

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Practical Game Architecture for Multi-core Systems」(http://software.intel.com/en-us/articles/practical-game-architecture-for-multi-core-systems/) の日本語参考訳です。
最近のゲーム開発に使用されるプラットフォームは、モバイルデバイスや Web から、最新のマルチコア・プロセッサーを搭載した PC や Microsoft* Xbox 360*、Sony* PlayStation* 3 まで広範囲にわたっています。ハードウェアが決まっている単一プラットフォーム向けにゲームを開発する場合は、ハードウェアの設定を最大限に利用することができます。しかしながら、多種多様なプラットフォームが存在する市場の現状を考慮すると、多くの開発者はプラットフォームごとに専用のゲームエンジンを開発するだけのリソースを持ち合わせていません。
PC ハードウェアの急速な進歩に加えて、Xbox 360* や PlayStation* 3 コンソールが市場に登場してからすでにかなり経過しているため、ほとんどの場合は最新の PC のほうがコンソールよりもパフォーマンスが優れているといえるでしょう。ただし、少し工夫することで、複数の異なるプラットフォームに対応する柔軟なゲーム・アーキテクチャーを設計することができます。
メモリー・アーキテクチャーは重要?
PC だけでなく Xbox 360* や PlayStation* 3 コンソールでも、マルチコア・プロセッサーの能力を利用することができます。最近の PC には複数のコアを持つ任意の数のプロセッサーが搭載され、 Xbox 360* コンソールには 3 つのコアがあります。PlayStation* 3 のメインコアは 1 つだけですが、それとは別に 8 つの SPE (Synergistic Processing Elements) があり、開発者はそのうち 6 つを利用できます。
PC と Xbox 360* は UMA (Unified Memory Architecture) を採用しています。一方、PlayStation* 3 は NUMA (Non-unified Memory Architecture) を採用しています。PlayStation* 3 に搭載されている各 SPE には、SPU (Synergistic Processing Unit) と 256 KB ローカル・メモリー・ストレージ (すべて手動で管理) がありますが、コンベンショナル・メモリー・キャッシュはありません。そのため、SPU で処理を行う前に、DMA (Direct Memory Access) を使用して、データをメインメモリーから SPE のローカルメモリーに転送する必要があります。
最適なクロスプラットフォーム・コーディングのための考察
UMA 形式での開発手法は NUMA システムには向いていません。アルゴリズムが効率的ではないためです。PlayStation* 3 では、正しく構造化されていないデータは、メインメモリーと SPE 間でデータのやりとりが行われるため、無駄なサイクルの消費につながります。複数の SPE がメインメモリーの同じデータセットにアクセスする場合、デッドロックが発生する可能性が高くなるため、結果として複雑なスケジューリング・アルゴリズムが必要になります。この場合、データセットのサイズが重要になります。データを小さな単位にすることで、メモリーアクセスのデッドロックを回避できます。
データの移動にかかるコストを無視し、UMA で高速に実行可能なプロセッサー速度に最適化されたアルゴリズムは、NUMA システムでは無駄なサイクルを発生させます。メモリーのランダムアクセスは、ローカルメモリーへのデータ転送にサイクルがかかりすぎます。幸いなことに、データを細分化し NUMA DMA 転送を最適化することで、優れたキャッシュ・コヒーレンスにより、UMA プラットフォームで局所性とパフォーマンスが向上します。
PlayStation* 3 には設計上の制限があるため、通常は PlayStation* 3 向けのコードを記述し、それを Xbox 360* や PC 向けに変更するほうが良いでしょう。そのためには、すべてのプラットフォームで同じようなアルゴリズムとデータ構造を使用し、Xbox 360* と PC では条件付きコンパイルによって PlayStation* 3 向けのデータ転送用の DMA 固有のコードを排除します。
粗粒度と細粒度の並列化
