
この記事は、Intel AI Blog で公開されている「Solving the Problem of Squirrels Stealing from the Bird feeder: Prototyping Image Classification with the Deep Learning Workbench in Intel® DevCloud for the Edge」の日本語参考訳です。

写真の出典: Unsplash (英語) で公開されている Anthony Intraversato (英語) 氏の作品
はじめに
早朝、太陽が輝いているのに、鳥の鳴き声がしません。新しい鳥の餌箱には種が入っていましたが、今は空っぽで、リスが盗んだ種を持って幸せそうに近くの木を駆け上がっています。新しい餌箱でさえもこの問題を防ぐことができませんでした。この記事では、鳥の餌箱を近代化し、ディープラーニングを利用して鳥の餌をリスから守る方法を考察します。
ここでは、ディープラーニング・ワークベンチ (DL ワークベンチ) を利用して、画像分類ソリューションを設計します。このツールは、さまざまなインテル® アーキテクチャー構成で、ディープラーニング・モデルのパフォーマンスを評価、微調整、比較、視覚化するのに役立ちます。評価には、OpenVINO™ ツールキットの Open Model Zoo から事前トレーニング済みモデルをインポートするか、カスタムのトレーニング済みモデルをアップロードして利用できます。
この記事では、リスと鳥を例に、DL ワークベンチを使用した画像分類の基本機能を検証します。DL ワークベンチへのアクセス方法、データセットのサンプルをトレーニング済みモデルで評価する方法、そして独自の Keras モデルをアップロードする方法を紹介します。インテル® DevCloud for Edge を使用することで、マシンにアプリケーションをインストールしたり、パッケージをダウンロードしたり、開発環境を構成することなく、すぐに検証を開始できます。
データセットの説明
リス検出装置を設計する最初のステップは、リスや鳥の画像を含むデータセットを集めることです。幸い、一般に公開されているデータセットを利用できるので、自分で画像を撮影してラベル付けする必要はありません。例えば、今回は Caltech_Birds_2011 (https://www.kaggle.com/tarunkr/caltech-birds-2011-dataset) から鳥の画像を、Animals-10 (https://www.kaggle.com/alessiocorrado99/animals10) からリスの画像を取得しました。
Caltech_Birds_2011 データセットには、200 種類の鳥の画像が含まれていますが、使用する画像を鳥の餌箱を訪れる可能性のある種に絞ることができます。Animals-10 データセットには、リスのクラスが 1 つ含まれていますが、画像にはさまざまな種類のリスが写っています。
