

この記事は、Dr.Dobb’s Go Parallel に掲載されている「Welcome to the Parallel Jungle!」 (http://www.drdobbs.com/go-parallel/article/232400273?pgno=3) の日本語参考訳です。
編集注記:
本記事は、2012 年 6 月 29 日に公開されたものを、加筆・修正したものです。
この一連の記事の著者である Herb Sutter 氏は、早い時期からプロセッサーのマルチコア化がソフトウェア開発に及ぼす影響と、ソフトウェア開発者が考えるべき移行における課題を示していました。Sutter 氏による 「フリーランチは終わった」は、IT 業界での名語録にもなっています。この記事は、Sutter 氏が 2012 年の時点で「ムーアの法則」の終焉とそれを取り巻くソフトウェア開発の変化をまとめているものです。2020 年時点で読み返しても興味深い内容です。
このシリーズでは、モバイルデバイスからデスクトップ、クラスター、最高粒度のクラウドまで、並列化がもたらす影響について解説します。さまざまな並列化の実装が存在することによる混乱は、プログラミングにおける大きな挑戦をもたらしました。シリアル・プログラミングでフリーランチの恩恵を受ける時代はすでに終わりを迎えています。
Part 1 | Part 2 | Part 3 | Part 4 | Part 5 | Part 6
グラフからプロセスをより解り易く視覚化できるように、メインストリームのハードウェアがグラフ上でどのように進化して来たかを確認しましょう。長い歴史を持つメインストリーム CPU と、最近の GPU から確認すると簡単です。
- 1970 年代から 2000 年代の間に、単純な 1 つのコアで始まった CPU は、振り子の揺れとともに複雑なコアへと移動しました。CPU は、単一コアのまま長い間グラフの左側に位置していましたが、2005 年にその余地を使い果たし、マルチコア NUMA キャッシュ・アーキテクチャーに移行しました。図 8 を参照してください。
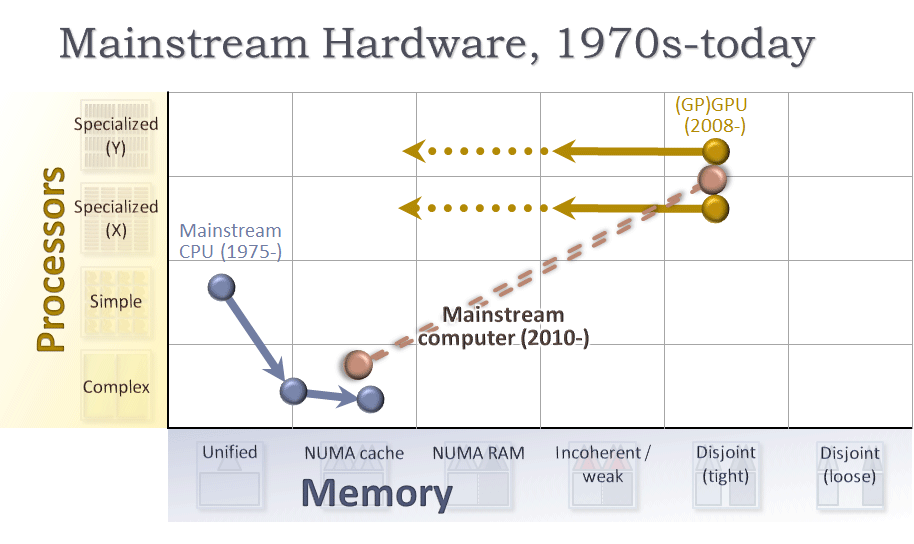 図 8.
図 8.
