
この記事は、The Parallel Universe Magazine Issue 37 に掲載されている「Measuring the Impact of NUMA Migrations on Performance」(https://software.intel.com/en-us/download/parallel-universe-magazine-issue-37-july-2019) の日本語参考訳です。
この記事の PDF 版はこちらからご利用になれます。

最近のメモリーシステムは、コアと DRAM 全体がソケット間で分割される NUMA (Non-Uniform Memory Access) アーキテクチャーを採用しています。各コアは単一のメモリー空間としてメモリー全体にアクセスできます。しかし、ローカルソケット上のメモリーのほうが、リモートソケット上のメモリーよりも高速にアクセスできます。そのため、不均等メモリーアクセス (NUMA、Non-Uniform Memory Access) と呼ばれます。このようにアクセス・レイテンシーが異なるため、ローカル・ソケット・メモリーへのアクセスを常に優先すべきです。
このため、Linux* カーネルは、メモリーページをデータがアクセスされるソケットに移動する NUMA マイグレーションを行います。Linux* は、特定のソケットからページへのメモリーアクセス数やアクセスのレイテンシーなど、ページ・マイグレーションの決定に必要な情報を保持しています。Linux* の NUMA マイグレーションは、numactl などのユーティリティーを使用して OS レベルの NUMA 割り当てポリシーが指定されていない限り、デフォルトで有効です。
NUMA ページ・マイグレーションは、単一のマシン上で独自のメモリー割り当てを持つ複数のアプリケーションを実行する場合に非常に役立ちます。システムが共有されるこのようなシナリオでは、特定のアプリケーションに関連するメモリーページをそのアプリケーションが割り当てられているコアに移動することは合理的です。
この記事では、単一のアプリケーションがマシン全体を使用する場合 (ハイパフォーマンス・コンピューティングでは一般的なシナリオです)、NUMA マイグレーションはパフォーマンスの低下につながることを示します。また、多くの場合、numactl などの OS レベルのユーティリティーよりも、異なるデータ構造の割り当てや割り当てポリシーの設計を細かく制御できるアプリケーションレベルの NUMA 割り当てポリシーの使用が推奨されます。
この記事では、次の 2 つのアプリケーションレベルの NUMA 割り当てポリシーについて説明します (図 1)。
- NUMA インターリーブ: メモリーページは、NUMA ソケット間でラウンドロビン形式で均等に分割されます (numactl -interleave all コマンドに似ています)。
- NUMA ブロック: 割り当てメモリーの均等なチャンクが NUMA ソケット間で分割されます。

図 1. NUMA 割り当てポリシー (色分けは 2 つのプロセッサーを示す)
インテル® Xeon® Gold プロセッサー上での評価
(NUMA インターリーブと NUMA ブロックの両方のポリシーを使用して) サイズ m のメモリーを割り当て、t スレッドを使用して各スレッドが連続する書き込みブロックをシーケンシャルに取得して一度だけ書き込む単純なマイクロベンチマークを実行して、NUMA マイグレーションの効果を評価します。
図 2 と図 3 にメモリー割り当てポリシーの疑似コードと単純なマイクロベンチマーク計算の疑似コードをそれぞれ示します。評価には、4 ソケットのインテル® Xeon® Gold 5120 プロセッサー (56 コア、2.20GHz、187GB DDR4 DRAM) で構成されたシステムを使用しました。評価中、インテル® ハイパースレッディング・テクノロジーは無効に設定されていました。