このデータセットを使って分類モデルをトレーニングする前に、画像のサイズと寸法を標準化する必要があります。この例では、画像のサイズを 64×64 ピクセルに標準化しました。小さな画像サイズを使用することで、モデルのトレーニング時間が短縮され利用しやすくなり、再度トレーニングする際にも便利です。データセットの抽出と標準化については、GitHub* (英語) を参照してください。リポジトリーには、トレーニング・セットと検証セットを含む pickle ファイルも含まれています。
作成したデータセットでは、ラベルファイルに Image Net を使用しています。これは、validation image フォルダー内の annotation.txt ファイルにあります。このファイルは、以下の形式のカンマ区切りの値 (csv) になっています。
<image_name> <class_label>
Image Net アノテーションは、DL ワークベンチでサポートされているラベル形式の 1 つです。このほかにも、Pascal Visual Object Classes (Pascal VOC)、Common Objects in Context (COCO)、Common Semantic Segmentation、Common Super-Resolution アノテーション形式を使用できます。サポートされている形式の詳細は、DL ワークロードのドキュメント (https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Dataset_Types.html) を参照してください。
インテル® DevCloud から DL ワークベンチを利用する
DL ワークベンチを使用する前に、インテル® デベロッパー・クラウド (英語) でインテル® DevCloud for Edge のアカウントを作成する必要があります。
アカウント作成後、[Advanced] メニューから [Deep Learning Workbench] を選択すると、DL ワークベンチにアクセスできます。

図 1: インテル® DevCloud ホームページからディープラーニング・ワークベンチにアクセスする方法を示すスクリーンショット
DL ワークベンチの新しいインスタンスの作成に使用する Jupyter* Notebook がロードされます。Jupyter* Notebook は、Python* コードを実行するためのブロックを含むウェブ・アプリケーションで、ディープラーニング・ワークベンチのランチャーを実行するコードブロックが含まれています。

図 2: ディープラーニング・ワークベンチのランチャーを実行するコードブロックの内容
この Python* コードブロックは、タブの上部にある [Play] ボタンをクリックするか、コードブロックを選択した状態で Shift + Enter キーを押すことで実行できます。コードブロックの下に [Start Application] ボタンが表示されます。このボタンをクリックすると、DL ワークベンチのセッションが作成されます。これには 1 分程度かかることがあります。セッションの読み込みが完了すると、ボタンの下にリンクが表示されます。このリンクを選択すると、DL ワークベンチ用の新しいウェブ・ブラウザー・タブが作成されます。
新しい構成の作成