- 一方、2000 年代後半に、メインストリームの GPU は画像処理以外の計算にも利用できるようになりました。これらの GPU は、グラフィックス専用のコアとメモリーを物理的に CPU とシステム RAM から切り離したアドオンの外付け GPU カードとして登場したため、グラフの右上 (専用/ディスジョイント (密結合)) から始まっています。GPU はメモリーの共有を拡大するために左に移動しただけでなく、メインストリームの言語をサポートするため少し下にも移動しました (例外処理のサポートなど)。
- 現在の典型的なメインストリーム・コンピューターには、CPU と外付け/統合 GPU の両方が含まれています。グラフの点線は、(同じチップ上ではなく) 同じデバイス内にある、単一アプリケーションで利用可能なコアを示しています。
今我々が目にしているのは、同じダイ上に CPU コアと専用 (現在では GPU) コアを搭載し、密結合のメモリーを使用するというトレンドです。
- 2005 年には、XBox* 360 が、同じ RAM にアクセスできるだけでなく、L2 キャッシュを共有できるという、これまでにない特徴を備えたマルチコア CPU と GPU を搭載しました。
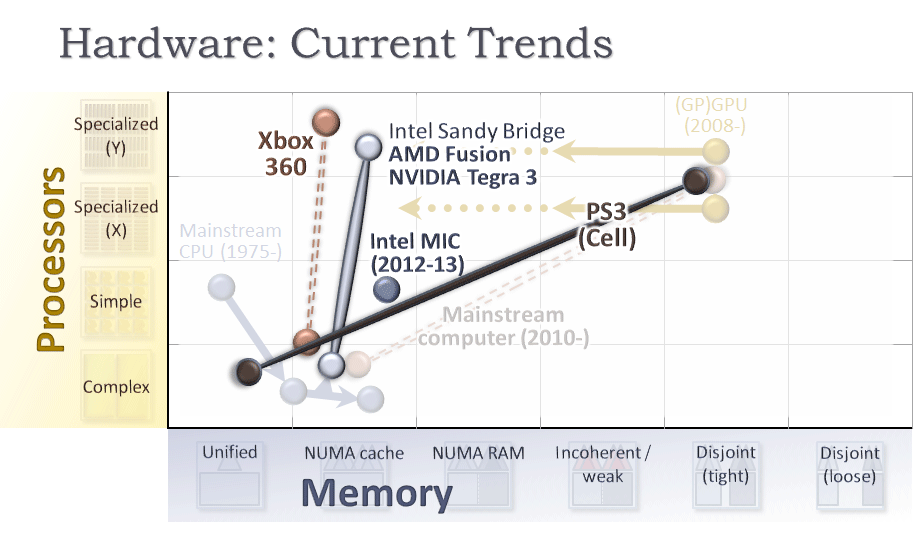 図 9.
図 9.
- 2006 年から 2007 年には、Cell ベースの PS3 コンソールが、1 つの汎用コアと 8 つの専用 SPU コアを搭載する単一プロセッサーを搭載しました。図 9 の実線は、同じデバイスにあるだけでなく、同じチップ上にあるコアを示しています。
- 2011 年 6 月には AMD* が Fusion* アーキテクチャーを、2011 年 11 月には NVIDIA* が Tegra* 3 アーキテクチャーを発表しました。これらのアーキテクチャーでは、同じダイ上に (グラフの左に位置) 計算 GPU を搭載した (縦に伸びた) マルチコア CPU が採用されています。
- インテルも、統合 GPU を搭載する Sandy Bridge✝ プロセッサーを出荷し、GPU の計算能力向上に取り組んでいます。インテルが開発を進めていた、同じダイ上に 50 個以上の単純な汎用 x86 コアを搭載したインテル® MIC アーキテクチャーのプロセッサーは、2012 年に出荷されました。
最後に、クラウド HaaS のグラフ (図 10) を完成させましょう。
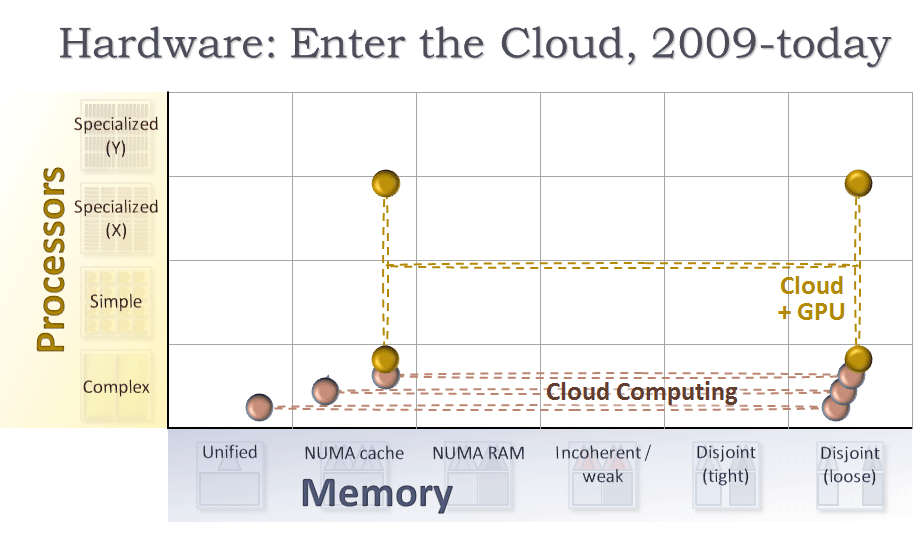 図 10.
