
この記事は、oneapi-src/oneAPI-samples (英語) で公開されている OpenMP Offload sample を iSUS で翻訳した日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
OpenMP オフロードのサンプルでは、インテル® oneAPI DPC++/C++ コンパイラーでサポートされている新しい OpenMP オフロード機能の一部を紹介します。詳細は、インテル® oneAPI DPC++ コンパイラーを参照してください。
| 内容 | 説明 |
|---|---|
| ガイドの内容 | 新しい OpenMP オフロード機能を理解する |
| 所要時間 | 15 分 |
目的
インテル® コンパイラーでサポートされている新しい OpenMP オフロード機能の一部を理解する
要件
| 最適化 | 説明 |
|---|---|
| OS | Ubuntu 18.04、20.04 |
| ハードウェア | Gen9 内蔵 GPU を搭載する Skylake 以降 |
| ソフトウェア | インテル® oneAPI DPC++/C++ コンパイラー |
このサンプルコードと原文の記事は Linux 環境でのコンパイルと実行について説明されていますが、変更なく、もしくは一部のリソースを変更することで、Windows 環境でも実行できます。日本語記事では Linux と Windows 環境でのコンパイルと実行について触れています。
ソースコードの詳細
以下の表は、設計と実証された機能を示しています。
| ソース | 内容 |
|---|---|
class_member_functor.cpp |
OpenMP オフロード領域でファンクターを使用 |
function_pointer.cpp |
オフロード領域内で関数ポインターを介して呼び出される関数 (現在は CPU ターゲットのみ) |
user_defined_mapper.cpp |
ターゲット領域 map 節のユーザー定義マッパー機能 |
usm_and_composabilty_with_dpcpp.cpp |
SYCL による統合共有メモリーとの相互運用 |
注: 各ソースファイルのリンクをクリックすると、ソースについての説明をご覧いただけます。
環境変数の設定
コマンドライン・インターフェイス (CLI) を使用する場合、環境変数を使用して oneAPI ツールキットを構成する必要があります。新しいターミナルウィンドウを開くたびに setvars スクリプトを実行して、CLI 環境を設定します。この方法により、コンパイラー、ライブラリー、およびツールの開発準備が整っていることが保証されます。
OpenMP オフロードプログラムのビルド
注: 環境を設定していない場合、oneAPI インストールのルートにある setvars スクリプトを source して CLI 環境をセットアップします。
Linux:
- システム全体へのインストールの場合:
. /opt/intel/oneapi/setvars.sh - プライベート・インストールの場合:
. ~/intel/oneapi/setvars.sh - csh など非 POSIX シェルの場合、次のコマンドを使用します:
bash -c 'source <install-dir>/setvars.sh ; exec csh'
Windows:
- [スタート] -> [すべて] -> [Intel oneAPI <バージョン>] から [Intel oneAPI command prompt for Intel 64 for Visual Studio <バージョン>] を開きます
環境変数の設定の詳細については、Linux* で setvars および oneapi-vars スクリプトを使用または Windows* で setvars および oneapi-vars スクリプトを使用を参照してください。
Visual Studio Code (VS Code) を使用する (Linux でのオプション)
Visual Studio Code (VS Code) 拡張機能を使用して、環境の設定、起動構成の作成、サンプルの参照とダウンロードを行うことができます。
VS Code を使用してサンプルをビルドおよび実行する基本的な手順を次に示します:
- インテル® oneAPI ツールキットの拡張機能である環境設定ツールを使用して、oneAPI 環境を構成します。
- インテル® oneAPI ツールキットの拡張機能であるサンプル・コード・ブラウザーを使用して、サンプルをダウンロードします。
- VS Code でターミナルを開きます ([ターミナル] > [新しいターミナル])。
- 以下の手順に従って、VS Code ターミナルでサンプルを実行します。
拡張機能と oneAPI 環境の構成方法の詳細については、Visual Studio Code でインテル® oneAPI ツールキットを使用するユーザーガイド (英語) を参照してください。
Linux / Windows
プログラムをビルドします。
mkdir build cd build cmake .. make
OS と cmake の環境によっては、インテル® DPC++/C++ コンパイラーがデフォルトコンパイラーとして設定されないことがあります。make コマンドでインテル® DPC++/C++ コンパイラーが起動されない場合、cmake .. に -D CMAKE_CCX_COMPILER=icpx を追加してください。また、Windows 環境で、Visual Studio で提供される cmake を使用すると、デフォルトでは Visual Studio プロジェクトのみが生成され、makefile が生成されません。その場合、cmake .. -G “NMake Makefiles” を使用すると、nmake で参照可能な makefile が生成できます。cmake で正しく makefile を生成できない場合、次のような makefile を使用してください。