DL ワークベンチのランディング・ページには、ユーザーのプロファイルに保存されているモデル構成がリストアップされています。保存されているモデルがない場合は、左上の [Create] ボタンをクリックして新しい構成を作成します。構成の詳細を選択する新しいページが表示されます。モデル、ターゲット環境、データセットを選択する必要があります。
まず、インテルの Open Model Zoo からモデルをインポートします。Image Net データセットでトレーニングされた画像分類用のモデルが数多くあります。AlexNet は、画像分類用の畳み込みニューラル・ネットワーク (CNN) モデルとしてよく知られています。このモデルを選択してインポートし、構成に使用できます。AlexNet は Caffe* モデルなので、OpenVINO™ の中間形式に変換する必要があります。[Import] ボタンをクリックすると、モデル変換の精度を選択するプロンプトが表示されます。デフォルトの精度は FP32 (32 ビット浮動小数点) です。
モデルをインポートした後は、ハードウェア環境を選択する必要があります。これは、ハードウェアをエミュレートする仮想マシンではありません。モデルは、実験を実行するため選択したハードウェアの物理的な部分に読み込まれます。
ここで、リス検出装置のデザインを決定する必要があります。どのようなコンピューティング・ハードウェアを使用するか、DL ワークベンチでさまざまなデザインのパフォーマンスを比較して、ニーズに合ったものを選択できます。
今回の例では、2 つの CPU 実装を検討します。1 つ目は、PC にカメラを取り付けることを想定して、インテル® Core™ プロセッサーでモデルを実行します。2 つ目は、モバイル・エッジ・デバイス用に、Intel Atom® プロセッサーで低消費電力のソリューションを検討します。
最初に、PC 実装から見ていきましょう。[Base Platform] ドロップダウン・メニューから [Intel Core] を選択します。利用可能なインテル® Core™ プロセッサー環境のリストが表示されます。最初の実験では、インテル® Core™ i7-8665UE プロセッサーを選択します。
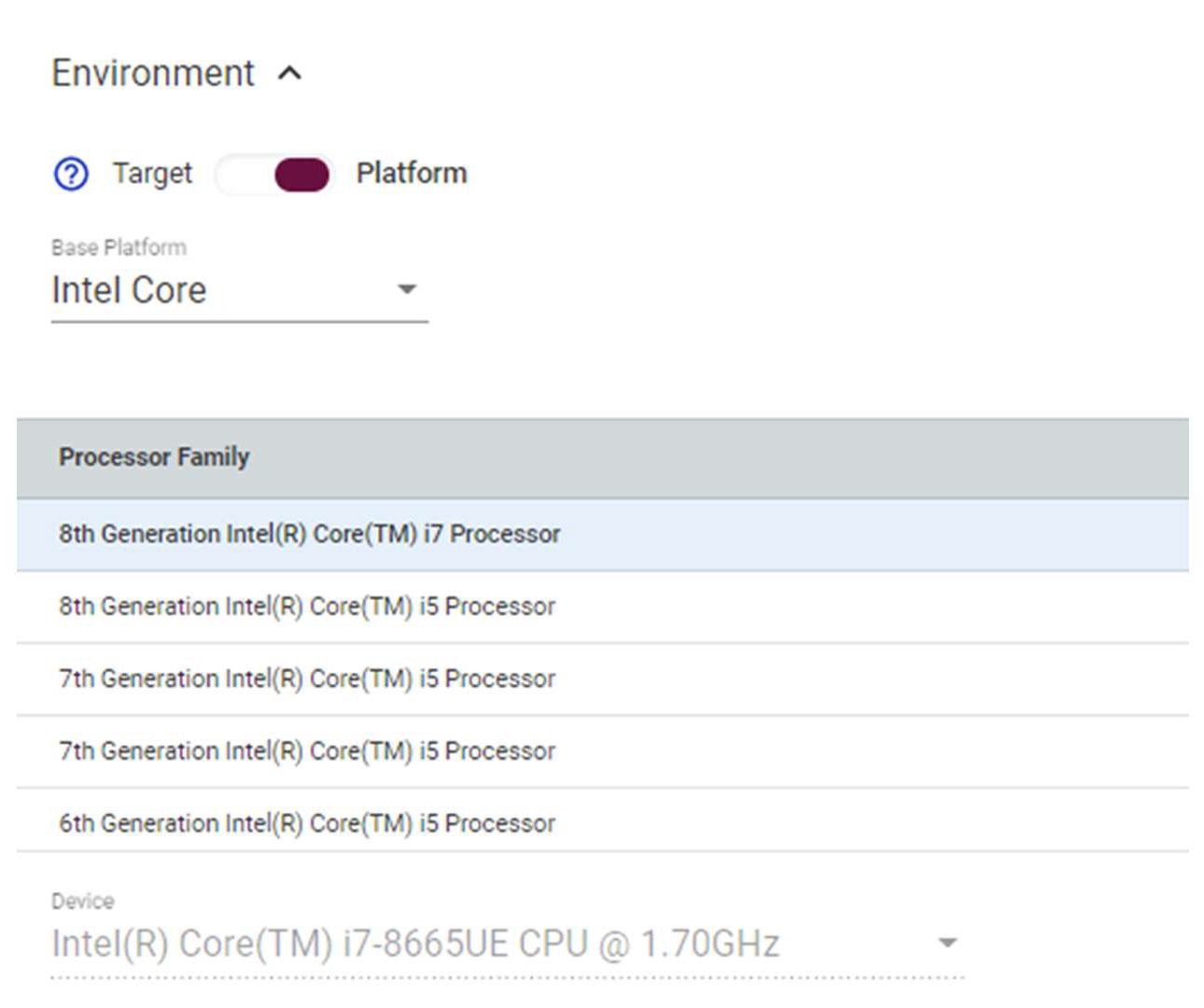
図 3: ハードウェア環境の選択方法を示すスクリーンショット
最後に、選択したモデルに対して実行するデータセットを選択する必要があります。データセットの選択には 2 つの方法があります。ガウスノイズで構成された画像のデータセットを生成して、「本物」のデータを提供しなくても、構成のパフォーマンス指標のベンチマークを取得できます。ただし、生成されるデータセットにはアノテーションがないため、精度のパーセンテージを得ることはできません。現在、DL ワークベンチのオンライン版では、実験を実行した後に精度を報告しませんが、モデルを単一のサンプルでテストすることは可能です。
今回の実験では、SquirrelVsBird データを用意しました。[Validation Dataset] セクションの [Import] ボタンをクリックして、データセットをインポートします。[Import Validation Dataset] ページで、[Choose File] ボタンをクリックすると、ファイル・ブラウザー・メニューが表示され、バリデーション画像を含む zip ファイルと、画像ラベルを含むアノテーション .txt ファイルを選択できます。DL ワークベンチにインポートする前に、テキストフィールドでデータセット名を調整できます。一度インポートしたデータセットは、今後も使用できるように保持されます。
