 その他
その他 インテル® Optane™ DC パーシステント・メモリー導入への道: その 1 – 計画から装着まで
第 2 世代インテル® Xeon® スケーラブル・プロセッサーの発表に前後して、この新しい不揮発性メモリーの記事や資料をよく見かけるようになりました。iSUS では、今年導入した開発コード名 CascadeLake ベースのシステムで、イン...
 その他
その他  インテル® VTune™ プロファイラー
インテル® VTune™ プロファイラー  ゲーム
ゲーム  インテル® Parallel Studio XE
インテル® Parallel Studio XE  その他
その他  ゲーム その他
ゲーム その他  インテル® VTune™ プロファイラー
インテル® VTune™ プロファイラー  OpenVINO™ ツールキット
OpenVINO™ ツールキット 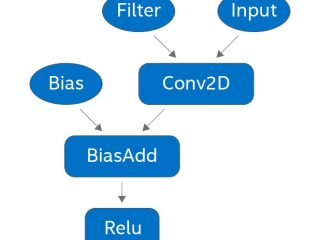 インテル® oneMKL
インテル® oneMKL 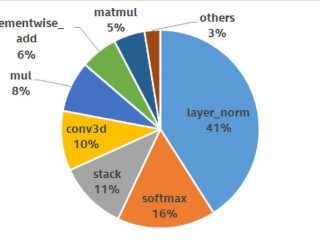 インテル® oneMKL
インテル® oneMKL 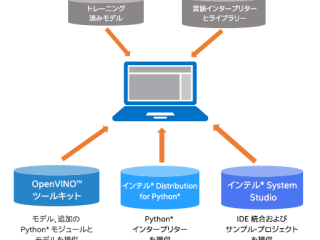 OpenVINO™ ツールキット
OpenVINO™ ツールキット  インテル® Advisor
インテル® Advisor 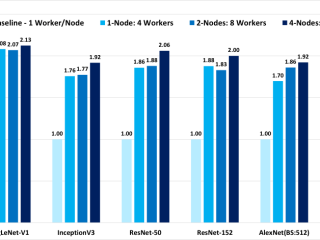 マシンラーニング
マシンラーニング  イメージ
イメージ 