# ソースがあるディレクトリーに make フォルダーを作成して、その配下でこの maiefile を実行します
CC=icx
CCX=icpx
SFLAGS=-fsycl -fsycl-targets=spir64
OFLAGS=-fiopenmp -fopenmp-targets=spir64
OPT= -O2 -w
DEBUG= -g
RM=del
SRC1=..\class_member_functor.cpp
SRC2=..\function_pointer.cpp
SRC3=..\user_defined_mapper.cpp
SRC4=..\usm_and_composability_with_dpcpp.cpp
all: prog1.exe prog2.exe prog3.exe prog4.exe
prog1.exe:
$(CC) $(SRC1) $(OFLAGS) $(OPT) $(DEBUG) $(LINK) -o prog1.exe
prog2.exe:
$(CC) $(SRC2) $(OFLAGS) $(OPT) $(DEBUG) $(LINK) -o prog2.exe
prog3.exe:
$(CC) $(SRC3) $(OFLAGS) $(OPT) $(DEBUG) $(LINK) -o prog3.exe
prog4.exe:
$(CCX) $(SRC4) $(SFLAGS) $(OFLAGS) $(OPT) $(LINK) -o prog4.exe
clean:
$(RM) *.exe *.obj *.pdb *.ilk *.d *.o
run_prog1:
prog1.exe
run_prog2:
prog2.exe
run_prog3:
prog3.exe
run_prog4:
prog4.exe
.SUFFIXES: .c .cpp .$(OBJ)
.c.$(OBJ):
$(CC) $(CFLAGS) $(OPTFLAGS) -c $<
.cpp.$(OBJ):
$(CC) $(CFLAGS) $(OPTFLAGS) -c $<トラブルシューティング
エラーメッセージが表示された場合、インテル® oneAPI ツールキットの診断ユーティリティーを使用して問題を解決してください。診断ユーティリティーは、解決されていない依存関係、権限エラー、その他の問題を見つけるのに役立つ構成およびシステムチェックを提供します。ユーティリティーの使用方法の詳細については、インテル® oneAPI ツールキットの診断ユーティリティーのユーザーガイド (英語) を参照してください。
OpenMP オフロードプログラムを実行
Linux
プログラムを実行します。
make run_prog1 make run_prog2 make run_prog3 make run_prog4プログラムをクリーンします。(オプション)
make clean
Windows
プログラムを実行します。
nmake run_prog1 nmake run_prog2 nmake run_prog3 nmake run_prog4プログラムをクリーンします。(オプション)
nmake clean
出力例
Prog1 の出力
6 8 10 12 14
Done ......Prog2 の出力
called from device, y = 100
called from device, y = 103
called from device, y = 114
called from device, y = 106
called from device, y = 109
called from device, y = 112
called from device, y = 115
called from device, y = 107
called from device, y = 104
called from device, y = 101
called from device, y = 102
called from device, y = 110
called from device, y = 113
called from device, y = 105
called from device, y = 111
called from device, y = 108
Output x = 1720Prog3 の出力
In : 1 2 4 8
Out: 2 4 8 16
In : 1 2 4 8
Out: 2 4 8 16
In : 1 2 4 8 16 32 64 128
Out: 2 4 8 16 32 64 128 256
In : 1 2 4 8 16 32 64 128
Out: 2 4 8 16 32 64 128 256Prog4 の出力
SYCL: Running on Intel(R) HD Graphics 630 [0x5912]
SYCL and OMP memory: passed
OMP and OMP memory: passed
OMP and SYCL memory: passed
SYCL and SYCL memory: passedライセンス