モデル、環境プラットフォーム、データセットの選択が完了したので、ページ下部の [Create] ボタンをクリックして、構成の最初の実行を開始します。
結果の考察と視覚化
最初の実行では、1 枚の画像を含むバッチと単一のストリームでモデルに対する検証セットを実行します。[Analyze] タブのサマリーテーブルには、並列ストリームの数とバッチ内の画像の数が表示されます。[Perform] タブの [Explore Inference Configuration] メニューで異なるストリームやバッチの値を選択することで、追加の実験を行うことができます。
このダッシュボードをスクロールすると、DL ワークベンチはモデルのパフォーマンスを評価するのに役立ついくつかのメトリックを提供しています。ここで重要な測定値は、スループットとレイテンシーです。スループットとは、一定期間に完了したタスクの数のことです。レイテンシーとは、1 つのタスクを完了するのにかかる時間のことです。ここでは、画像が鳥なのか、リスなのかを推測するというタスクを想定しています。
スループットとレイテンシーを考慮することで、どのようなハードウェアを選択し、どのように最適化すべきかを決定できます。スループットを優先する場合は、処理するデータ量を最適化します。レイテンシーを重視する場合は、1 つの推論をどれだけ速く行えるかを最適化します。今回のリス検出プロジェクトでは、1 つのデータストリームを使用してリスを素早く識別し、鳥の餌の盗難を防ぐためのアクションを起こしたいので、レイテンシーを重視すべきです。
以降の図から、ネットワークのさまざまな層のパフォーマンスについての情報が得られます。これらは、ネットワークのどこで実行時間が費やされているかを示しています。この情報は、最適化がネットワークのさまざまな層にどのような影響を与えるかを判断するのに役立ちます。
同一モデルの構成の比較
インテル® Core™ プロセッサーの実験で得られたメトリックを確認したら、エッジ・ソリューションのパフォーマンスと比較します。そのためには、Intel Atom® プロセッサー・ベースのハードウェアを使った別の実験を行う必要があります。ページの上部にある [Create] ボタンをクリックして、新しい実験を開始します。これにより、モデルとデータセットがプリセットされた新しい構成が作成されます。次に、ハードウェア環境のドロップダウンから [Atom] を選択し、実験を実行するデバイスを選択します。ページ下部の [Create] ボタンをクリックすると、1 バッチ、1 ストリームの実験が実行されます。2 つの実験の実行速度を比較します。

図 4: SquirrelVsBird データセットでトレーニングされた AlexNet モデルを使用した
Intel Atom® プロセッサー (idc008u2g) とインテル® Core™ プロセッサー (idc016ai7) の実験の比較表