ゲームによって基本アーキテクチャーは異なります。多くのシングルプレーヤー・ゲーム、そしてオフラインのマルチプレーヤー・ゲームでは、与えられた時間内に (レンダリング時間の 1 フレームまたはその他の間隔で) 一定の処理を行います。レンダラーなどのいくつかのスレッドは、非同期に実行することがあります。ゲームは、コントローラーからの入力を読み取り、プレーヤーが操作するキャラクター、人工知能 (AI) キャラクター、ゲーム全体のステートマシンを更新し、レンダラーに結果を送ります。
コーダーは、複数のプロセッサー上のコアに各種ゲームシステムを割り当て、異なるスレッドで並列に実行することができます。ここで重要な点は、ボトルネックとアイドル時間を最小限に抑えつつ、各コアまたは SPE をできるだけビジーにすることです。オンラインゲームでは、レイテンシーと決定性の問題から、ここで紹介するものとは異なる手法を使用します。
粗粒度の並列化
粗粒度の並列化では、ゲームシステム全体をスレッドレベルで分割します。大きなシステムは、そのシステム専用のスレッドに割り当てられます。インテル® Core™ i7 プロセッサーと Xbox 360* には各コアに 2 つのハードウェア・スレッドがあり、プロセッサーは 2 つのコンテキストまたはレジスターセット (ハードウェア・スレッドごとに 1 つずつ) を保持し、必要に応じて迅速に切り替えます。
ゲームシステムを分割する 1 つの方法として、すべてのシミュレーション・コントローラー、ゲームの状態とロジック、AI を 1 つのスレッドに割り当て、レンダリングとオーディオを個別のスレッドに割り当てることができます。例えば、Xbox 360* では、図 1 のようにシミュレーション、レンダリング、オーディオをそれぞれ異なるコアの別々のハードウェア・スレッドに割り当てられます。
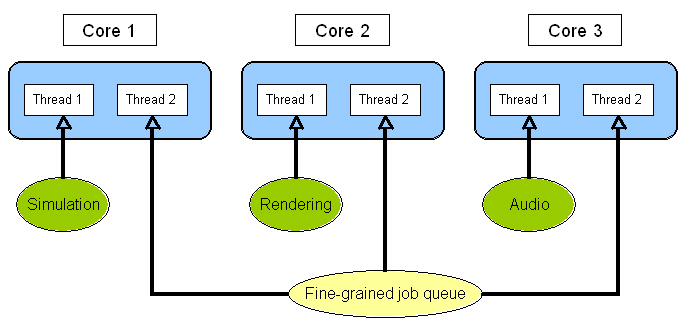
図 1. Xbox 360* におけるスレッドのレイアウト
PlayStation* 3 では、図 2 のようによりハイブリッドなアプローチが必要です。メインコアの 2 つのハードウェア・スレッドを使用し、各 SPE にスレッドを割り当てます。例えば、メインコア・スレッドの 1 つをシミュレーション・スレッドに、そしてもう 1 つをレンダリング・スレッドにすることができます。ただし、この方法では Xbox 360* とは異なり 2 つのスレッドが同じコアで実行するため、レンダラーとシミュレーション・スレッドの間で競合が発生する可能性があります。
通常、ゲームのパフォーマンスはレンダラーにより制限されるため、すべての SPE をメインコアのレンダリング・スレッドを支援するように割り当て、GPU と頻繁に通信しなければならないジョブをパイプライン化し、その作業を GPU (グラフィックス・プロセシング・ユニット) へ送るようにすると良いでしょう。
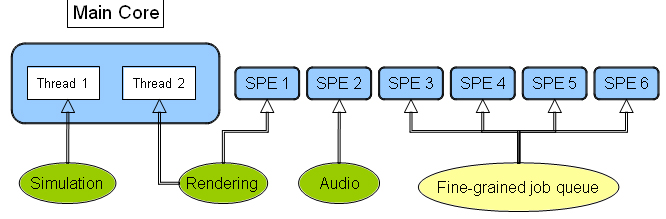
図 2. PlayStation* 3 におけるスレッドのレイアウト
Xbox 360* でも PlayStation* 3 でも、並列化する上でオーディオは重要なコンポーネントです。パフォーマンスの低下に伴いユーザー体験が線形的に低下するシミュレーションやレンダリングと異なり、オーディオは通常、クリックやポップといった形で一度に品質が低下します。そのため、Xbox 360* では通常オーディオスレッドはシステムコアに割り当てられ、PlayStation* 3 ではオーディオ専用の SPE があります。
細粒度の並列化
細粒度の並列化はジョブまたはタスクレベルで作業を分割します。個々のプロセッサーへのジョブ/タスクの分配とキューイングはバッチシステムによって管理されます。
PC と Xbox 360* では、ジョブはバッチ化され、利用可能なコアの未使用のハードウェア・スレッドに割り当てられます (図 3)。前述のように、大きなゲームシステムで 3 つのスレッドを使用する場合、Xbox 360* では残りの 3 つのセカンダリー・ハードウェア・スレッドを使って細粒度のジョブキューを処理します。PC では利用可能なコア数に応じてジョブを割り当て、 PlayStation* 3 では残りの未使用の SPE の 1 つにジョブを割り当てます。
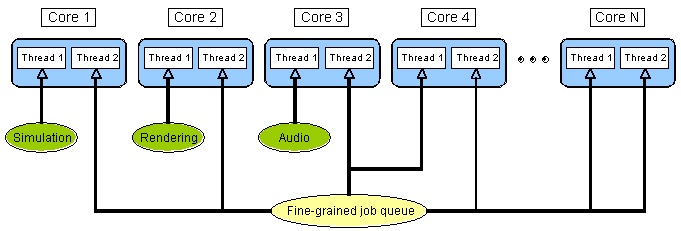
図 3. PC におけるスレッドのレイアウト
このタスク並列手法は、物理特性、可視カリング、粒子効果、アニメーションに向いています。
細粒度のジョブのバッチ (物理特性、カリングなど) を作成しキューに追加する高レベルのシステム (シミュレーションやレンダリングなど) を用いることで、経験豊富なコーダーは、計算時間がほぼ同じになるようにバッチのサイズを調整し、ロード・バランシングを行うことができます。そのためには、詳細なプロファイリングとボトルネックを排除するチューニングが必要になります。
