

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Getting Started with OpenMP*」 (http://software.intel.com/en-us/articles/getting-started-with-openmp/) の日本語参考訳です。
はじめに
マルチコア・プロセッサーでパフォーマンスを最大限に引き出すには、アプリケーションを並列実行する必要があることは、皆さんはすでにご存知でしょう。並列実行にはスレッドが必要で、アプリケーションのスレッド化は容易ではありません。しかし、OpenMP* などのツールを使用することで、このプロセスを容易に行うことができます。
このホワイトペーパーは、経験豊富な C/C++ プログラマーに、OpenMP* を使ってマルチコア・プロセッサーの性能を最大限に活用する方法を紹介するシリーズ (全 3 つ) の 1 つ目です。ここでは、ワークシェアリングと呼ばれるループの並列化方法を説明します。2 つ目のホワイトペーパーでは、ループ以外の並列化と OpenMP* 機能の活用方法について説明します。最後のホワイトペーパーでは、OpenMP* ランタイム・ライブラリー関数およびインテル® C++ コンパイラーについて説明し、問題が発生した場合にアプリケーションをデバッグする方法も紹介します。
OpenMP* の概要
OpenMP* は、プログラマーがスレッドを作成、同期、破棄する方法を知らなくても、あるいは作成するスレッド数を指定しなくても、アプリケーションを容易にスレッド化できるように設計されています。OpenMP* では、プラットフォームに依存しないコンパイラー・プラグマ、宣言子、関数呼び出し、および環境変数を使用して、アプリケーションのどこに、どのようにスレッドを挿入するかコンパイラーに明示的に指示します。
ほとんどのループは、直前にプラグマを 1 つ追加するだけでスレッド化できます。さらに、具体的な処理の詳細をコンパイラーと OpenMP* に任せることにより、どのループをスレッド化すべきか、パフォーマンスを最大限に向上させるにはどのようにアルゴリズムを再編成すべきかといった決断により多くの時間をかけることができます。OpenMP* は、”hotspot” (アプリケーションで最も時間のかかるループ) のスレッド化に使用されると、最大限のパフォーマンスを達成します。
以下の例は、OpenMP* がいかに強力でシンプルかを示すものです。このループは、32 ビットの RGB (赤、緑、青) ピクセルを 8 ビットのグレースケール・ピクセルに変換します。並列実行に必要なのは、ループの直前に挿入された 1 つのプラグマだけです。
#pragma omp parallel for
for (i=0; i < numPixels; i++)
{
pGrayScaleBitmap[i] = (unsigned BYTE)
(pRGBBitmap[i].red * 0.299 +
pRGBBitmap[i].green * 0.587 +
pRGBBitmap[i].blue * 0.114);
}
ループを詳細に見てみましょう。最初に、この例ではワークシェアリングを使用しています。OpenMP* では、スレッド間で作業を分配することをワークシェアリングと呼びます。この例のようにワークシェアリングを for 構造とともに使用した場合、ループの反復は複数のスレッドに振り分けられます。作成するスレッド数、および作成、同期、破棄の方法は、OpenMP* ランタイムが決定します。プログラマーは、どのループをスレッド化するかを OpenMP* に指示するだけです。
OpenMP* には、ループのスレッド化において次の 5 つの制約があります。
- ループ変数は符号付き整数でなければなりません。符号なし整数 (DWORD など) は使用できません。
- 比較操作は、loop_variable <、<=、>、または >= loop_invariant_integer 形式でなければなりません。
- for ループの 3 番目にあるループ式 (増分処理) は、ループ不変値による整数の加算または減算でなければなりません。
- 比較操作が < または <= の場合、ループ変数は各反復時に増分しなければなりません。逆に、比較操作が > または >= の場合、ループ変数は各反復時に減分しなければなりません。
- ループは基本ブロックでなければなりません。つまり、アプリケーション全体を終了する exit 文を除き、ループの内側から外側へのジャンプは許可されていません。goto 文や break 文を使用する場合、これらの文はループ内 (並列領域内) でのみジャンプでき、ループ外にはジャンプできません。同様に、例外処理もループ内で行う必要があります。
これらの制約に合致しないループでも、制約に従うよう簡単に書き換えることができます。
コンパイルの基本
OpenMP* プラグマを使用するには、OpenMP* 互換コンパイラーとスレッドセーフ・ライブラリーが必要です。インテル® C++ コンパイラー 7.0 以上を使用すると良いでしょう (インテル® Fortran コンパイラーでも OpenMP* をサポートしています)。コンパイル時に /Qopenmp (-openmp) オプションを追加すると、コンパイラーは OpenMP* プラグマを認識し、スレッドを挿入します。