この表から、2 つの実験のスループットとレイテンシーが分かります。予想通り、インテル® Core™ プロセッサーが Intel Atom® プロセッサーを上回っています。[Projects] ヘッダーの隣にある [Compare] ボタンをクリックすると、実験間のより詳細な比較を行う新しいページが表示されます。2 つの構成を選択すると、それぞれのスループットとレイテンシーを横に並べた図が表示されます。また、[Kernel-Level Performance] タブでは、2 つの構成の異なる層の実行時間を確認できます。
アプリケーションで要求される精度によっては、Intel Atom® プロセッサー構成のレイテンシーを許容できる場合があります。レイテンシーを改善するには、最適化機能を検討することもできますが、モデルに注目すると、AlexNet は Image Net データセットでトレーニングされており、1000 クラスを推論することができます。今回は鳥とリスのみを検出するため、独自のモデルを作成して、このモデルを DL ワークベンチにインポートして、インテルのハードウェア構成で実行します。
カスタムモデルのインポート
DL ワークベンチは、さまざまな形式 (https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Select_Models.html) のモデルのインポートをサポートしています。このプロジェクトでは、カスタムの SquirrelVsBird データセットで畳み込みニューラル・ネットワーク (CNN) をトレーニングしました。モデルは、Tensorflow-Keras チュートリアル (英語) に従ってインテル® DevCloud で作成しました。Jupyter* Notebook とモデルファイルは GitHub* (英語) で公開されています。
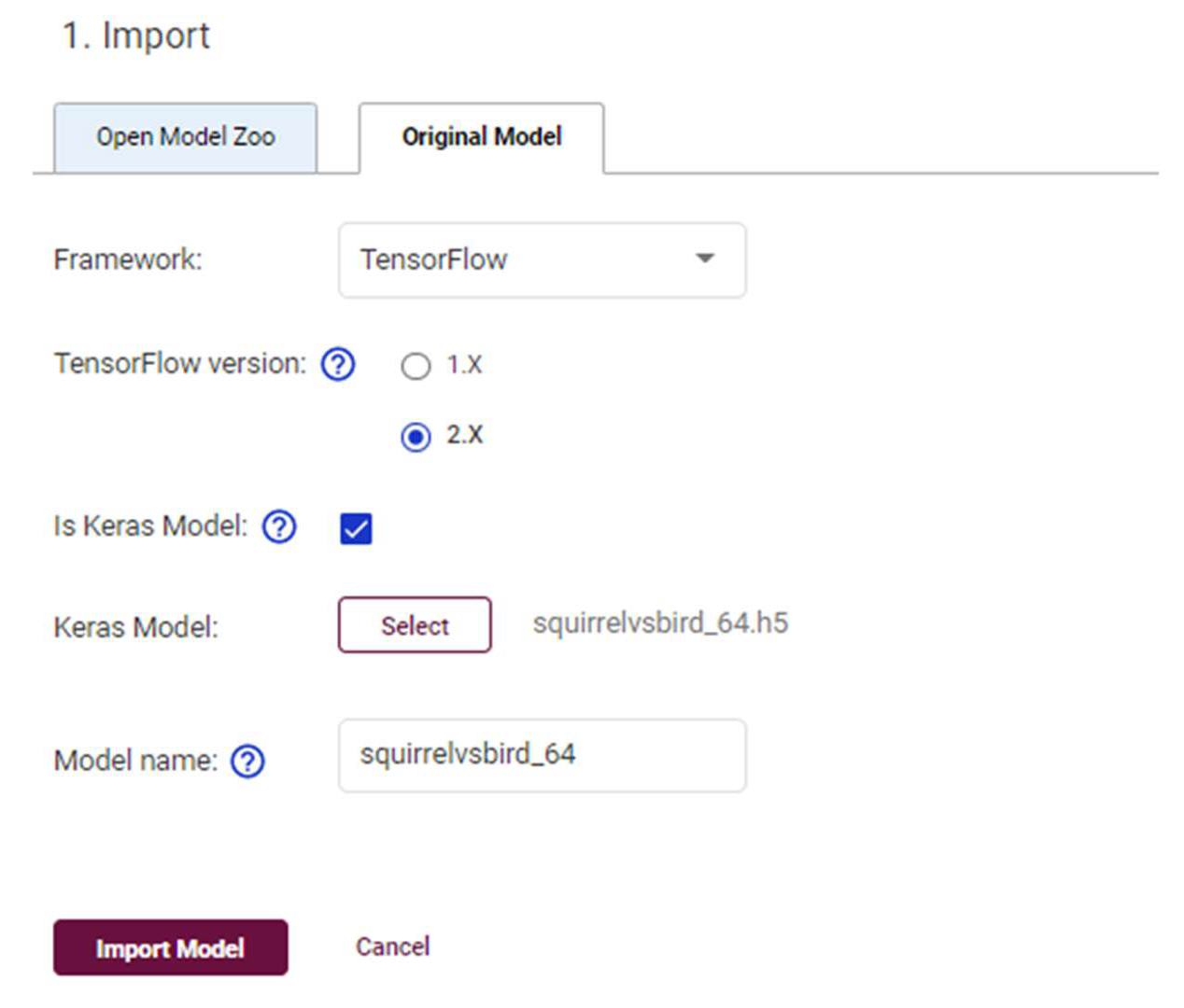
図 5: TensorFlow* Keras のオリジナルモデルをインポートするためのパラメーターのスクリーンショット
DL ワークベンチの [Create Configuration] ページから、[Import] ボタンをクリックして [Original Model] タブを選択すると、カスタムモデルをインポートできます。SquirrelVsBird モデルを読み込むには、[Framework] ドロップダウン・メニューから [TensorFlow] を選択します。[TensorFlow Version 2.x] を選択すると、[Is Keras Model] チェックボックスが表示されます。チェックボックスをクリックしてから、[選択] ボタンをクリックして、Keras モデルを含む H5 ファイルを選択できます。
モデルをインポートすると、OpenVINO™ の中間表現 (IR) 形式に自動的に変換されます。このための追加のパラメーターを設定する必要があります。このメニューでは、浮動小数点の精度を選択したり、色空間や入出力パラメーターを設定します。精度の調整は、モデルのパフォーマンスに影響します。浮動小数点の精度を低くすると、モデルの効率は向上しますが、精度が低下することに留意してください。現在の推奨値は FP16 です。サポートされているモデルでは、DL ワークベンチのパフォーマンス・チューニング・セクションで、これを INT8 に最適化できます。