優れたバッチ・ヒューリスティックは、プリミティブ型ごとの処理コストに基づいて各ジョブのコストを均一化します。例えば、物理衝突テストでは、球体よりも円柱の計算にコストがかかり、凸包では最も多くの処理が必要になります。細粒度のスレッドに送られるバッチサイズはプリミティブ型に応じて変わり、1 つのバッチ内で使用できる凸包の数はヒューリスティックにより制限されています。
サイズが小さく高コストなパケットを外に出すことで、各プロセッサーはより多くの作業が行えるようになります。パケット間の実行時間が大きく異なる場合はスタベーション (飢餓) が発生しますが、 均一化することで、高レベルのシステムが別のシステムのジョブの完了を長時間待機することがなくなり、全体のスループットが向上します。
計算集約型の物理計算では、制約の統合、衝突判定の実行、ブジェクトの相互貫通の解消を行います。このような計算では、オブジェクト A がオブジェクト B と交差するかどうか判断するために、多数のゲーム・オブジェクトを反復しなければならないことがよくあります。この場合、並列化の最初のステップでは、ゲーム・オブジェクト群のデータを衝突クエリーのパケット群にまとめます。そして、ジョブキューから細粒度のスレッドにパケットを送り、物理衝突処理を行います。
可視および閉塞カリングは個別のスレッドに割り当てたほうが良いでしょう。PlayStation* 3 では、バイナリー空間分割 (BSP) ツリー、8 分木、空間分割、ポータル、クラスタリングなどの高度な階層アルゴリズムよりもアーキテクチャーの長所を引き出しやすい総当たり式の線形カリング・アルゴリズムを採用しています。ツリー・アルゴリズムはキャッシュにより制限され、データの局所性が得られません。
単純な線形のボックスツーボックス (box-to-box) の可視テストは、SPU のような SIMD プロセッサーでは 5 サイクルしかかからないため、数百ボックスをパッケージ化することで数千オブジェクトのカリングを迅速に行うことができます。このようなテストには状態がなく、ほかのオブジェクトの以前の位置情報は必要としません。また、ツリーのバランス調整やデータセットの間引きが必要な階層アルゴリズムとは違い、すべてのフレームでコストが一定です。
キャラクター・ベースでバッチ化されたアニメーション・ジョブも並列化に適しています。この場合、キューには逆運動学 (IK)、ヘッド・トラッキング、骨格行列評価、ポーズ・ブレンディングなどの処理が追加されます。粒子系の非同期評価もほかのスレッドへ割り当てるのに最適なタスクといえるでしょう。
まとめ
1 つのメインコアと 6 つの SPE を持つ PlayStation* 3 は、3 つのメインコアを持つ Xbox 360* よりも優れているといえるでしょう。ただし、適切にチューニングされた粗粒度のプライマリー・スレッドは、Xbox 360* でより高速に実行します。これは、Xbox 360* のそれぞれのコアが汎用であるためです。PlayStation* 3 ではコアの競合が発生するため、メイン CPU で粗粒度のスレッドのパフォーマンスを引き出すことはできません。
PC ハードウェアの急速な進歩に加えて、Xbox 360* や PlayStation* 3 コンソールが市場に登場してからかなり経過しているため、ほとんどの場合は最新の PC のほうがコンソールよりもパフォーマンスが優れているといえるでしょう。PC の全体的なパフォーマンスは、システムで利用可能なコア数とゲームがどれだけ効率良くスレッド化されているかによって決まります。
完全な分散アプローチではなく、粗粒度/細粒度を組み合わせたアプローチを使用する理由
すべてのタスク/ジョブを同じようなサイズの作業に分割する完全な分散アプローチを使ってゲームシステムの開発を行いたいと思うかもしれません。確かに、そのほうが表面上は単純で洗練されたアルゴリズムのように見えるでしょう。細粒度のシステムでは、コンピューター・アーキテクチャーのコア数が増えるに従って、それらを最大限に利用することができます。これは、PC で実行するゲームを作成する場合に検討するべきです。
粒度が小さくなるにつれて並列に処理できる作業が増え、スケジューリングとロード・バランシングの選択肢が広がります。しかし、タスクの数が増えることで、コンテキスト・スイッチと同期にかかるコストがかさむだけでなく、メモリー使用量も増加します。
