


この記事は、インテルの The Parallel Universe Magazine 28 号に収録されている、新機能の Parallel STL を利用してパフォーマンスを向上する方法を紹介した章を抜粋翻訳したものです。
コンピューティング・システムは、シングルスレッドと SISD アーキテクチャーから最新のマルチコア/ メニーコアと SIMD アーキテクチャーへと急速に発展し、さまざまな分野およびフォームファクターで利用されています。C++ は、これらの最新のシステムで広く利用されているパフォーマンス指向の汎用言語です。しかし、最近まで、これらの最新のシステムをフルに活用する標準化された手段は提供されていませんでした。最新バージョンの C++ でも、並列処理を引き出す機能は制限されています。これまで、各ベンダーは、並列処理をサポートするさまざまな仕様、手法、ソフトウェアを開発してきました1 (図 1)。C++ 標準規格の次のバージョン (C++17) では、スレッド化やベクトル化のようなハードウェア機能を活用できるように、既存のシーケンシャル C++ コードを並列コードに変換する Parallel STL が追加される予定です。
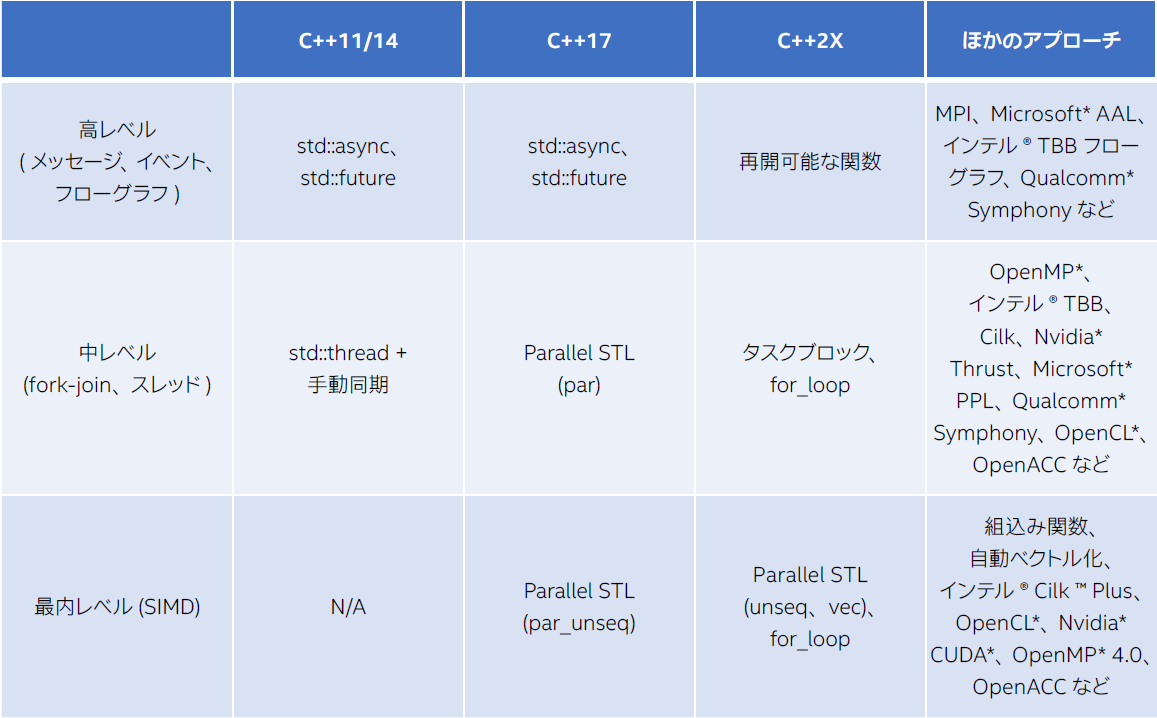
図 1. C++ における並列処理のサポート
Parallel STL
Parallel STL は、実行ポリシー引数で C++ 標準テンプレート・ライブラリーを拡張します。実行ポリシーは、STL アルゴリズムの関数多重定義を一義化するため固有の型として使用される C++ クラスです。便宜上、C++ ライブラリーはポリシー引数として使用できる各クラスのオブジェクトも定義します。ポリシーは、従来のアルゴリズム (transform、for_each、copy_if など) や新しいアルゴリズム (reduce、transform_reduce、スキャンのバリエーション [prefix sum] など) とともに使用することができます。並列実行ポリシーのサポートは、並列処理の C++ 拡張技術仕様 (Parallelism TS) として数年にわたり開発されてきましたが、C++17 標準規格ドラフトに含まれました (ドキュメント n464022)。ベクトル化ポリシーのサポートは、Parallelism TS の 2 つ目のバージョンで提案されています (ドキュメント p007533 および p007644)。全体的に、これらのドキュメントは 5 つの異なる実行ポリシーを説明しています (図 2)。
