
この記事は、インテル® デベロッパー・ゾーンに掲載されている「AI Practitioners Guide for Beginners」(https://software.intel.com/en-us/articles/ai-practitioners-guide-for-beginners) の日本語参考訳です。
この記事の PDF 版はこちらからご利用になれます。
インテル® Xeon® プラットフォーム・ベースのインフラで TensorFlow* フレームワークの展開とサンプルのテストを行います。
スコープ
この実践イネーブルガイドでは、マシンラーニング (ML) を導入する上で知る必要があるビジネスおよびデータ戦略の概要を説明し、よく知られる人工知能 (AI) フレームワークの 1 つである TensorFlow* のインテル® Xeon® スケーラブル・プロセッサー上でのインストールと検証方法について説明します。このガイドでは、ベアメタル、コンテナー経由、またはクラウドで実行される典型的な環境にインストールする手順を詳しく説明します。
注: このガイドで示される例はパフォーマンスの最適化が行われておらず、学習のみを目的としています。
人工知能 (AI) の定義
人工知能の定義は絶えず変化していますが、その根底は AI とは人間の思考に関連する認知機能を模倣する (または上回る) マシンです。さまざまなアプローチを含む AI の世界では、知覚、計画/推論、および制御の 3 つの AI サブタスクを処理する能力に優れた、データ中心のマシンラーニングが主流となっています。最終的に、AI はこれまで以上にインテリジェントなマシンを供給するため、複数のアプローチの融合によって構築され、近い将来 AI 開発はディープラーニングを中心として、データセット、問題、および要件に応じてその他のアプローチが重要な役割を果たすようになります。
図 1 に示すように、マシンラーニングは AI のサブセットであり、時間経過につれてより多くのデータを受け入れてパフォーマンスが向上し続けるマシン・アルゴリズムとして定義できます。例えば、庭の植物に水やりをする自己学習型ロボットをプログラミングする場合、ロボットは途中で障害物 (石など) にぶつかると、それを回避して、以降はその障害物にあたらないように学習します。そのため、水撒きロボットのマシンラーニングは、時間が経過するとともにパフォーマンスが向上します。
マシンラーニングのサブセットであるディープラーニング (DL) は、多層ニューラル・ネットワークが膨大なデータから学習します。ディープラーニングは、近年注目度が高まり、採用が進んでいる AI 分野です。このガイドのフレームワークとサンプルは、ディープラーニングを基にしています。DL は、主にトレーニングと推論の 2 つで構成されます。トレーニングは、ラベル付けされたデータ/コンテンツを供給して、オブジェクト/テキストなどを識別するため多層ニューラル・ネットワーク (モデルと呼ばれる) を教育します。モデルのトレーニングが完了したら、ラベル付けされていないコンテンツを特定するため、トレーニング済みのモデルを使用して推論を開始します。
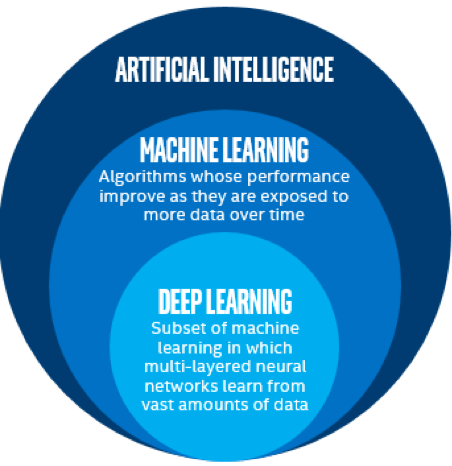
図 1: AI と主要なサブセット
ビジネス上の考察
データ戦略の決定1
AI にとって必要不可欠な要素は、データ (未来の通貨) にしっかりと根付いています。2020 年までに、500 億を超えるデバイスと 2,000 億を超えるセンサーがインターネットに接続されると予測されます。そして、それらは急激な計り知れない規模のデータを生み出すでしょう。2020 年には、平均的なインターネット・ユーザーは 1 日あたり最大 1.5GB のトラフィックを発生させると予測されています (2015 年の最大 650MB から倍増)。マシンを考慮するまでは、これは膨大な量のデータです。
- スマートホスピタルは 1 日に 3,000GB のデータを生成
- 自動運転車はそれぞれ 1 日に 4.000GB を超えるデータを生成
- 航空機は 1 日に 5,000GB のデータを生成
- コネクテッド・ファクトリーは、1 日あたり 1PB のデータを生成
これらのデータには、ビジネス、運用、セキュリティーに関連する重要な見識が含まれており、影響を受ける業界はリアルタイムでデータを抽出、解析、および解釈したいと考えています。データから価値を引き出すには自由に利用できる AI ツールが必要です。
AI への道のりの最初のステップは、データを準備することです。そのため、AI ビジネスモデルを考える場合、データのライフサイクル全体を考慮することが不可欠です。

図 2: AI データのライフサイクル (英語)
データ戦略には、多様なデータの生成、調達、転送、取得、クリーンアップ、および統合方法に加えて、処理を開始する前のデータの格納とステージングに関する明確な方針を含める必要があります。データ戦略は組織ごとに異なりますが、データのライフサイクルを認識し、競争力のあるデータ戦略を実現するためエンド・ツー・エンドの最適化されたデータベース・ソリューションの構築に注目します。
