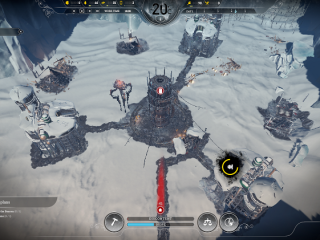
 イメージ
イメージ インテル® グラフィックス・パフォーマンス・アナライザーが『Frostpunk*』の雪のシミュレーションを支援
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Graphics Performance Analyzers Assist Snow Simulation in Frostpunk*」( の日本語参考訳です。ポー...
 イメージ
イメージ 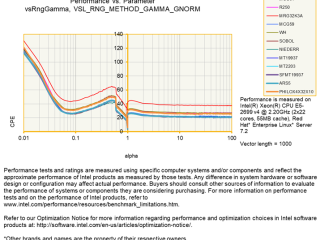 インテル® oneMKL
インテル® oneMKL  インテル® GPA
インテル® GPA  ゲーム
ゲーム  マシンラーニング
マシンラーニング 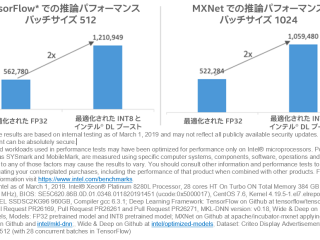 マシンラーニング
マシンラーニング 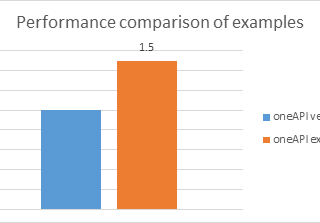 インテル® oneAPI
インテル® oneAPI  その他
その他  インテル® VTune™ プロファイラー
インテル® VTune™ プロファイラー  インテル® Parallel Studio XE
インテル® Parallel Studio XE  その他
その他  インテル® VTune™ プロファイラー
インテル® VTune™ プロファイラー 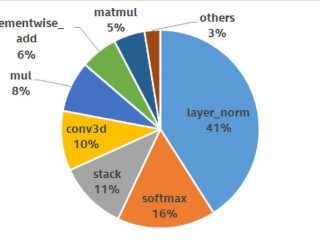 インテル® oneMKL
インテル® oneMKL 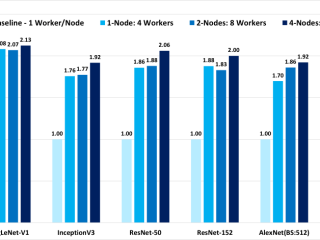 マシンラーニング
マシンラーニング 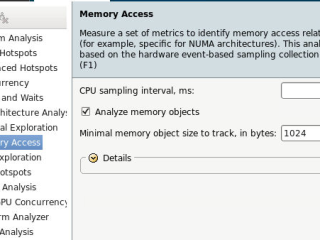 インテル® VTune™ プロファイラー
インテル® VTune™ プロファイラー 