sequenced_policy (seq)クラスはアルゴリズムの実行が並列化されないことを示します。2parallel_policy (par)クラスはアルゴリズムの実行が並列化されることを示します。2 実行中に呼び出されるすべてのユーザー指定関数にデータ競合が含まれていてはなりません。parallel_unsequenced_policy (par_unseq)クラスは実行が並列化およびベクトル化されることを示します。2unsequenced_policy (unseq)クラスは実行ポリシーの Parallelism TS v24 における提案で、アルゴリズムの実行はベクトル化されるが並列化されないことを示します。提供されるすべての関数が SIMD セーフである必要があります。vector_policy (vec)クラスは実行ポリシー型の提案4 で、要素間の前方依存性を保つ方法でベクトル 化されることを示します。
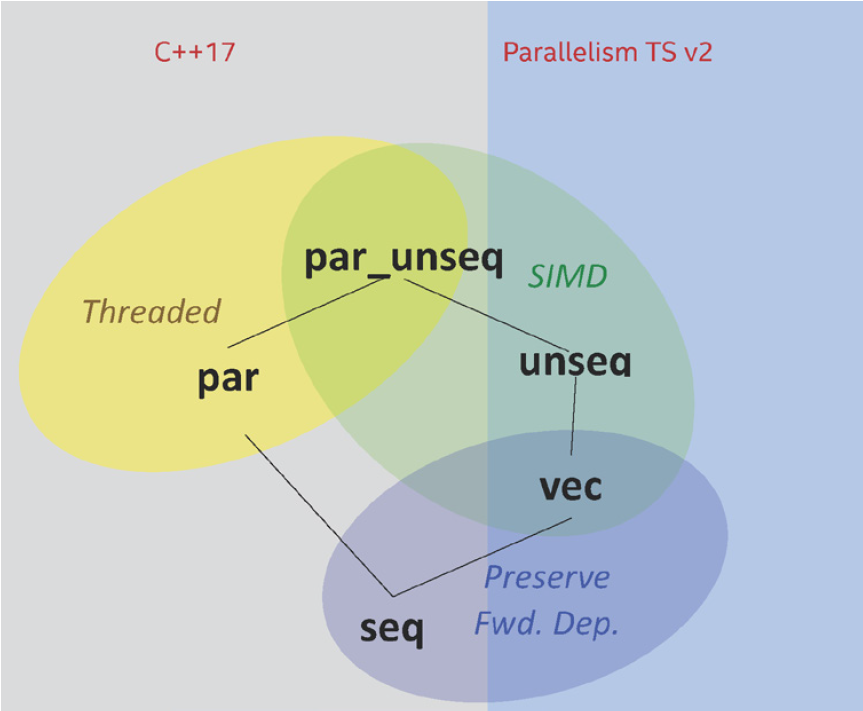
図 2. C++ 標準テンプレート・ライブラリーの実行ポリシー
図 2 は、これらの実行ポリシー間の関係を示しています。より上位の実行ポリシーは多くのことを行うことができますが、ユーザーコードに追加する要件も多くなります。Parallel STL の実装は、図の下に示す限定的な実行ポリシーの代わりに使用することができます。
単純な等価の STL と Parallel STL アルゴリズムは次のように記述することができます。
#include <execution>
#include <algorithm>
void increment_seq( float *in, float *out, int N ) {
using namespace std;
transform( in, in + N, out, []( float f ) {
return f+1;
});
}
void increment_unseq( float *in, float *out, int N ) {
using namespace std;
using namespace std::execution;
transform( unseq, in, in + N, out, []( float f ) {
return f+1;
});
}
void increment_par( float *in, float *out, int N ) {
using namespace std;
using namespace std::execution;
transform( par, in, in + N, out, []( float f ) {
return f+1;
});
}
ここで、
std::transform( in, in + N, out, foo );
は次のループと同じくらい単純です。
for (x = in; x < in+N; ++x) *(out+(x-in)) = foo(x);
また、
std::transform( unseq, in, in + N, out, foo );
は次のループと同じくらい単純です (今回の実装は最内レベルで #pragma omp simd を使用していますが、異なるアプローチを使用して unseq ポリシーを実装する Parallel STL に置き換えることもできます)。