解決しようとするビジネス上の問題を解析1
AI に関する調査を始める前に、組織に AI を導入する工程を理解することが重要です。最初のステップは、組織全体が直面する課題を把握し、ビジネス上の価値とそれらを克服するために必要なコストに基づいて優先順位を付けることです。y 軸がビジネス上の価値 (上方向に増加) で、x 軸が解決に要するコスト (右方向に低下) の 2×2 のグラフを考えます。当然、最初に取り組むべき最も影響の大きい課題は右上のエリアです。次のステップは、どの AI ソリューションが問題解決に最適か判断し、そのソリューションを実装するのに必要な専門知識があるかどうかを評価することです。さらに、通常 AI プロジェクトは、伝統的で決定論的なソフトウェア開発プロジェクトよりも多くの不確実性、試行錯誤、および調査が伴うため、専門家チームがフェイルファストの継続的な改善方針を受け入れられるかどうか確認しておく必要があります。人的リソースが整ったら、次のステップはデータを調達して解析の準備をすることです。同時に、課題に取り組むために必要なすべてのテクノロジー・インフラを立ち上げます。
これで、ビジネス上の課題を解決するため、データを扱う準備はできました。しかし、組織がデータ主導の調査結果を受け入れて行動する準備ができていない限り、これまでの作業は無駄になります。典型的な例として、スポーツ分野におけるデータ解析に対する導入時の議論が上げられます。当初、ジェネラル・マネージャーとスカウトは、自身の長年の経験と専門知識を上回るコンピューター・アルゴリズムを物笑いにしていました。結論として、AI のライフサイクルにおけるすべてのステップを考えることで、AI を通して本来達成しようと考えていたビジネス価値を実現する可能性が高まります。
マサチューセッツ工科大学スローン・マネジメント・スクールの Thomas Malone 教授 (https://cci.mit.edu/malone/) は、マサチューセッツ工科大学集合知研究センターの創設者です。教授の研究のいくつかは、世界を変革するため集合的に働く人間とマシンに関するアイディアを探求しています。この集合的な人間と AI の知識が、ビジネス戦略にどのように影響するか理解することが重要です。強力なデータ戦略と、AI で解決しようとするビジネス上の問題に関する深い理解を組み合わせることで、将来のビジネスを加速できます。
TensorFlow* フレームワークの展開とサンプル
ここでは、インテル® Xeon® スケーラブル・プラットフォーム・ベース環境でのディープラーニングのトレーニングと推論向けに TensorFlow*フレームワークを展開する 3 つの方法を説明します。
| シングルノード | マルチノード | |
|---|---|---|
| オプション 1 | ベアメタル | ベアメタル |
| オプション 2 | コンテナー経由 | X (このドキュメントではカバーされません。参考文献をご覧ください6, 29。) |
| オプション 3 | クラウド | クラウド |
オプション 1: ベアメタル
シングルノードのインストール:
ここでは、TensorFlow* フレームワークと CIFAR-10 画像認識データセット (英語) を使用して、シングルノードのインテル® Xeon® スケーラブル・プロセッサー・システムをトレーニングして評価する方法を説明します。ここで紹介する手順をそのまま適用するか、機能拡張や変更の基礎として使用してください。
理解しておくべきこと:
- ハードウェア: このステップではインテル® Xeon® スケーラブル・プロセッサーで検証されていますが、最新のインテル® Xeon® プロセッサー・ベースのシステムでも動作するはずです。ここで使用されるソフトウェアは、いずれもパフォーマンスの最適化は行われていません。
- ソフトウェア: 基本的な Linux* とディープラーニングのトレーニングの概念に関する知識
ここでは、CentOS* 7.3 を実行する単一のインテル® Xeon® スケーラブル・プロセッサーで、画像認識の例を展開してテストする方法の 1 つを説明します。その他のインストール方法については、「Ubuntu* 上の TensorFlow* のインストール」 (英語)、「インテル® Optimization for TensorFlow* インストール・ガイド」 (英語) をご覧ください。このドキュメントでは、TensorFlow* のインストールに仮想環境を使用しました。Anaconda* を使用するには、最初に https://software.intel.com/en-us/articles/intel-optimization-for-tensorflow-installation-guide をご覧ください。このドキュメントは、最先端のパフォーマンスを達成する方法を解説するものではありません。ここでの目的は、TensorFlow* を導入して各種インテル® Xeon® プロセッサー・ベースのシステムで CIFAR-10 データセットのようなサンプルを使用して簡単なトレーニングとテストを実行することです。