図 10.
- 2008 年から 2009 年にかけて、Amazon*、Microsoft*、Google* をはじめ多くのベンダーがクラウドサービスを開始しました。AWS、Azure*、GAE は、クラウドの各ノードがシングルコアまたは複数の CPU コア (左下の 2 つのマス目) を搭載した従来型のコンピューター (「大きなコア」で疎結合、グラフの右下) である、Elastic な (伸縮自在な) クラウドをサポートしています。これまでと同様に、点線はすべてのコアが単一アプリケーションで利用できることを示しています。ネットワークは、ほかの計算コアへのバスという位置付けになります。
- 2010 年 11 月に、AWS は、CPU コアと GPU コアの両方を含む計算インスタンスをサポートしました。この仮想マシンは、各ノードに CPU コアと GPU コアの両方が含まれ、アプリケーションをディスジョイント・メモリー (右列) の疎結合ノードで実行するもので、グラフでは H 形になります (現在は CPU コアと GPU コアが同じダイ上にないため、縦線は点線のままです)。
ジャングル
これらをすべて重ねると、図 11 のように、さまざまな色や形が混在したものとなります。この難解なグラフを理解するため、2 つの点に注目しましょう。
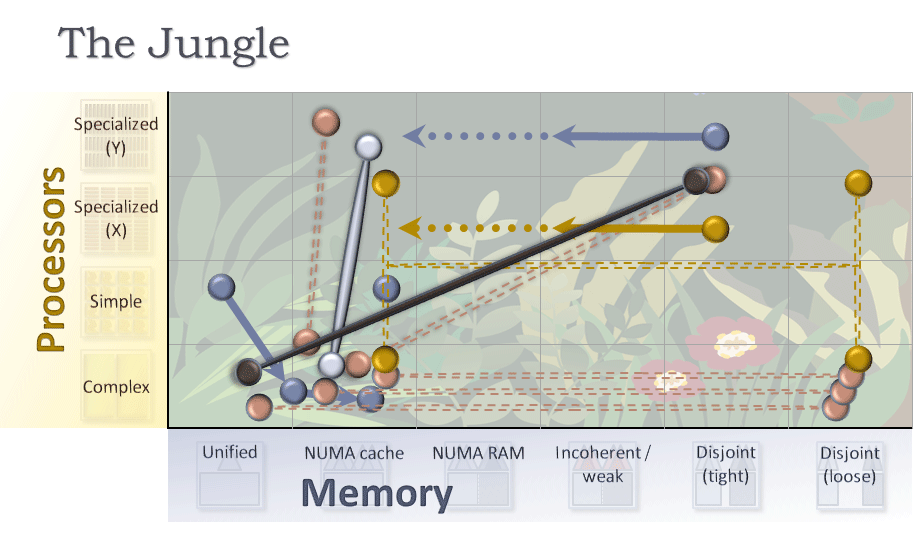 図 11.
図 11.