/Qopenmp (-openmp) オプションを省略すると、コンパイラーは OpenMP* プラグマを無視します。つまり、ソースコードを変更することなく、シングルスレッド・バージョンを簡単に生成することができます。歴代のインテル® C++ コンパイラーは、次の OpenMP* 仕様をサポートしています。
インテル® コンパイラー 7.0、8.0 OpenMP* 2.0
インテル® コンパイラー 9.0、10.0 OpenMP* 2.5
インテル® コンパイラー 11.0、12.0 OpenMP* 3.0
インテル® コンパイラー 12.1 OpenMP* 3.1
最新情報については、インテル® C++ コンパイラーのリリースノートと互換性情報を確認してください。OpenMP* 仕様の詳細は、http://www.openmp.org (英語) から入手できます。
条件付きコンパイルでは、コンパイラーは _OPENMP マクロを利用します。必要に応じて、次の例のようにこのマクロをテストすることができます。
#ifdef _OPENMP
fn();
#endif<
すべての OpenMP* プラグマは、pragma omp で始まります。
pragma omp で始まらない行は、OpenMP* プラグマではありません。プラグマの一覧は、http://www.openmp.org (英語) にある仕様を参照してください。
スレッドセーフな C ランタイム・ライブラリーを選択するには、コマンドラインで /MD または /MDd (デバッグ用) コンパイラー・オプションを指定します。Microsoft* Visual C++* では、[Project (プロジェクト)] > [Properties (プロパティ)] > [C/C++] > [Code Generation (コード生成)] で [Multithreaded DLL (マルチスレッド DLL)] または [Debug Multithreaded DLL (マルチスレッド デバッグ DLL)] を選択します。
簡単な例
次の例では、OpenMP* がどの程度簡単に利用できるかを示します。一般的にはいくつかの問題に対処する必要がありますが、ここでは基本的な使用について説明します。
例 1: 配列の値を 0 ~ 255 の範囲に限定するループを OpenMP* プラグマを使ってスレッド化します。
解決方法: ループの直前にプラグマを挿入するだけでスレッド化できます。
例 2: 0 ~ 100 の平方根の表を生成するループを OpenMP* を使ってスレッド化します。
解決方法: ループ変数は符号付き整数ではないので、ループ変数の属性を変更し、プラグマを追加する必要があります。
データ依存と競合状態の回避
ループが前述の 5 つの制約をすべて満たし、コンパイラーがループをスレッド化しても、データ依存が原因でループが正しく動作しない場合があります。データ依存は、ループの異なる反復 (厳密には、異なるスレッドで実行されるループの反復) が共有メモリーの読み取り、または書き込みを行った場合に発生します。階乗を計算する次の例について考えてみましょう。
// このループはデータ依存により実行に失敗する
// 各ループ反復が他の反復が読み込んでいる変数を書き込んでいる
#pragma omp parallel for
for (i=2; i < 10; i++)
{
factorial[i] = i * factorial[i-1];
}
コンパイラーはこのループのスレッド化を試みますが、少なくとも 1 つの反復が異なる反復のデータに依存しているため実行に失敗します。このような状態を競合状態と呼びます。競合状態は、共有リソース (メモリーなど) と並列実行を使用した場合にのみ発生します。この問題を解決するには、ループを書き換えるか、競合状態のない別のアルゴリズムを使用します。
競合状態を検出するのは困難です。場合によっては、たまたま正しい順序で実行され、競合が発生せずにプログラムが正しく動作することがあるからです。一度正常に実行できたからといって、そのプログラムが常に正常に実行できるとは限りません。
ハイパースレッディング・テクノロジーに対応したマシンや複数の物理コア/プロセッサーを搭載したマシンなど、さまざまなマシンでプログラムをテストしてみると良いでしょう。インテル® Parallel Inspector やインテル® Inspector XE などのツールが役立ちます。従来のデバッガーでは、1 つのスレッドが競合を停止してもその間、他のスレッドは継続的かつ著しくランタイム動作を変更するため、競合状態の検出には役立ちません。
共有データとプライベート・データの管理
(実際のアプリケーションでは) ほぼすべてのループがメモリーからの読み取り、またはメモリーへの書き出しを行います。開発者は、どのメモリーをスレッド間で共有し、どのメモリーをプライベートとして保持するのかをコンパイラーに指示する必要があります。
メモリーが共有の場合は、すべてのスレッドが同じメモリーの場所にアクセスします。プライベートの場合は、スレッドごとに個別の変数 (プライベート・コピー) が作成され、ループの最後にプライベート・コピーは破棄されます。デフォルトでは、プライベートなループ変数を除き、すべての変数は共有されます。プライベートとしてメモリーを宣言するには、次の 2 つの方法があります。