ハードウェアとソフトウェアの構成
| 項目 | 製造元 | モデル/バージョン |
|---|---|---|
| ハードウェア | ||
| インテルベースのサーバーシャーシ | インテル | R1208WT |
| インテルベースのマザーボード | インテル | S2600WT |
| (2x) インテル® Xeon® スケーラブル・プロセッサー | インテル | インテル® Xeon® Gold 6148 プロセッサー |
| (6x) 32GB LRDIMM DDR4 | Crucial* | CT32G4LFD4266 |
| (1x) インテル® SSD 1.2TB | インテル | S3520 |
| ソフトウェア | ||
| CentOS* Linux* インストール DVD | 7.3.1611 | |
| インテル® Parallel Studio XE Cluster Edition | 2017.4 | |
| TensorFlow* | setuptools-36.7.2-py2.py3-none-any.whl |
ステップ 1. Linux* オペレーティング・システムのインストール
ここでは、CentOS* 7.3.1611 を使用しています。ソフトウェアの更新バージョンは、CentOS* ウェブサイト (英語)からダウンロードします。
付録を参照して OS のインストール手順を確認してください。
ステップ 2. YUM の設定
パブリック・ネットワークがインターネット・アクセス向けにプロキシーサーバーを実装している場合、Yellowdog Updater Modified* (YUM) を設定して使用する必要があります。
/etc/yum.conf ファイルを開いて修正します。
main セクションで次の行を追加します。
proxy=http://<address>:<port>;
ここで、<address> は proxy サーバーのアドレスで、<port> は HTTP ポートです。
ファイルを保存して終了します。
更新や追加を無効にします。このドキュメントの手順には、カーネルパッケージのリビルドが必要なものがあります。将来のカーネル・アップデートで、ビルドされたパッケージと新しいカーネルとの互換性が維持されない可能性があるため、リポジトリーの更新と追加を無効にすることを推奨します。
ここで記載される内容は、アップデートされた CentOS* に 「そのまま」適用することはできません。アップデート後にこのドキュメントを使用するには、CentOS* vault (英語) で CentOS* 7.3 を指すようにリポジトリー・パスを再定義する必要があります。リポジトリーの更新と追加を無効にするには次のコマンドを実行します: Yum-config-manager –disable updates –disable extras。
ステップ 3. EPEL のインストール
Extra Packages for Enterprise Linux * (EPEL)は、Linux* ディストリビューションの 100% 高品質アドオン・ソフトウェア・パッケージを提供します。EPEL をインストールするには次を実行します (すべてのパッケージで最新バージョンが必要)。
yum -y install
(https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm からダウンロードできます。)
ステップ 4. GNU* C コンパイラーのインストール
GNU* コンパイラー・コレクション (GCC) がインストールされているか確認します。これは本来、OS インストールの開発ツール・インストールの一部であるべきです (付録を参照)。次を実行して確認します。
gcc --version or whereis gcc
インストールされていない場合、こちら (英語) で最新版を確認してください。
次のコマンドを使用して、CentOS* の公式リポジトリーから GCC をインストールできます。
yum -y install gcc
ステップ 5. TensorFlow* のインストール
virtualenv3 を使用して、TensorFlow* をインストールするには次の手順に従ってください。
- 最新の EPEL ディストリビューションに更新します。
yum -y install epel-release
- TensorFlow* をインストールするには、依存関係のある次のパッケージをインストールする必要があります。
- NumPy*: TensorFlow* が必要とする数値処理パッケージ。
- Devel*: Python* への拡張機能の追加を可能にします。
- PIP: 特定の Python* パッケージのインストールと管理を可能にします。
- Wheel: Python* 圧縮パッケージをホイール形式 (.whl) で管理できるようにします。
