この記事は、The Parallel Universe Magazine 58 号に掲載されている「Portable Data Parallel Extensions for Python* Language: Accelerate Computations Using GPUs」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

テクノロジーおよびソフトウェア業界でヘテロジニアス・プラットフォームが一般的になるにつれ、ベンダーやプラットフォームに依存しない方法でソフトウェアを開発し、パフォーマンス上のメリットを享受することが新たな課題となっています。この目的のため、Linux Foundation 傘下の Unified Acceleration Foundation (UXL) (英語) は、アクセラレーター・プログラミングのための、コンパイラーやパフォーマンス・ライブラリーを含むオープン・スタンダード・ソフトウェア・エコシステムを推進しています。この記事では、UXL ソフトウェア・エコシステムを Python に拡張し、ヘテロジニアス・プラットフォーム構成間での移植性とベンダー非依存を実現するとともに、ユーザーが同じ Python セッションで異なるベンダーのアクセラレーターを使って計算できるようにする方法について説明します。さらに、UXL Python エコシステムは、scikit-build や Meson などの標準 Python ツールと DPC++ コンパイラーを使用して、新しい移植可能なデータ並列ネイティブ Python 拡張機能を容易に作成できるようにします。
Python* 向けデータ・パラレル・エクステンションは、移植性の高い拡張機能の 1 つである dpctl.tensor を中心にして、統合共有メモリー (USM) 割り当てに基づく配列オブジェクト dpctl.tensor.usm_ndarray と、配列オブジェクトを操作する関数ライブラリーを実装しています。移植性という目標に沿って、dpctl.tensor ライブラリーは、NumPy バージョン 2.0 以降、CuPy、Dask、その他のコミュニティー・プロジェクト (JAX、PyTorch、TensorFlow) などの NumFocus が支援するプロジェクト (英語) で積極的に採用されているテンソル・フレームワークの標準である Python Array API 標準 (リビジョン 2023.12) (英語) に準拠するように設計されています。scikit-learn、SciPy など、従来は NumPy を利用して配列オブジェクトとそれを操作するライブラリーを提供していた Python パッケージは、Array API 準拠のライブラリーの配列オブジェクト・サポートを拡張し続けています。dpctl.tensor.usm_ndarray は、これらのパッケージで動作します。
データ・パラレル・コントロール Python パッケージ (dpctl) は、SYCL ベースの配列 API ライブラリーのリファレンス実装に加えて、Python からプラットフォーム列挙、デバイス選択、USM 割り当て、実行配置を容易にする DPC++ ランタイム・エンティティーへの Python バインディングも提供します。
dpctl は、Cython や pybind11 などの一般的な Python 拡張生成器との統合を提供し、データ並列ネイティブ拡張が Python オブジェクト型を操作し、それらを基礎となる C++ クラスにマップすることを可能にします。つまり、pybind11 では、dpctl.SyclQueue は sycl::queue に双方向にマップされ、dpctl.tensor.usm_ndarray は dpctl によって実装された dpctl::tensor::usm_ndarray C++ クラスにマップされます。
dpctl.tensor パッケージは純粋な SYCL を使用して実装されており、インテル® oneAPI DPC++ コンパイラーでビルドされています。このパッケージは、CodePlay の oneAPI for NVIDIA GPU (英語) と oneAPI for AMD GPU (英語) により、複数の SYCL ターゲットのビルドをサポートしており、ユーザーは同じ Python 環境で異なるベンダーのアクセラレーターをオフロードターゲットにすることができます。
インテルの GPU および CPU には SPIR-V オフロードセクション、NVIDIA GPU には NVPTX64 オフロードセクション、AMD GPU には AMDGCN が必要です。デフォルトでは、DPC++ は SPIR-V セクションのみを生成します。詳細は、SciPy 2024 でのプレゼンテーション (英語) を参照してください。プロジェクトが、対象のアクセラレーターに対応するドライバースタックに適したオフロードセクションを生成するようにコンパイルされている場合、このパッケージにより、Python ユーザーは DPC++ が対応するさまざまなデバイスと連携できます。
CUDA デバイス向けに dpctl をビルドするには、dpctl のドキュメント (英語) の手順に従ってください。
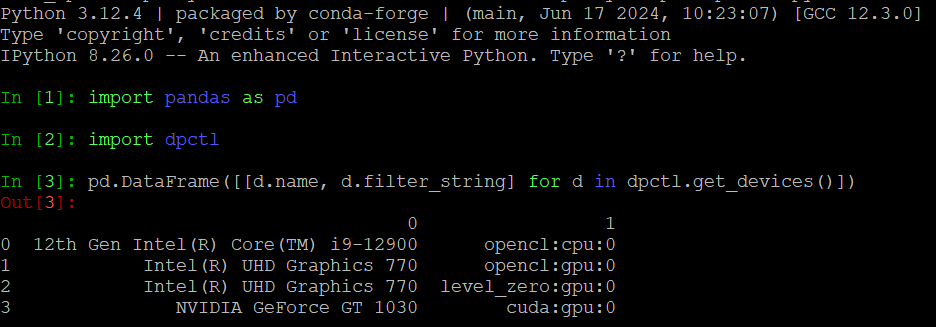
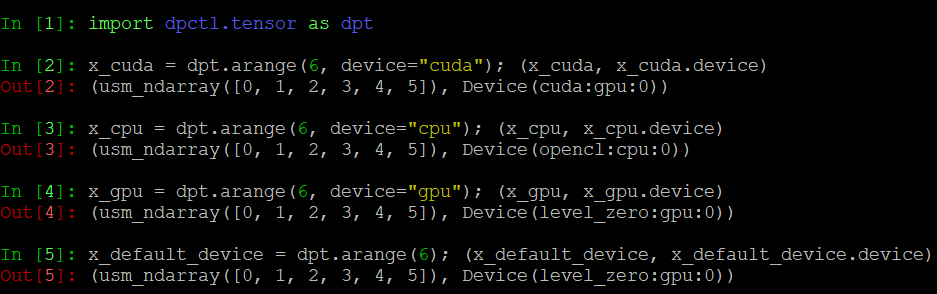
インテル® oneAPI DPC++ ランタイムが認識可能なデバイスは、dpctl でも認識されます。デフォルトでは、dpctl.tensor は SYCL のデフォルトセレクターによって選択されたデバイスをターゲットとします。特定のデバイスを選択するには、インテル® oneAPI SYCL 拡張のフィルターセレクター (英語) を使用します。フィルターセレクター文字列「backend:device_type:ordinal_id」は 3 つの要素で構成されており、少なくとも 1 つの要素が指定されていれば、残りの要素は省略できます。以下に、異なるデバイス上に算術シーケンスの値を格納する配列を作成する例を示します。