色空間については、モデルは RGB (Red Green Blue) 画像を使用してトレーニングされています。誤った色空間を選択すると、DL ワークベンチによるモデルの評価に影響します。
IR 形式への変換時に入出力を設定することもできます。通常、DL ワークベンチがモデルファイルから抽出したデフォルト値を維持します。1 つ目の次元は、インポート時に認識されない場合があります。この場合、値はトレーニング中に使用されたものと一致させる必要があります。SquirrelVSBird モデルでは、64 x 64 ピクセルの RGB 画像を 1 枚使用しています。入力形状は、1×64×64×3 となります。パラメーターの設定に関する詳細は、ツールのヒントや DL ワークベンチのドキュメント (https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Select_Models.html#convert) を参照してください。
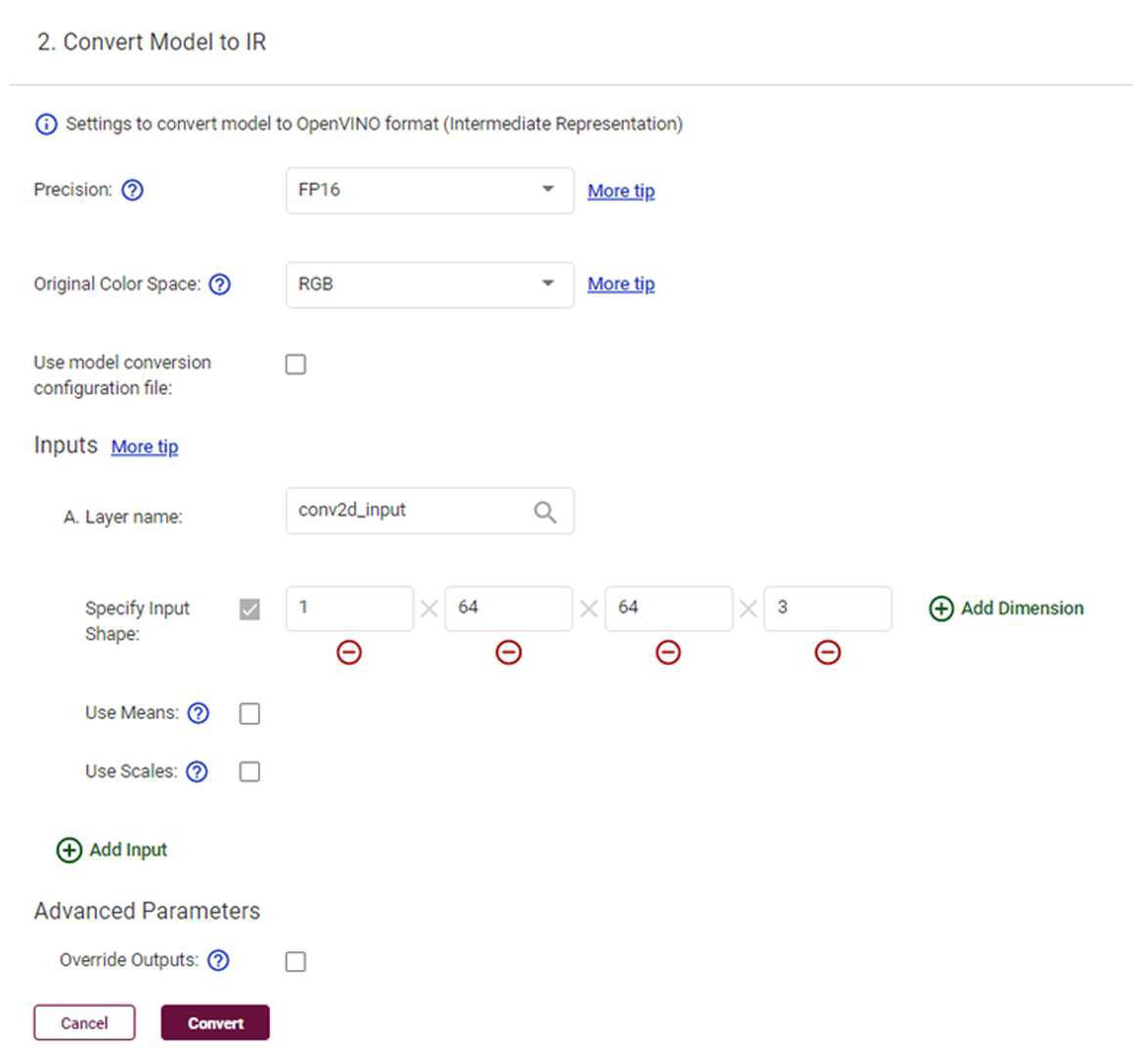
図 6: オリジナルモデルを OpenVINO™ の中間表現 (IR) に変換するためのパラメーターのスクリーンショット
モデルの変換が完了したら、インテルの Open Model Zoo から取得した AlexNet モデルと同じ実験を行うことができます。
カスタムモデルの評価
SquirrelVsBird のカスタムモデルをインポートしたら、前述の手順を繰り返して、以前使用したインテル® Core™ プロセッサーと Intel Atom® プロセッサー環境で実験を行います。カスタムモデルは、どちらの環境でも、トレーニング済みの AlexNet モデルを上回る結果となりました。AlexNet モデルは、カスタムモデルよりも大きく、より一般化されています。AlexNet の入力パラメーターは 227 x 277 の画像であるのに対し、カスタムモデルは 64 x 64 の画像です。同様に、AlexNet の出力パラメーターは 1000 個あるのに対し、SquirrelVsBird モデルの出力パラメーターは 2 個です。また、畳み込み層の数も、AlexNet の 5 層に対して、カスタムモデルは 3 層と少ないです。
カスタムモデルの 2 つの環境での実験を比較すると、インテル® Core™ プロセッサーが Intel Atom® プロセッサーを大幅に上回り、1 枚の画像の分類にかかる時間は 1 ミリ秒以下になりました。Intel Atom® プロセッサーでは、1 枚の画像に対する推論を 7 ミリ秒弱で実行しています。
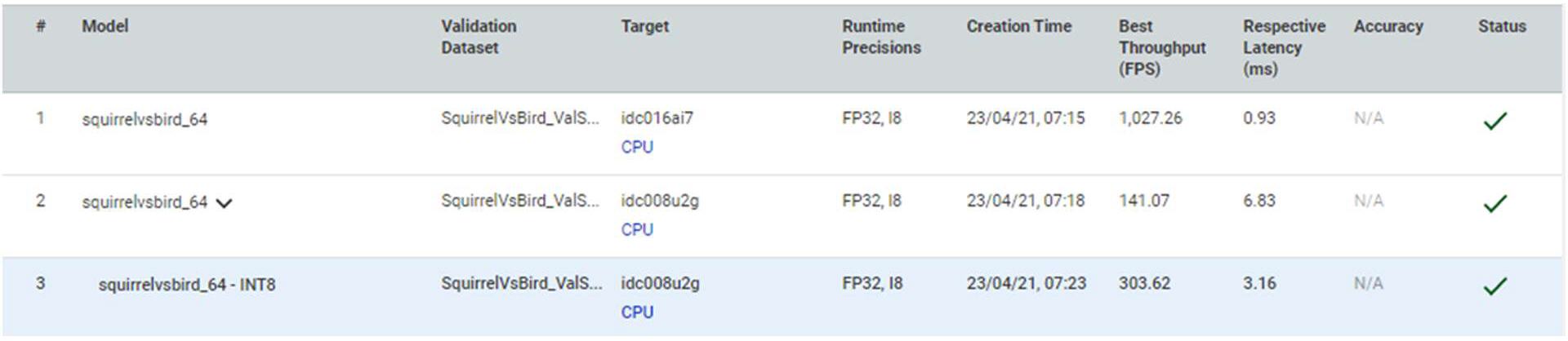
図 7: SquirrelVsBird データセットでオリジナルモデルを使用したインテル® Core™ プロセッサー (idc016ai7) と Intel Atom® プロセッサー (idc008u2g) の実験結果の比較表 – 表の 3 番目の実験では Intel Atom® プロセッサーで INT8 精度を使用