サンプルコードは、MIT ライセンスに基づいてライセンスされます。詳細は、License.txt (英語) を参照してください。サードパーティー・プログラムのライセンスは、third-party-programs.txt (英語) にあります。
class_member_functor.cpp
このサンプルコードは、OpenMP オフロード領域でファンクターを使用します。このサンプルコードは、次のように定義されています。#include <bits/stdc++.h> は gcc が C++ の機能をすべてインクルードする機能であり、Windows では使用できません。#include <iostream> に置き換えてください。ファンクターはループ・インデックス k = 0 から k < n に対して、5、6、7、8、9 を返します。
#include<bits/stdc++.h>using namespace std;classInc{private:intnum;public:Inc(intn) : num(n) {}intoperator()(intarr_num)const{returnnum +arr_num; }};intmain() {intarr[] = { 1, 2, 3, 4, 5 };intn =sizeof(arr) /sizeof(arr[0]);intadd5 = 5;Inca_inc(add5);// 5,6,7,8,9#pragma omp target teams distribute parallel for map(arr [0:n]) map(to : a_inc){for(intk = 0; k < n; k++) {arr[k] = arr[k] + a_inc(k);}}for(inti = 0; i < n; i++) cout<<arr[i]<<" ";cout<<"\n"<<"Done ......\n";}
サンプルコードを先に進める前に、OpenMP のオフロード構造について振り返ってみましょう。このサンプルの OpenMP 構文、
#pragma omp target teams distribute parallel for map(arr [0:n]) map(to : a_inc)
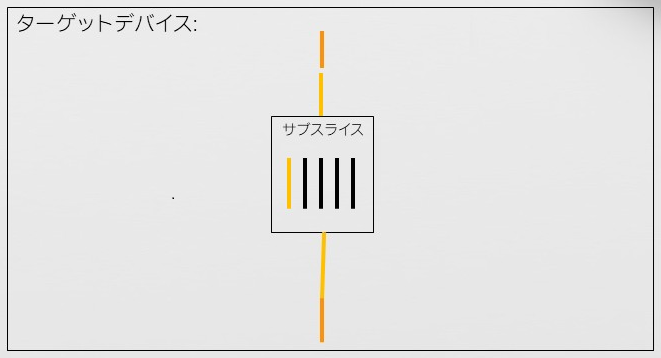
は、target、teams、distribute、parallel for 構造から成る複合構文です。複合構文は、複数の構文で構成され指定した構文が別々の意味を持ちます。target 構文は、領域をターゲットデバイスの 1 つのサブスライスにオフロードします。サブスライスは Xe Core に対応します。インテル® Xe GPU のビルディング・ブロックの詳細については、oneAPI GPU 最適化ガイドをご覧ください。
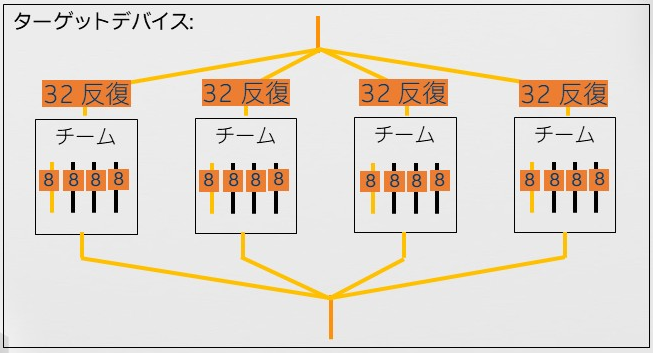
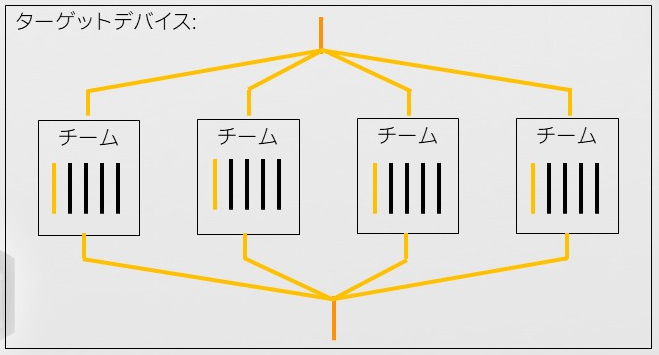
複数のサブスライス間でワークを分散するには、teams 構文でスレッドのチークを構成する必要があります。
しかし、target teams 構文だけでは、各チームがターゲット領域をそれぞれ個別に実行するだけです。各チームにワークを分散するには、distribute 構文が必要です。この構文を説明するため、128 回のループを 4 つのチームに分散することを想定します。distribute 構文は、ループ反復全体をチーム数に分割し、それぞれのワーク領域を各チームに分散します。そして最後の parallel for 構文が各チーム内のスレッドにチームに与えられたワークを分散します。
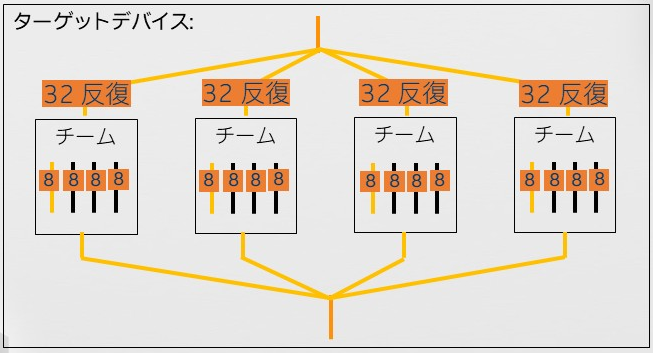
この例では、
#pragma omp target teams distribute parallel for map(arr [0:n]) map(to : a_inc){for(intk = 0; k < n; k++) {arr[k] = arr[k] + a_inc(k);}}
の for ループの反復はわずか 5 回であるため、target teams distribute 構造の例としてはあまり適していません。#pragma omp target parallel for だけでも適切に動作するでしょう。結果の書き込み先 arr[k] は、それぞれのチームのスレッド固有の場所であるため、同時に書き込みを行っても安全です。
この例では、#pragma omp target 構文で使用するファンクターが領域外で定義されていても安全に利用できることを示しています。map(arr [0:n]) map(to : a_inc) 節は、ホストとターゲットのメモリー転送を制御します。map(arr [0:n]) は、デフォルト属性である tofrom、つまりホストからターゲットにデータを転送し、結果をターゲットからホストに呼び戻すことを示し、map(to : a_inc) は、a_inc はホストからターゲットにデータを転送し、書き戻す必要なないことを示しています。ターゲット領域で使用するデータに対し、map 節を指定しないと、デフォルトは tofrom になります。次のように書き換えると、ここで説明した動作が分かり易いでしょう。
#pragma omp target map(arr [0:n]) map(to : a_inc)#pragma omp teams{#pragma omp distribute parallel forfor(intk = 0; k < n; k++) {arr[k] = arr[k] + a_inc(k);}}
function_pointer.cpp