- static キーワードを指定しないで、変数をループの内側 (OpenMP* の parallel 構文内) で宣言する
- OpenMP* 宣言子で private 節を指定する
次の例では、変数 temp が共有であるためにループは正しく動作しません。プライベートにする必要があります。
// 共有メモリーを利用しているため失敗する例
// 変数 temp はすべてのスレッドで共有される
// 1つのスレッドが読み込んでいる間に他のスレッドが書き込むかもしれない
#pragma omp parallel for
for (i=0; i < 100; i++)
{
temp = array[i];
array[i] = do_something(temp);
}
次の 2 つの例では、変数 temp はプライベート・メモリーとして宣言されているため、問題が解決されています。
// この例は正常に動作する。変数 temp はプライベートになる
#pragma omp parallel for
for (i=0; i < 100; i++)
{
int temp; // parallel 構文内で変数を宣言するため、変数はプライベートになる
temp = array[i];
array[i] = do_something(temp);
}
// この例も正常に動作。変数 temp の属性をプライベートに変更
#pragma omp parallel for private(temp)
for (i=0; i < 100; i++)
{
temp = array[i];
array[i] = do_something(temp);
}
OpenMP* を使用してループを並列化する際は、すべてのメモリー参照 (呼び出された関数による参照を含む) を慎重に検証することを推奨します。並列構造内で宣言された変数は、static 宣言子を使用して宣言されている場合を除き (static 変数はスタックに割り当てられないため)、プライベートとして定義されます。
リダクション
値を累積するループは一般的ですが、OpenMP* ではこのようなループ専用の節を用意しています。整数の配列の合計を計算する次のループについて考えてみましょう。
sum = 0;
for (i=0; i < 100; i++)
{
sum += array[i];
// 正しい結果を生成するには、変数 sum は共有でなければならない
// しかし、競合を排除するには変数 sum はプライベートでなければいけない
}
上記のループでは、変数 sum は正しい結果を生成するために共有し、複数のスレッドによるアクセスを許可するためにプライベートにしなければなりません。このようなケースに対応するため、OpenMP* ではループの 1 つ以上の変数の演算リダクションを効率的に結合する reduction 節が提供されています。次のループでは、正しい結果を出力するために reduction 節を使用しています。
sum = 0;
#pragma omp parallel for reduction(+:sum)
for (i=0; i < 100; i++)
{
sum += array[i];
}
上記の例では、OpenMP* は各スレッドに対して変数 sum のプライベート・コピーを用意し、スレッドの終了時に値を加算して、その結果を変数 sum のグローバルコピーにマージします。
次の表は、OpenMP* 3.0 仕様で利用可能なリダクションと一時的なプライベート変数の初期変数 (演算識別値でもある) のリストです。

並列構造で変数とリダクションをカンマ区切りで指定することによって、ループで複数のリダクションを使用することもできます。次の条件を満たしている必要があります。
- 1 つのリダクションでリストできる
- 定数として宣言できない
- 並列構造ではプライベートとして宣言できない
ループ・スケジューリング
負荷バランス (スレッド間における作業の等分割) は、並列アプリケーションのパフォーマンスにおいて重要な要素の 1 つです。負荷バランスが良いと、稼働率が上がり、プロセッサーはほとんどの場合ビジーとなります。しかし、負荷バランスが悪いと、一部のスレッドは他よりも著しく速く完了し、プロセッサーのリソースがアイドル状態のまま完了を待機するため、パフォーマンスが無駄になります。
ループ構造内の負荷の不均衡は、ループの反復における実行時間の変化が原因で発生します。通常、ループの反復における実行時間の変化は、ソースコードを検証することによって容易に確認することができます。ほとんどの場合、ループの反復は一定の時間を消費します。そうでない場合、消費時間が類似している反復のセットを見つけられることがあります。
例えば、すべての偶数反復とすべての奇数反復の消費時間が同程度の場合があります。同様に、ループの前半と後半の消費時間が同程度の場合もあります。逆に、一定の実行時間をもつ反復を見つけられないこともあります。どのような場合でも、このループ・スケジューリングの補足情報を OpenMP* に渡します。これは、最適な負荷バランスをとるようにループの反復をスレッド (そしてプロセッサー) に振り分ける際に役立ちます。
