowering-numerical-precision-increase-deep-learning-performance/) の日本語参考訳です。
neon* ディープラーニング・フレームワークは、Nervana Systems* によって業界をリードするパフォーマンスを提供するため開発されました。2018 年現在、neon* フレームワークはすでにサポートを終了しています。代わりに、ここで紹介するインテルによって最適化されたフレームワークを使用することを推奨します。
ディープラーニングの訓練と推論は、今後数十年で計算上の負荷となる可能性があります。例えば、画像分類器を訓練するには、1018 の単精度演算を必要とします[1]。この需要から、ディープラーニング計算の高速化は、インテルと人工知能コミュニティー全体で重要な研究分野となっています。
インテルが特に注目している分野は、ディープラーニングの訓練と推論で低い精度の演算を行うことです。https://software.intel.com/en-us/articles/lower-numerical-precision-deep-learning-inference-and-training では、低い精度を使用したディープラーニングに関連する最近の研究を調査し、インテルがインテル® Xeon® スケーラブル・プロセッサーで低精度のディープラーニングをどのように促進しているかに注目して、現在と将来のマイクロアーキテクチャーでこれらをさらに加速する取り組みを紹介します。
低精度演算の利点
今日、大部分の商用ディープラーニング・アプリケーションは、訓練と推論ワークロードに 32 ビットの浮動小数点精度を利用しています。しかし、多くの研究から[2]、訓練と推論の両方で低い精度を使用しても結果の精度は失われないことが実証されています。
低精度には 2 つの利点があります。まず、多くのディープラーニング演算はメモリー帯域幅に依存します。この場合、精度を下げるとキャッシュ使用率が向上して、メモリーのボトルネックが減少する可能性があります。これにより、データをより迅速に移動して、演算リソースを最大限に活用できます。次に、低精度の乗算器はシリコンと電力を節約できます。ハードウェアは、1 秒あたりの演算数を増やすことができ、ワークロードをさらに加速できます。これらの利点から、低い精度の演算は、特に畳み込みニューラルネットワークにおいて近い将来標準的な手法になると予想されています。
インテル® Xeon® スケーラブル・プロセッサーにおける低精度演算
ホワイトペーパーでは、インテル® Xeon® スケーラブル・プロセッサーをベースとするプラットフォームが、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) の一部である 512 ビット幅の FMA (Fused Multiply Add) コア命令が低精度の乗算と高精度の累積によりディープラーニングを加速する方法を紹介しています。2 つの 8 ビット値を乗算してその結果を 32 ビットに累積するには 3 つの命令が必要であり、8 ビット・ベクトルの一方は unsigned int8 (u8) でもう一方は signed int8 (s8) で、累積には signed int32 (s32) が必要です。これにより、3 倍の命令コストを払って 4 倍の入力を可能にし、1/4 のメモリー容量で 33.33% 多い演算が可能になります。さらに、低い精度の命令はメモリー消費を減らし高い周波数で動作可能であるため、さらに高速に実行できます。詳細は図 1 をご覧ください。

図 1: インテル® Xeon® スケーラブル・プロセッサーは、3 つの命令で 32 ビットの累積と 8 ビットの乗算を実現します: VPMADDUBSW u8×s8→s16 乗算、VPMADDWD ブロードキャスト1 s16→s32、および VPADDD s32→s32 アキュムレーターへ結果を加算。これにより、3 倍の命令コストを払って fp32 の 4 倍の入力を可能にし、1/4 のメモリー容量で 33.33% 多い演算が可能になります。低い精度の命令はメモリー消費を減らし高い周波数で動作可能であるため、さらに高速に実行できます。画像の出典: Israel Hirsh。
低精度演算向けの今後の機能強化
AVX512_VNNI (ベクトル・ニューラル・ネットワーク命令) と呼ばれる新しいインテル® AVX-512 命令セットは、第 2 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Cascade Lake) でさらにディープラーニングの学習性能を向上せます。AVX512_VNNI には、図 2 に示す 8 ビット乗算 + 32 ビット累積 u8×s8→s32 を行う FMA 命令と、図 3 に示す 16 ビット乗算 + 32 ビット累積 s16×s16→s32 を行う FMA 命令が含まれます。理論上のピーク演算ゲインは、FP32 演算に対して INT8 演算は 4 倍、INT16 演算は 2 倍となります。実際は、メモリー帯域幅によるボトルネックが原因でゲインは低下する可能性があります。インテル® コンパイラーは、これら AVX512_VNNI 命令の生成をサポートしています。
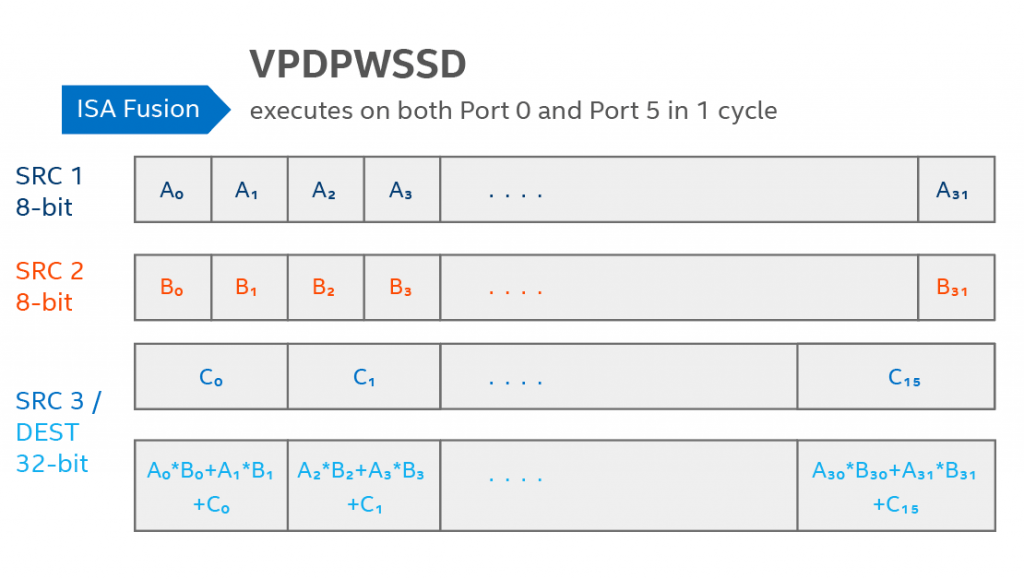
図 2: AVX512_VNNI は、1 つの命令で 32 ビットの累積と 8 ビットの乗算を実現します。図 1 のVPMADDUBSW、VPMADDWD、VPADDD 命令は、VPDPBUSD 命令 u8×s8→s32 に融合されます。これにより、FP32 の 4 倍の入力を可能にし、1/4 のメモリー容量で 4 倍 (理論上) の演算が可能になります。画像の出典: Israel Hirsh。