このサンプルでは、オフロード領域外で定義される関数 foo がポインターを介してオフロード領域内で呼び出される例です。関数 foo は、#pragma omp declare target と #pragma omp end declare target で囲まれています。これは、この関数がターゲット領域で呼び出されるため、ターゲットに転送する必要があることを宣言しています。そして、int (*fptr)(int) = foo により、関数はポインター fptr を介して呼び出すことができます。OpenMP 5.2 に準拠するコンパイラーでは、declare target と end declare target は省略しても適切にコンパイルされますが、コードを読みやすくする上ではあった方がよいでしょう。
#pragma omp declare targetintfoo(inty) {printf("called from device, y = %d\n",y);returny;}#pragma omp end declare target…int(*fptr)(int) = foo;#pragmaomp target teams \distribute parallelfor\firstprivate(y) reduction(+: x) map(to: fptr)for(intk = 0; k < 16; k++) {fptr = foo;x = x + fptr(y + k);}…
ターゲット構造は、
#pragmaomp target teams \distribute parallelfor\firstprivate(y) reduction(+: x) map(to: fptr)
として定義されています。target teams distribute parallel for map(to: fptr) の動作は、前の例で説明したとおりです。firstprivate(y) reduction(+: x) は、parallel for 構文に影響します。firstprivate(y) は、y が割り当て済みの値 100 を初期値として処理を開始すること。reduction(+: x) は、for ループ内で結果を格納する変数 x は、単一の変数にすべてのスレッドが書き込みを行い競合が発生するため、内部的に + 操作のリダクション操作を行い、競合を回避することを示します。
user_defined_mapper.cpp
このサンプルコードは、#pragma omp declare mapper ディレクティブを使用してオフロード時の map 節で、構造体のメンバーごとに毎回詳細なマッピングを指定する手間を省き、一度定義したマッピングルールを再利用する例を示しています。
struct MyArr {int num;int *arr;};
この例で定義される構造体 MyArr を
#pragma omp declaremapper(id : MyArr c) map(c.num, c.arr [0:c.num])
のように declare mapper で定義することで、実際にターゲットデバイスを呼び出す omp target 構造で map(c.num, c.arr [0:c.num]) を毎回定義することなく、mapper(id) をとして簡略化できます。
#pragma omp target map(mapper(id), tofrom : c)…#pragma omp target map(mapper(id), tofrom : c_one)
構造体構造の変更を行っても、declare mapper 部分の定義を変更することで、omp target ディレクティブをそれに合わせて変更する必要がなくなります。
usm_and_composabilty_with_dpcpp.cpp
このサンプルコードは、OpenMP API を使用して割り当てられたメモリー領域を SYCL でオフロードされるカーネルで使用したり、SYCL で定義されたメモリー領域を OpenMP 構造で相互利用する例を示しています。メモリー領域は、それぞれ omp_target_alloc_shared (OpenMP) と malloc_shared (SYCL) で定義されます。
int *omp_mem = (int *)omp_target_alloc_shared(kSize * sizeof(int), d);int *dpcpp_mem =sycl::malloc_shared<int>(kSize, q);
ターゲットでメモリーが操作された後に、ホストでその内容を表示するため、それぞれ共有メモリーとして宣言されています。これにより、ターゲットで更新されたメモリーの内容を明示的にホストに転送する必要がありません。定義されたメモリーは、それぞれ次の呼び出しによりオフロードされます。
std::cout << "SYCL and OMP memory: " << TestDPCPP(omp_mem) << "\n";std::cout << "OMP and OMP memory: " << TestOmp(omp_mem) << "\n";std::cout << "OMP and SYCL memory: " << TestOmp(dpcpp_mem) << "\n";std::cout << "SYCL and SYCL memory: " << TestDPCPP(dpcpp_mem) << "\n";
"SYCL and OMP memory: " と "OMP and SYCL memory: " のメッセージがある行が、それぞれ OpenMP と SYCL の相互メモリー参照を行っています。