デフォルトでは、OpenMP* はすべての反復にほぼ同じ時間がかかると仮定します。この仮定に基づき OpenMP* は、フォルス・シェアリングによるメモリー競合の可能性を最小限に抑える方法で、ループの反復をスレッド間で等分します。
一般的にループはシーケンシャルにメモリーにアクセスするため、ループを大きな固まりに (2 つのスレッドを使用する場合では、前半と後半というように) 分割すると、メモリーの重複 (オーバーラッピング) の可能性を最小限に抑えることができます。これは、メモリーアクセスの問題に対しては最良の解決策であるかもしれませんが、負荷バランスに対してはそうではないかもしれません。また逆に、負荷バランスに対して最良の解決策が、メモリーのパフォーマンスに対してもそうであるとは限りません。パフォーマンスを測定し、最良の方法を探して、メモリーの使用と負荷バランスの両方に最適な方法を見つける必要があります。
ループ・スケジューリングの補足情報は、parallel 構造の次の構文で OpenMP* に渡されます。
#pragma omp parallel for schedule(kind [, chunk size])
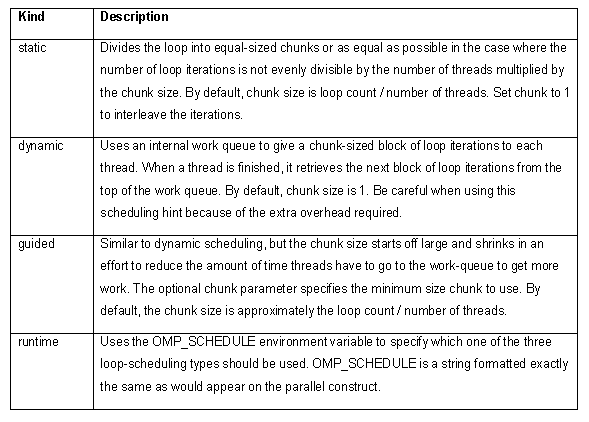
次の表のように、4 つの異なるループ・スケジューリングのタイプ (kind) を OpenMP* に渡すことができます。オプションのパラメーター (chunk) は、ループ不変の正の整数でなければなりません。
例
例: 次のループの並列化
for (i=0; i < NumElements; i++)
{
array[i] = StartVal;
StartVal++;
}
解決方法: データの依存関係に注意を払う
ループにはデータ依存が含まれているため、コードを変更せずには並列化できません。次の新しいループでは、同じように配列に格納しますが、データ依存がありません。また、SIMD 命令を使用して記述することもできます。
#pragma omp parallel for
for (i=0; i < NumElements; i++)
{
array[i] = StartVal + i;
}
変数 StartVal の値は増分されないため、これらのコードは全く同じではありません。このため、並列ループが終了すると、変数の値はシリアルバージョンのそれとは異なります。ループの後で StartVal の値が必要な場合は、次のように文を追加する必要があります。
// シリアル版と同じ結果となる
#pragma omp parallel for
for (i=0; i < NumElements; i++)
{
array[i] = StartVal + i;
}
StartVal += NumElements;
まとめ
OpenMP* は、プログラマーがスレッド化の詳細を気にせずに、より重要な課題に取り組めるように設計されています。OpenMP* プラグマを使用し、単純な文を 1 つ追加するだけで、ほとんどのループをスレッド化することができます。これこそが OpenMP* の強力で優れた利点です。このホワイトペーパーでは、OpenMP* への取り掛かりとして、その基本概念と初歩的な点について説明しました。次の 2 つのホワイトペーパーでは、ここで説明した内容に基づき、OpenMP* を使ってより複雑なループと一般的な構造のスレッド化について説明します。
参考資料 (英語)
-
OpenMP* 仕様: http://www.openmp.org
関連リンク (英語)
- OpenMP* を使用したその他のワークシェアリング (http://software.intel.com/en-us/articles/more-work-sharing-with-openmp)
- 高度な OpenMP* プログラミング (http://software.intel.com/en-us/articles/advanced-openmp-programming)
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
編集部追加
本記事では、OpenMP を用いてマルチコア・プロセッサに対応するマルチスレッド・プログラムを記述する方法について紹介しています。これで、あらゆるループを並列化すれば終わりでしょうか? ― 答えはノーです。並列化を考える開発者の真の目的は、プログラムを、もっと速く動作させ、処理時間を短縮することです。それも、その本来の機能を損なうことなく。少ない作業量で実現でき、保守性が優れていれば、なお良いでしょう。
インテルは、並列化を考える開発者のために、優れたパフォーマンス・アナライザーであるインテル® VTune Amplifier XE、そしてスレッド/メモリーエラーの検出ツールであるインテル® Inspector XE を提供しています。これらのツールは、OpenMP などマルチスレッドによる並列化を活用する上で大きな助けになるでしょう。各製品評価版のダウンロード、お問い合わせはエクセルソフト株式会社まで。
なお OpenMP 3.0 規格には日本語訳が存在します。OpenMP* 仕様ページ ( http://openmp.org/wp/openmp-specifications/ ) より [Transrations] Version 3.0, Japanese のリンクからご覧ください。