- Atlas*: 線形代数ソフトウェアを自動的にチューニングします。
- Libffi: 特定の言語で記述されたコードが、別の言語で書かれたコードを呼び出すのを可能にする Foreign Function Interface (FFI) を提供します。これは、さまざまな呼び出し規約8 への、ポータブルなハイレベル・プログラミング・インターフェイスです。
- 依存関係があるコンポーネントをインストールします。
sudo yum -y install gcc gcc-c++ python-pip python-devel atlas atlas-devel gcc-gfortran openssl-devel libffi-devel python-numpy
- をインストールします。
TensorFlow* をインストール (英語) するには、いくつかの方法があります。ここでは、独立した Python* 環境9 を作成する virtualenv を使用します。
pip install --upgrade virtualenv
- ターゲット・ディレクトリーに virtualenv を作成します。
virtualenv --system-site-packages <targetDirectory>
例:virtualenv --system-site-packages tensorflow
- virtualenv4 をアクティベーションします。
source ~/<targetdirectory>/bin/activate
例:source ~/tensorflow/bin/activate
- 必要に応じてパッケージをアップグレードします。
pip install --upgrade numpy scipy wheel cryptography
- 最新の Python* 圧縮 TensorFlow* パッケージをインストールします。
pip install --upgrade
ここでは、TensorFlow* 0.8 wheel (英語) を使用して展開とテストを行いました。
Google* は定期的に TensorFlow* の最新バージョンをリリースしているため、最新の TensorFlow* wheel を使用することを推奨します。
GitHub* (英語) の「Community Supported Builds」の下にある、TensorFlow* wheel 向けに最適化されたディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN) を検索してください。
例4:

CPU のみのホイールファイルのバージョンも利用可能で、TensorFlow* ウェブページ (https://www.tensorflow.org/install/install_linux#InstallingVirtualenv) から入手できます。残念ながら CPU 向けに最適化されていません。
TensorFlow* wheel をインストールした後で、最新の TensorFlow* にアップグレードできますが、アップグレードされたバージョンは CPU 向けに最適化されていない可能性があります。
ステップ 6. 畳み込みニューラル・ネットワーク (CNN) のトレーニング
- CIFAR1011 トレーニング・データセットを /tmp/ ディレクトリーにダウンロードします。Python* バージョンはこちら (英語) から入手できます。
- Python* スクリプト (cifar10_train.py) は、/tmp/ ディレクトリーのデータを検索するため、このディレクトリーに tar ファイルを展開します。
tar -zxf <dir>/cifar-10-python.tar.gz
- TensorFlow* ディレクトリーに移動します。
cd tensorflow
- 新しいディレクトリーを作成します。
mkdir git_tensorflow
- 最後の手順で作成したディレクトリーに移動します。
cd git_tensorflow
- GitHub* から TensorFlow* リポジトリー (英語) のクローンをダウンロードします。
git clone https://github.com/tensorflow/tensorflow.git
- Models フォルダーが tensorflow/tensorflow ディレクトリーに存在しない場合、TensorFlow* GitHub*13 から Models の Git にアクセスします。
cd tensorflow/tensorflow git clone https://github.com/tensorflow/models.git
- 最新バージョンの TensorFlow* をインストールします。そうしないと、モデルのトレーニング時にエラーが発生する可能性があります。
pip install intel-tensorflow
- CIFAR-10 ディレクトリーに移動して、トレーニングおよび評価用の Python* スクリプト12 を入手します。