まず、すべてのマス目にはその時点で最良のワークロードが含まれていますが、一部のマス目 (特に一部の列) はより一般的です。次の 2 つの列はそれほど興味を引くものではありません。
- ユニファイド・メモリー・モデルはシングルコアにのみ適用可能で、メインストリームからは本質的に外れています。
- インコヒーレント/弱いメモリーモデルは、市場から姿を消そうとしています。ハードウェア側では、キャッシュをあまり同期しないという理論的なパフォーマンスの利点は、より強力なメモリーモデルのメインストリーム・プロセッサーにより、ほかの方法ですでに実現されています。ソフトウェア側では、メインストリームの汎用言語と環境 (C、C++、Java、.NET) はすべて弱いメモリーモデルに対応せず、唯一サポートしているメモリーモデル (Java、.NET) あるいはデフォルトのメモリーモデル (ISO C++11、ISO C11) としては、データ競合のないプログラム向けの連続した一貫性のある (http://is.gd/EmpCDn) コヒーレントモデルを採用しています。グラフの中央にあるインコヒーレント/弱いメモリー部分には誰も近づこうといていません。せいぜい、反対側に移動するために通り過ぎることがある程度です。
しかし、すべての行 (プロセッサー) を含むほかのマス目はさらなる発展を遂げており、同じアプリケーションの異なるコード領域を異なる種類のコアで実行するというスタイルが広がっていることが分かります。
次に、図 12 でハードウェアが移行しつつある 2 つの領域を強調してラベルを付けることで、グラフを明確にしましょう。
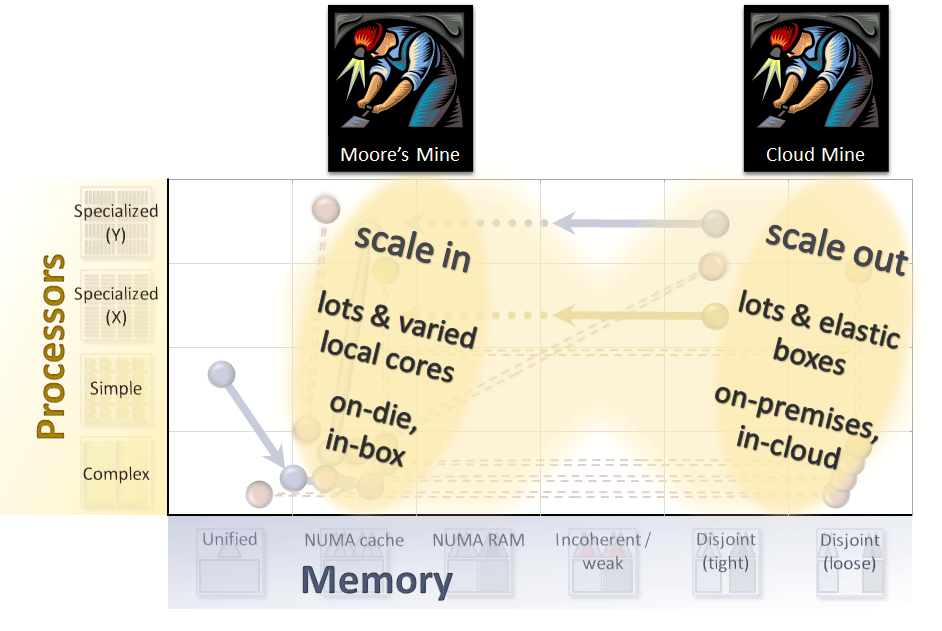 図 12.
図 12.
ここで再び、1 列目と 4 列目が重視されなくなり、ハードウェアのトレンドは徐々に 2 つの領域に集まっていることが分かります。どちらの領域も、すべての種類のコアにわたって縦に伸びています。最も注意すべき点は、これらは 2 つの鉱山 を表しているということです (左の領域がムーアの法則の鉱山)。
- 鉱山 #1: 「スケールイン」 = ムーアの法則。ローカルマシンは、インボックス (CPU と外付け GPU など) またはオンダイ (Sandy Bridge✝、Fusion*、Tegra* 3) で、多数のヘテロジニアス・ローカル・コアを引き続き使用します。コア数はムーアの法則が終了するまで増え続け、個々のローカルデバイスに適したコア数で安定するでしょう。
- 鉱山 #2: 「スケールアウト」 = 分散型クラウド。より重要なのは、オンプレミス (クラスター、プライベート・クラウドなど) またはパブリッククラウドで、大量のコアが計算クラウドを介して実際に提供されていることです。これは、結合度の低いディスジョイント・メモリー、特に疎結合の分散型ノードによって直接採鉱が可能になった全く新しい鉱山です。