図 2. NUMA インターリーブと NUMA ブロックメモリー割り当てポリシーの疑似コード

図 3. 評価に使用した単純なマイクロベンチマーク計算の疑似コード
異なる NUMA 割り当てポリシーに対する NUMA マイグレーションの効果
図 4 は、t = 56 スレッドとインターリーブ割り当てを使用して、異なるメモリー割り当てサイズ (m) でマイクロベンチマークを実行した時間です。ワークロードが倍になると、実行時間も倍になります。これは想定どおりです。しかし、実行中のページ・マイグレーションの数も大幅に増加しています。NUMA ブロック割り当てでも同様のパターンが見られます (図 5)。しかし、ブロック割り当てでは、40GB 以下のワークロード・サイズではページ・マイグレーションが発生しないため、インターリーブ割り当てよりも優れたパフォーマンスを達成しています。メモリーページは、計算中にローカルに割り当てられ、アクセスされます。
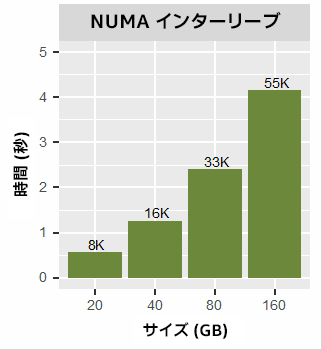
図 4. 56 スレッドと NUMA インターリーブ割り当てを使用して異なるワークロード・サイズでマイクロベンチマークを実行した結果。各バーの上の数値はメモリー・ページ・マイグレーションの数 (千単位) です。
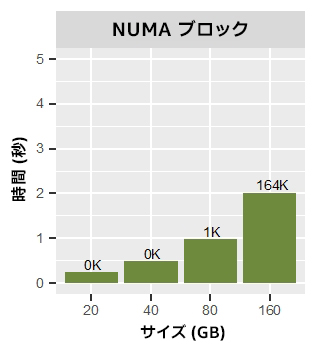
図 5. 56 スレッドと NUMA ブロック割り当てを使用して異なるワークロード・サイズでマイクロベンチマークを実行した結果。
各バーの上の数値はメモリー・ページ・マイグレーションの数 (千単位) です。
単一ソケット上での NUMA マイグレーションの効果
図 6 は、単一ソケット上で 160GB のワークロードを異なるスレッド数で実行した場合の合計実行時間、およびユーザーコードとカーネルコードで費やされた時間です。メモリー全体がソケット間で均等に分割されるため、各ソケットには約 47GB のメモリーがあります (187GB を 4 ソケットで分割)。ここでは、4 ソケットすべてにわたって 160GB を割り当てました。どちらの割り当てポリシーでも、マイクロベンチマークはスレッド数に応じてスケーリングしています。スレッド数が増加すると実行時間は減少し、ページ・マイグレーションの数も減少します。これは、アプリケーションの実行時間が長くなるほど、OS カーネルによるページ・マイグレーションが増えるためです。
各バーの赤色の部分は、カーネルコードでページ・マイグレーションに費やされた時間です。NUMA マイグレーションが無効な場合、これはほぼゼロになります。NUMA マイグレーションを無効にした場合、インターリーブでは 2.4 倍、ブロックでは 1.6 倍の相乗平均スピードアップが得られます。このことから、NUMA マイグレーションがパフォーマンスに大きく影響することが分かります。