cd models/tutorials/image/cifar10
- トレーニング用コードを実行する前に、cifar10_train.py コードを確認し、必要に応じてステップを 100K から 60K に、ロギング頻度を 10 から任意の値に変更します。
ここでは、バッチサイズ 128 で 100K と 60K ステップの両方でテストを行い、ロギング頻度には 10 を使用します。
parser.add_argument('--max_steps', type=int, default=100000, help='Number of batches to run.') - トレーニング用の Python* スクリプトを実行してネットワークをトレーニングします。
python cifar10_train.py
これには数分かかりますが、次のような出力が表示されます。
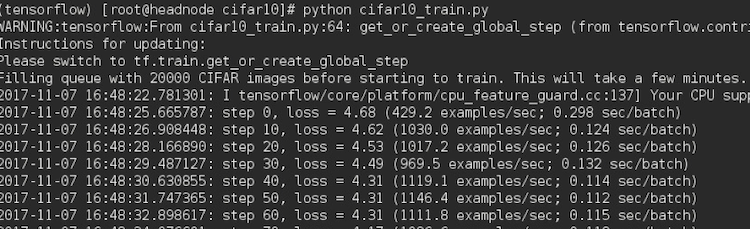
テストスクリプトとデータセット用語
ニューラル・ネットワークの用語:
- 1 エポック = すべてのトレーニング・サンプルの 1 前方/後方パス。
- バッチサイズ = 1 前方/後方パスで処理されるトレーニング・サンプルの数。バッチサイズが大きくなるとメモリー使用量が増加します。TensorFlow* は、1前方パスで (並列に) すべてをプッシュし、同じセットを後方パスに伝搬して続行します。これは、1 反復または 1 ステップです。
- 反復数 = パス数。それぞれのパスは [バッチサイズ] 個のサンプルを使用します。1 パス は 1 前方パス + 1 後方パスです (前方パスと後方パスを異なるパスとしてカウントしないでください)。
- ステップ・パラメーターは、TensorFlow* にこの反復を X 回実行してモデルをトレーニングするよう指示します。
例: 1000 のトレーニング・サンプルとバッチサイズ 500 の場合、1 エポックを完了するには 2 回の反復が必要になります。
エポック、バッチサイズ、および反復の違いに関する詳細は、「TensorFlow* パフォーマンス・ガイド」 (https://www.tensorflow.org/performance/performance_guide#optimizing_for_cpu) を参照してください。
cifar10_train.py スクリプトの場合:
- バッチサイズは 128 に設定します。これは、バッチ処理する画像の数を表します。
- 最大ステップは 100,000 (100K) に設定します。これは、すべてのエポックの反復数です。
注: GitHub* のコードには誤りがあります。最大ステップが 100K ではなく 1000K になっています。実行する前に更新してください。
- 「インテル® Optimization for TensorFlow* インストール・ガイド」 (英語) の CIFAR-10 バイナリーのデータセットには、60,000 枚の画像があります。このうち50,000 枚はトレーニング用で、10,000 枚はテスト用です。それぞれのバッチサイズは 128 であり、トレーニングするバッチ数は 1 エポックあたり、50,000/128 = 391 バッチです。
- cifar10_train.py では 256 エポックを使用したため、すべてのエポックの反復数は 391 x 256 = 100K 反復またはステップです。
ステップ 7. モデルの評価
cifar10_eval.py スクリプト8 を使用して、トレーニング・モデルがホールドアウト (テスト) データセットに対してどの程度うまく機能するか評価します。
python cifar10_eval.py
予想された精度に達すると、このコマンドを実行すると画面に精度 @ 1 = 0.862 が表示されます。これは、トレーニング・スクリプトがステップの最後に向かって処理を行っている間に実行することも、トレーニング・スクリプトが終了した後に実行することもできます。

この記事の「ハードウェアとソフトウェアの構成」に示すシステムを利用すると、次のような結果が得られます。
これらの値はここでの説明を目的としており、特定の CPU 向けの最適化は行われていないことに注意してください。
| システム | ステップ時間 (秒/バッチ) | 精度 |
|---|---|---|
| 2 – インテル® Xeon® Gold 6148 プロセッサー | ~ 0.105 | 60K ステップで 85.8% (~2 時間) |
| 2 – インテル® Xeon® Gold 6148 プロセッサー | ~0.109 | 100K ステップで 86.2% (~3 時間) |
CIFAR-10 データセットのトレーニングとテストが終了すると、同じ Models ディレクトリーに MNIST と AlexNet ベンチマークのイメージがあります。さらに学習を行うには、MNIST と AlexNet ディレクトリーに移動して、Python* スクリプトを実行し結果を確認してください。