図 3: AVX512_VNNI VPDPWSSD 命令 16×s16→s32 は、16 ビットの乗算と 32 ビットの累積を可能にします。これにより、FP32 の 2 倍の入力を可能にし、1/2 のメモリー容量で 2倍 (理論上) の演算が可能になります。画像の出典: Israel Hirsh。
ディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN) と低精度プリミティブ
ディープ・ニューラル・ネットワーク向けのインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN) (英語) には、テンソルや高次元配列のレイアウトを操作する関数だけではなく、さまざまなモデルで使用される一般的なディープラーニング関数やプリミティブが含まれます。低精度のプリミティブをうまくサポートするため、畳み込み、ReLU、畳み込み + ReLU の融合、プーリングレイヤーで 8 ビット精度の推論ワークロード向けに新しい関数がインテル® MKL-DNN に追加されました。これには、リカレント・ニューラル・ネットワーク (RNN)、そのほかの融合演算、および推論向けの 8 ビット Winograd 畳み込みに加え、訓練向けの16 ビット関数があります。モデルの重みの量子化と活性化の手順、およびインテル® MKL-DNN で利用できる低精度関数については、https://software.intel.com/en-us/articles/lower-numerical-precision-deep-learning-inference-and-training を参照してください。
低精度演算向けのフレームワークのサポート
インテルは、インテル® Distribution for Caffe* (英語) で 8 ビット推論をサポートしました。インテルのディープラーニング推論エンジン (英語)、Apache* MXNet (英語)、および TensorFlow* (英語) の 8 ビット推論の最適化は、2018 年 Q2 以降に入手可能となっています。これら 8 ビットの最適化は、現在 CNN モデルのみに限定されます。RNN モデルとそのほかのフレームワークは、2018 年後半以降に入手可能となっています。ホワイトペーパーでは、低精度演算フレームワークのサポートに関する詳しいレポートと、ほかのディープラーニング・フレームワークで低精度の演算を行うために必要な変更などを説明しています。
低精度演算の詳細
インテルは、一般的なワークロードで広く使用されている、汎用性の高い、標準化されたインテル® アーキテクチャー向けに優れたディープラーニングのパフォーマンスを実現するべく取り組んでいます。低精度の演算は、ディープラーニングのワークロードを加速する大きな可能性を秘めています。インテルは、低精度演算の広範囲なサポートを提供するため、今後も努力を続けていきます。
インテル® Xeon® スケーラブル・プロセッサーで低精度演算を有効にする方法の詳細については、ホワイトペーパー「低い数値精度のディープラーニングの訓練と推論」(https://software.intel.com/en-us/articles/lower-numerical-precision-deep-learning-inference-and-training) を参照してください。さらに、インテル® アーキテクチャーでディープラーニングを加速する取り組みについては、AI.intel.com をご覧ください。
法務上の注意書きと最適化に関する注意事項
ベンチマーク結果は、「Spectre」および「Meltdown」と呼ばれる脆弱性への対処を目的とした最新のソフトウェア・パッチおよびファームウェア・アップデートの適用前に取得されたものです。パッチやアップデートを適用したデバイスやシステムでは同様の結果が得られないことがあります。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。詳細については、http://www.intel.com/benchmarks (英語) を参照してください。
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。実際の性能はシステム構成によって異なります。絶対的なセキュリティーを提供できるコンピューター・システムはありません。詳細については、各システムメーカーまたは販売店にお問い合わせいただくか、http://www.intel.co.jp/を参照してください。
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。
同じ SKU のインテル製プロセッサーであっても、製造工程における自然なばらつきにより、周波数や電力が異なる場合があります。
© 2019 Intel Corporation. Intel、インテル、Intel ロゴ、Xeon は、アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
[1] https://itpeernetwork.intel.com/science-engineering-supercomputers-ai/
[2] E.g., Vanhoucke, et al. (2011); Hwang, et al. (2014); Courbariaux, et al. (2015); Koster, et al.(2017); Kim and Smaragdis (2016)