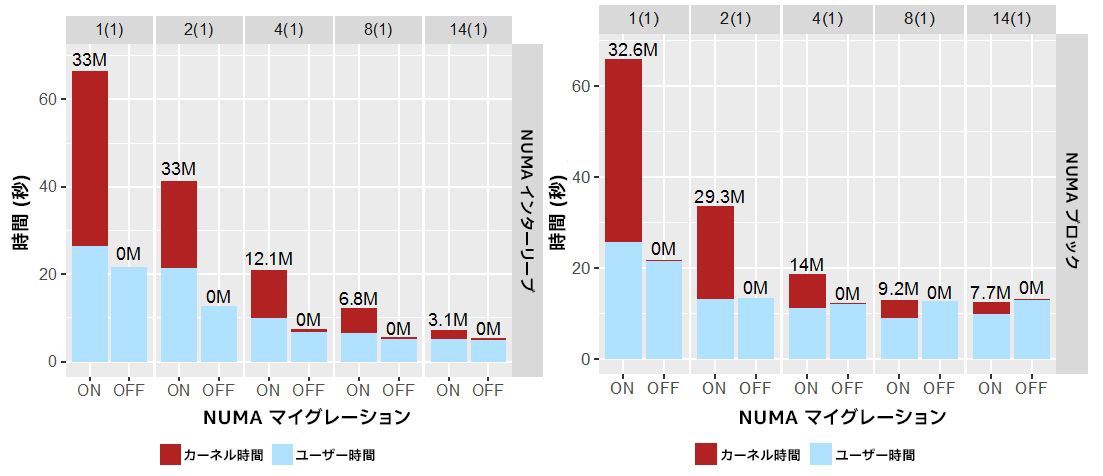
図 6. 単一ソケット上で固定ワークロード・サイズ (160GB) と異なるスレッド数を使用してマイクロベンチマークを実行した結果。スレッド数は上部に示します。括弧内はソケット数です。各バーの上の数値はメモリー・ページ・マイグレーションの数
(百万単位) です。
複数のソケット間の NUMA マイグレーションの効果
単一ソケットと同様のパターン (図 6) が複数のソケットでも見られました (図 7)。各グラフは、異なるソケット数で NUMA マイグレーションを有効にした場合と無効にした場合の結果を示しています。ソケット上のすべてのコアが使用されています。NUMA マイグレーションが無効な場合は常に、カーネルで費やされる時間が減少することが分かります。もう 1 つ興味深い点は、NUMA マイグレーションが無効な場合、ユーザーコードで費やされる時間がわずかに増加していることです。これは、NUMA マイグレーションによりメモリー・アクセス・レイテンシーが減少することを示しています。ただし、NUMA マイグレーションのオーバーヘッドがメリットを上回り、全体のパフォーマンスを低下させる可能性があります。
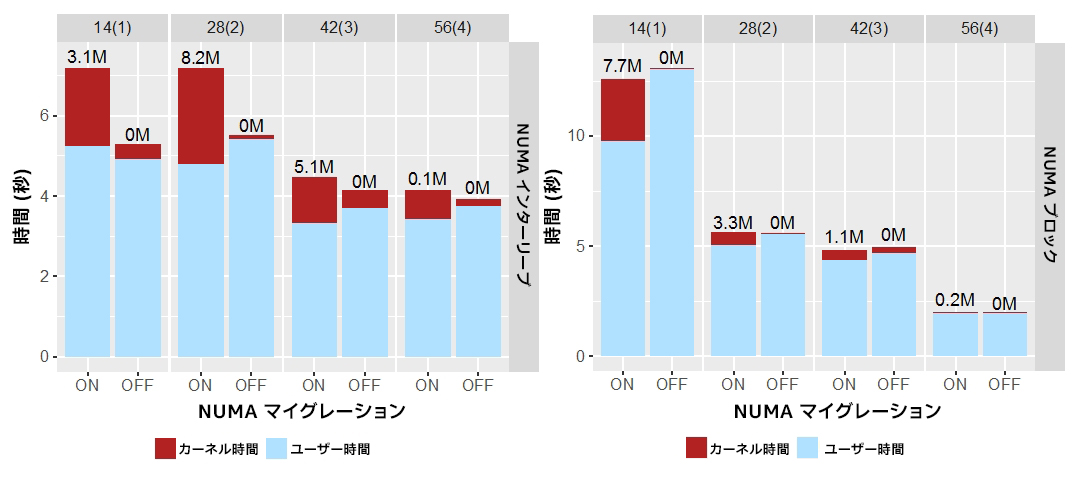
図 7. 異なる数のソケット上で固定ワークロード・サイズ (160GB) と異なるスレッド数を使用してマイクロベンチマークを実行した結果。スレッド数は上部に示します。括弧内はソケット数です。各バーの上の数値はメモリー・ページ・マイグレーションの数 (百万単位) です。
パフォーマンスの最大化
前述の結果から、NUMA マイグレーションなどの OS レベルの機能は、大きなパフォーマンス・オーバーヘッドが発生する可能性があるため、特にマシン全体で単一のアプリケーションを実行する場合 (ハイパフォーマンス・コンピューティングでは一般的なシナリオです)、慎重に使用する必要があります。
アプリケーションの実行時間に対する NUMA マイグレーションの影響は、次のようなさまざまな要因によって異なります。
- 使用される NUMA 割り当てポリシーの種類
- プロセッサー上で使用されるソケット数
NUMA ページ・マイグレーションによって生じるパフォーマンス・ノイズを回避するには、図 8 に示すように、該当する OS レベルの機能を無効にします (NUMA マイグレーションはデフォルトで有効です)。

図 8. OS レベルの機能の無効化
参考資料
- Linux* numactl ユーティリティー (英語)
- David Ott, “Optimizing Applications for NUMA,” Intel Corporation, 2011.
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