ゲームエンジンではさまざまなアルゴリズム、依存関係、プロセッサー、メモリー使用パターンがあるため、すべてのプラットフォームに対応可能な汎用タスキングシステムを設計することは困難です。多くの処理には、厳密な順序の依存関係があります。複雑な優先度キューなくしては、並列化によりゲームループに非決定性がもたらされ、コードフローが理解しづらくなります。これは、多数の不具合を短期間で修正しなければならない場合は特に問題となるため、よく検討する必要があります。
魅力的な動作でユーザーを魅了するオンスクリーン・キャラクターを作成するには、ゲームループはランダムなゲーム・オブジェクトに対して大量の条件付きイベント評価を行わなければなりません。AI やシミュレーションのサブシステムは互いに関連し合い、非効率な方法でキャッシュ上の全く異なるデータにアクセスします。これらの処理を適切に並列化するには、個々のすべてのシミュレーション変数をスレッドセーフにする必要があります。AI タスクを並列化することで達成可能な理論上のパフォーマンス向上は、スレッド間の mutex によるキャッシュミスとレイテンシーによって相殺されがちです。
PlayStation* 3 や Xbox 360* では、シミュレーションと AI の大半がシングルスレッドで実行されるため、パフォーマンス向上の可能性はほとんどありません。これが、シングル・プロセッサーからマルチコアへのハードウェアの進化に伴いレンダリングのパフォーマンスが大幅に向上しても、PlayStation* 3 や Xbox 360* においてそれに見合うだけのオンスクリーン・キャラクター数の増加が見られない理由の 1 つです。
前述の粗粒度/細粒度のシステムでは、必要に応じて細粒度の並列性を追加し続けることで、優れたスケーラビリティーが得られます。例えば、2 コアや 4 コアではなく、8 コアを搭載した PC では、粒子シミュレーションにおいてより多くのタスクをレンダリング・スレッドで処理する代わりに、個々のコアに割り当てることができます。
結論
ゲームでは、そのときどきのプレーヤーの操作によってタスクごとの実行時間が異なるため、柔軟なシステムを設計することが重要です。粒子効果を使用した大規模な爆発シーンでは、レンダリングによってゲームのパフォーマンスが制限されます。一方、大勢の群集が登場するシーンでより多くのキャラクターがプレーヤーに襲いかかるようにする場合は、シミュレーションによってゲームのパフォーマンスが制限されます。
前述のようなハイブリッド・アプローチでは、優れたキューイング・システムを設計することで、より多くの細粒度のタスクを粗粒度のスレッドからほかのスレッドに割り当てることができるようになります。さらに、インテル® グラフィックス・パフォーマンス・アナライザーのようなツールを使用することで、正確なプロファイリング結果を収集し、それぞれのコアを最大限に利用して、プレーヤーが夢中になれる体験を提供できるでしょう。
参考資料 (英語)
- 「On Processors, Cores and Hardware Threads」(http://software.intel.com/en-us/blogs/2008/10/29/on-processors-cores-and-hardware-threads)
- 「Application-customized CPU design: The Microsoft Xbox 360 CPU story」(http://www.ibm.com/developerworks/power/library/pa-fpfxbox)
- 「The Cell Broadband Engine: Exploiting multiple levels of parallelism in a chip multiprocessor」(http://domino.research.ibm.com/library/cyberdig.nsf/papers/1B2480A9DBF5B9538525723D0051A8C1/$File/rc24128.pdf) International Journal of Parallel Programming 2007 年 6 月
著者紹介
Katrina Archer は、現在 Activision Blizzard 社の子会社である Radical Entertainment 社でゲーム・プロジェクトに携わっているソフトウェア・エンジニアです。PC およびコンソールゲームの開発において 13 年以上の経験があり、 McGill University で工学士を、University of British Columbia で応用科学修士を取得しています。
記事のダウンロード
ダウンロード: マルチコアシステム向けの実用的なゲーム・アーキテクチャー (http://software.intel.com/file/33546)
インテル® ソフトウェア製品のパフォーマンス/最適化に関する詳細は、最適化に関する注意事項 (英語) を参照してください。