マルチノードのインストール:
Wei Wang 氏と Mahmoud Abuzaina 氏の https://www.ai.intel.com/using-intel-xeon-for-multi-node-scaling-of-tensorflow-with-horovod/#gs.RtKNaoPy では、インテル® Xeon® スケーラブル・プロセッサーと Horovod と TensorFlow* を使用してパフォーマンスのスケーリングを達成する方法について詳しく説明しています。彼らのブログ (https://www.intel.ai/using-intel-xeon-for-multi-node-scaling-of-tensorflow-with-horovod/) がこのセクションの基になっています。
多くの複雑なディープラーニング・モデルでは、マルチノードでトレーニングを行う必要があります。これは、1 台のマシンに収まらないか、複数のマシンでトレーニングを行うことでトレーニング時間が大幅に短縮される可能性があるためです。そのため、インテルではインテル® Xeon® スケーラブル・プロセッサーのマルチノード・クラスターでもスケーリングの調査を行いました。ここでは、TensorFlow* 向けの分散トレーニング・フレームワークである Horovod を使用して、インテル® Xeon® スケーラブル・プロセッサーのクラスターに TensorFlow* を展開する手順を説明します。
Uber* によって開発された Horovod は、通信メカニズムとしてメッセージ・パッシング・インターフェイス (MPI) を使用します。allgather や allreduce などの MPI 概念を使用して、ノードレプリカ間の通信と重みを更新します。これらの概念をサポートするため、OpenMPI は Horovod と併用できます。Horovod は Python* パッケージとは別にインストールされます。ディープラーニング・ニューラル・ネットワーク・モデルのスクリプトから、Horovod API を呼び出すことで、TensorFlow* の通常ビルドを使用して分散トレーニングを実行できます。Horovod を使用することで、TensorFlow* のソースコードを変更することなく MPI による分散トレーニングをサポートできます。
ハードウェアとソフトウェアの構成
| 項目 | 製造元 | モデル/バージョン |
|---|---|---|
| ハードウェア | ||
| インテル® Xeon® スケーラブル・プロセッサー | インテル | インテル® Xeon® Gold 6148 プロセッサー |
| (12x) 16GB DDR4 @ 2666MT/s | ||
| (3x) インテル® SSD 800GB、1.6TB | インテル | RS3WC080 |
| ソフトウェア | ||
| CentOS* | CentOS 7.4 (Maipo) | |
| カーネル | 3.10.0-693.21.1.0.1.el7.knl1.x86_64 | |
| TensorFlow* | 1.7 |
ステップ 1. Linux* オペレーティング・システムのインストール
ここでは、CentOS* 7.4 を使用しています。ソフトウェアの更新バージョンは、CentOS* ウェブサイト (英語) からダウンロードします。
OS のインストール手順は付録を参照してください。
この記事では、マルチノードのクラスターが設定済みで、ヘッドノードと計算ノード間で通信が行われることを前提としています。クラスターの設定については、HPC クラスター・リファレンス・デザイン19 を参照してください。
ステップ 2. YUM の設定
パブリック・ネットワークがインターネット・アクセス向けにプロキシーサーバーを実装している場合、Yellowdog Updater Modified* (YUM) を設定して使用する必要があります。
/etc/yum.conf ファイルを開いて修正します。
main セクションで次の行を追加します。
proxy=http://<address>:<port>;
ここで、<address> は proxy サーバーのアドレスで、<port> は HTTP ポートです。
ファイルを [Save (保存)] して [Exit (終了)] します。
更新や追加を無効にします。このドキュメントの手順には、カーネルパッケージのリビルドが必要なものがあります。将来のカーネル・アップデートで、ビルドされたパッケージと新しいカーネルとの互換性が維持されない可能性があるため、リポジトリーの更新と追加を無効にすることを推奨します。
ここで記載される内容は、アップデートされた CentOS* に 「そのまま」適用することはできません。アップデート後にこのドキュメントを使用するには、CentOS* vault (英語) で CentOS* 7.3 を指すようにリポジトリー・パスを再定義する必要があります。リポジトリーの更新と追加を無効にするには次のコマンドを実行します: Yum-config-manager –disable updates –disable extras。