良いニュースは、新しい鉱山を見つけたことにより、一息つけることです。さらに良いことは、新しい鉱山の成長率はムーアの法則よりもはるかに高い点です。さまざまなアーキテクチャー上で実行する単一アプリケーションで利用可能な並列処理の量を示した、図 13 の線の傾斜に注目してください。下の 3 つの線は、「スケールイン」成長率のムーアの法則の採掘によるもので、共通の傾斜 (同じダイ上に搭載できるコア数によって上下) はムーアの法則の素晴らしさを表しています。上の 2 つの線は、「スケールアウト」成長率のクラウド (CPU と GPU) の採掘によるもので、傾斜がより急になっています。
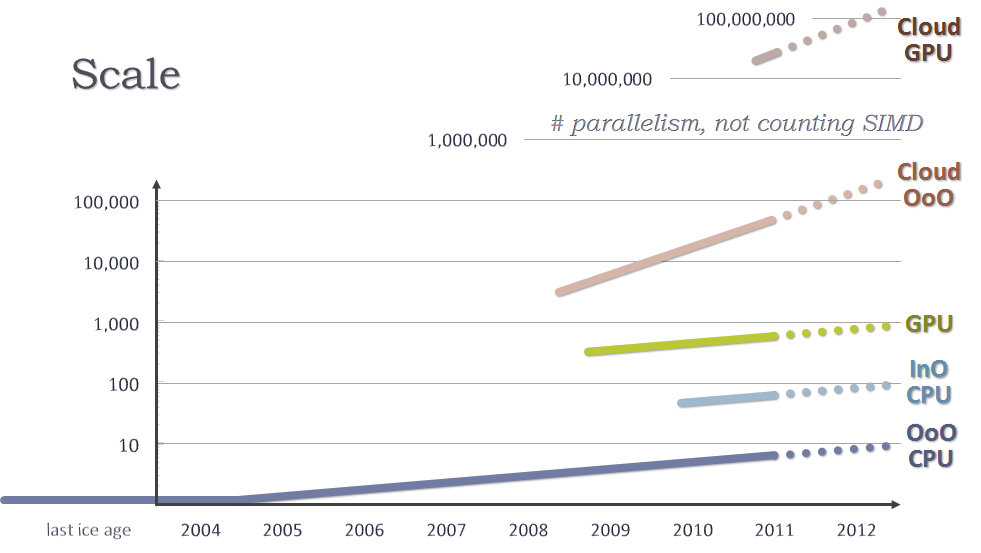 図 13.
図 13.
ハードウェア設計者がムーアの法則を使用してさらに大きなコアを設計した場合、ムーアの法則があと 5 年程度で終了すると仮定すると、オンデバイスのハードウェア並列処理は、次の 10 年間で 2 桁の伸びにとどまるでしょう。ハードウェアが Niagara* やインテル® MIC のようによりシンプルなコアに戻る場合は、一度大幅な性能向上があり、その後は 3 桁の伸びにとどまるでしょう。GPU を活用できた場合は、すでに最近のグラフィックス・カード (GPU では多少異なる意味になりますが、便宜上「コア」と呼びます) で 1,500 ウェイの並列処理が可能であることから、おそらく 5 桁の伸びに届くでしょう。
しかし、これらはすべて、クラウドのスケーラビリティーの前では影が薄れてしまいます。コスト効率の良い方法でトランジスターを素早く詰め込んで使用するよりも、コスト効率の良い方法でネットワーク接続されたマシンを素早く配備して使用するほうが成長率が高いため、線の傾斜はムーアの法則よりも急になっています。多くのプロジェクトはほぼ閉じた世界で行われるため、現時点で最大のクラウドシステムに関するデータを得ることは困難ですが、記録に残っている最大のパブリック・クラウド・アプリケーション (GPU を使用しない) は、単一計算に 3 万を超えるコアをすでに利用しています。今日では、10 万コアを超えるプロジェクトがあっても驚くことではありません。この数は汎用コアだけのものです。GPU ノードを追加すれば、さらにゼロを 2 桁追加できるでしょう。
大量の並列処理を実行する環境は劇的に変化し、今では 3 万コアのクラウドを 1 時間あたり $1,300 以下で利用できます。この変化が実感できない人は、次の問題を考えてみてください。強力なパスワードファイル (正しくハッシュで暗号化されソルトが追加されたファイルで、辞書パスワードを含まないと仮定) を盗んだ人が一般に利用可能な GPU 計算クラウドを使用してブルートフォース (総当り) 方式で 90% のパスワードを入手するのにどのくらい時間がかかるでしょうか? ヒント: AWS のデュアル Tegra* ノードは、1 秒に 200 億のパスワードをテストでき、3 万ノードのクラウドであることが公表されています (もちろん、アマゾンは使用している GPU ノードの数を明らかにしていませんが、たとえ現時点で下回っていても、まもなく到達することが予想されます)。この予想 (http://is.gd/PJGnVM) によれば、手頃な価格で毎秒 640 兆回テストできれば十分だと言われていました。もしそれで十分ではなくとも、心配ありません。数年後には、手頃な価格で毎秒 640 京回テストできるようになるはずですから。
✝開発コード名