DL ワークベンチのモデル・ビジュアライザーでは、モデルのパフォーマンスに関する詳細な情報を得ることができます。[Projects] ページの [Performance Summary]、[Precision-Level Performance]、[Kernel-Level Performance] タブには、ネットワーク内の層ごとにモデルの実行メトリックが表示されます。[Kernel-Level Performance] メニューでは、モデル・ビジュアライザーにより、モデルのネットワークの色分けされたグラフが表示されます。[Coloring] ドロップダウン・メニューで [By Execution Time] を選択すると、サンプルに対して推論を実行する際に、モデルが最も時間を費やしている場所を示すためグラフィックを色分けできます。
Intel Atom® プロセッサーで動作する SquirrelVsBird モデルでは、第 2 畳み込み層が赤く表示されており、この層はネットワークのほかの層よりも完了までに時間がかかったことを示しています。このグラフィックは、モデルをチューニングする際に、最適化が各層の実行時間にどのような影響を与えるかを視覚化する貴重なツールです。層の実行に関する追加情報は、グラフィックの隣に表示されます。
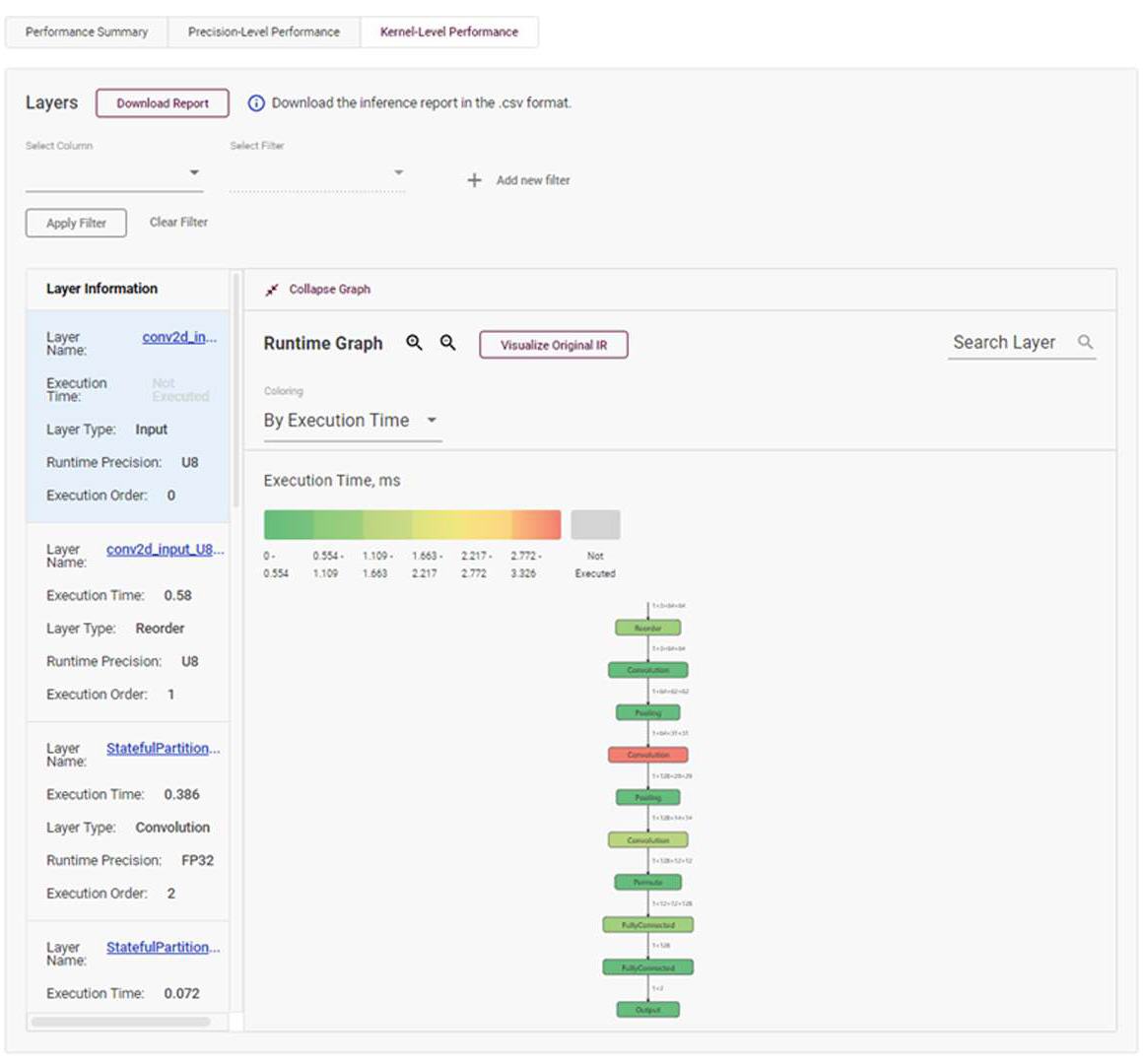
図 8: Intel Atom® プロセッサーで動作する SquirrelVsBird モデルのモデル・ビジュアライザーのスクリーンショット
Squirrel-vs-Bird 検出システムのエッジ・デバイス・ソリューションを検討するため、モデルをさらに最適化してレイテンシーを減らす方法を探ります。DL ワークベンチで提供されている方法の 1 つに、INT8 表現への変換があります。
INT8 表現とは、ネットワークの値の格納に使用されるデータ構造のことです。オリジナルモデルは、FP32 精度でインポートしました。つまり、ネットワーク内の値は 32 ビット構造の浮動小数点形式で保存されます。INT8 による最適化では、浮動小数点の値が整数に変換され、データサイズが 8 ビットに縮小されます。これにより、モデルの推論タスクの実行に必要なメモリーと計算リソースを軽減します。INT8 表現はパフォーマンスを向上させますが、モデルの精度に悪影響を与える可能性があります。DL ワークベンチの INT8 表現の実装については、こちら (https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Int_8_Quantization.html) を参照してください。
DL ワークベンチで INT8 を使用するため実験を変換するのは簡単です。以前使用した Intel Atom® プロセッサーの実験を選択して、[Perform] タブをクリックし、オリジナルモデルの Intel Atom® プロセッサー実装用に新しい実験を作成できます。[Optimize Performance] メニューが表示され、INT8オプションが表示されます。このオプションを選択して [Optimize] ボタンをクリックすると、INT8 設定で実験が実行されます。
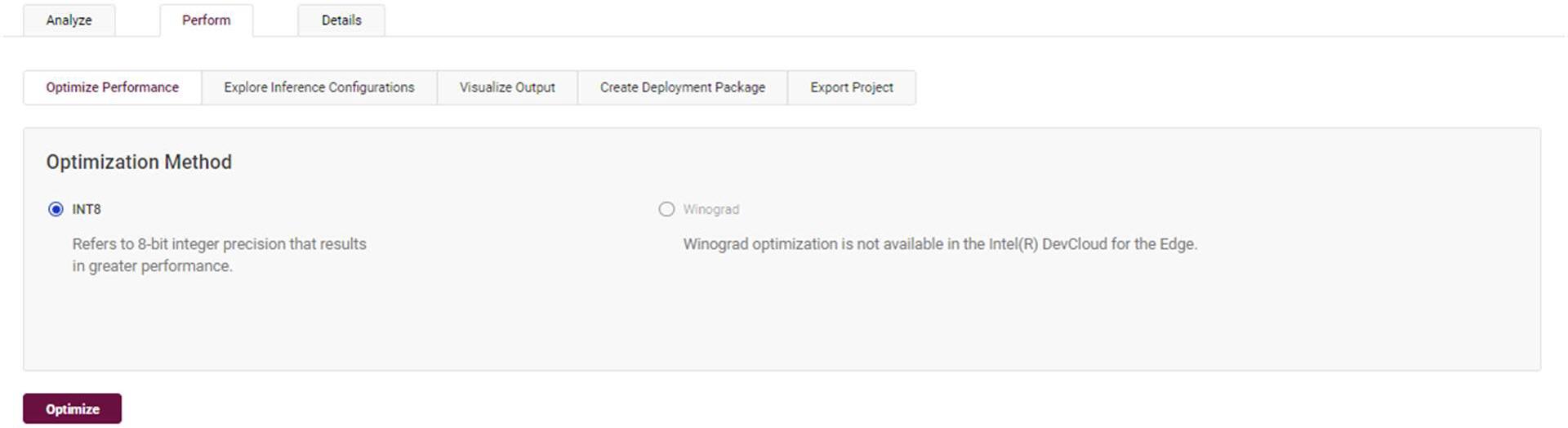
図 9: [Projects] ページの [Perform] タブにある [Optimize Performance] メニューのスクリーンショット
INT8 による最適化の結果を前回の Intel Atom® プロセッサーの実験と比較すると、精度を変更したことで、レイテンシーが半分になり、スループットが 2 倍になったことが分かります。これでもまだインテル® Core™ プロセッサーの実験のメトリックには達していません。しかし、この最適化は、特にエッジ実装でのパフォーマンス向上に有効であることが分かりました。
Squirrel-vs-Bird 問題では、軽量のカスタムモデルを使用することで、AlexNet 実装に比べて推論タスクのパフォーマンスが低下しました。ハードウェア設計に関して、Intel Atom® プロセッサーではパフォーマンスが低下しましたが、レイテンシーとスループットは問題解決に十分なものでした。この結果を踏まえて、最終的な実装に向けてその他の検討を行うことができます。コスト、デバイスが設置されるインフラストラクチャー、モビリティーの必要性などを考慮して、理想的なソリューションを設計できます。
設定のパックとエクスポート
いくつかの実験を行い、デバイスに最適なハードウェアを決定する準備ができました。ハードウェア構成を決定したら、ターゲットデバイスにインストールするための配置パッケージを作成します。INT8 による最適化で行ったように、[Projects] ページで実験構成を選択した状態で、[Perform] タブから [Create Deployment Package] メニューを選択します。このメニューでは、パッケージを作成するためのパラメーターを選択します。[Pack] ボタンをクリックすると、tar.gz ファイルが作成され、ダウンロードが初期化されます。
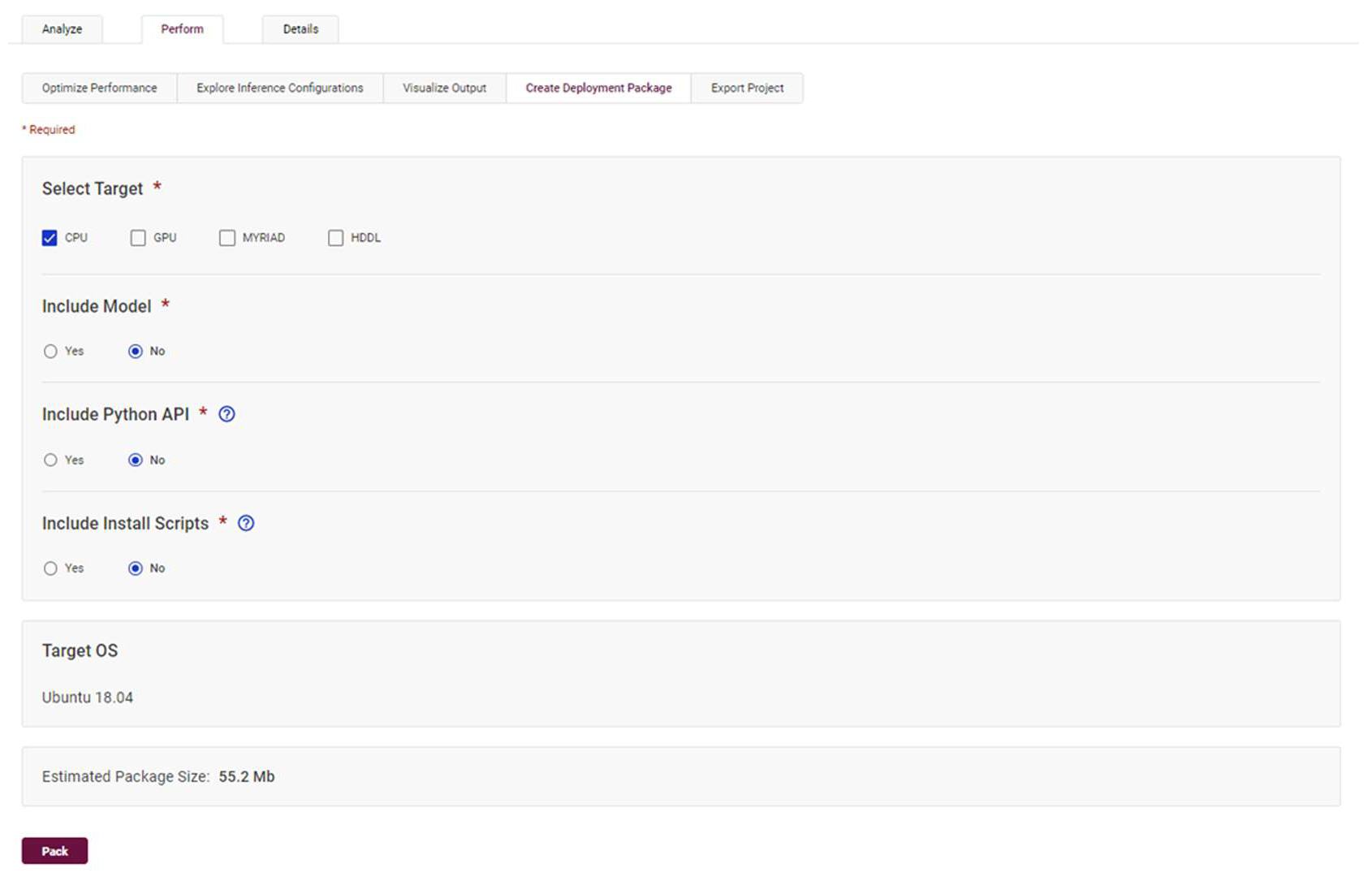
図 10: [Projects] ページの [Perform] タブにある [Create Deployment Package] メニューのスクリーンショット
まとめと DL ワークベンチのその他の機能
ここでは、DL ワークベンチを使用してリスと鳥の分類問題のハードウェア構成の設計と選択を評価しました。また、インテルの Open Model Zoo でトレーニングしたモデルとオリジナルモデルのインポート、ハードウェア実験の実行と比較、INT8 精度変換によるモデルの最適化、デプロイメント・パッケージのエクスポートなどを行いました。ここで説明したことは、このプラットフォームでできることのほんの一部に過ぎません。DL ワークベンチは、物体検出やスタイル変換などのほかのディープラーニング・アプリケーションや、さまざまな最適化手法、多様なハードウェア構成をサポートしています。
法務上の注意書き
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。
絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
実際の費用と結果は異なる場合があります。
© Intel Corporation.Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