ステップ 3. EPEL のインストール
Extra Packages for Enterprise Linux * (EPEL)は、Linux* ディストリビューションの 100% 高品質アドオン・ソフトウェア・パッケージを提供します。EPEL をインストールするには次を実行します (すべてのパッケージで最新バージョンが必要)。
ダウンロード:
yum -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
ステップ 4. GNU* C コンパイラーのインストール
GNU* コンパイラー・コレクション (GCC) がインストールされているか確認します。これは本来、OS インストールの開発ツール・インストールの一部であるべきです (付録を参照)。次を実行して確認します。
gcc --version or whereis gcc
インストールされていない場合、こちら (英語) から最新版を入手できます。
次のコマンドを使用して、CentOS* の公式リポジトリーから GCC をインストールできます。
yum -y install gcc
ステップ 4. OpenMPI のインストール
最新の CentOS* では、OpenMPI は yum 経由でインストールできます。いくつかの既存のクラスターでは OpenMPI がすでにインストールされています。ここでは、OpenMPI 3.0.0 を使用します。OpenMPI は、こちら (英語) のサイトの手順に従ってインストールできます。
ダウンロード後の rpm ファイルのインストール例:
yum localinstall openmpi-3.0.0-1.src.rpm
ステップ 5. Python* のインストール
Python* 2.7 または Python* 3.6 がインストール済みで、動作することを確認します。OS インストールの一貫として、必要なパッケージがインストールされている必要があります。必要なパッケージを次の手順で更新します。
sudo yum update sudo yum install yum-utils sudo yum groupinstall development
Python* のインストールに進みます。ここでは、Python* 3.6.1 をインストールする手順を説明します。標準の yum リポジトリーでは最新の Python* リリースが提供されません。必要な PRM パッケージを取得するため、アップストリーム安定板 (IUM) と一致する追加リポジトリーが必要になります。
sudo yum install https://centos7.iuscommunity.org/ius-release.rpm
sudo yum install python36u
次のコマンドで Python* 3 のバージョンを確認します。
python3.6 -V
python -V はシステムの Python* バージョンを返します。
Python* パッケージを管理するため、導入されていなければ pip と必要な開発パッケージをインストールします。
sudo yum install python36u-pip sudo yum install python36u-devel
ステップ 6. Horovod のインストール
Uber* Horovod は、TensorFlow* を分散方式で実行するのをサポートします。次のように、Horovod をスタンドアロンの Python* パッケージとしてインストールします。
pip install -no-cache-dir horovod (例 horovod-0.11.3)
こちらのソース (英語) から、Horovod をインストールできます。
ステップ 7. 最新のベンチマークを入手
現在の TensorFlow* ベンチマークは、Horovod を使用できるように変更されています。GitHub* からベンチマークを取得します。
git clone https://github.com/tensorflow/benchmarks cd benchmarks/scripts/tf_cnn_benchmarks
次に示すように tf_cnn_benchmarks.py を実行します。
ステップ 8: Horovod を使用して TensorFlow* ベンチマークを実行
ここでは、Horovod フレームワークを使用した分散 TensorFlow* の実行に必要なコマンドについて説明します。
シングルノードで 2 つの MPI プロセスを実行します。
export LD_LIBRARY_PATH=<path to OpenMP lib>:$LD_LIBRARY_PATH
export PATH=<path to OpenMPI bin>:$PATH
export inter_op=2
export intra_op=18 {# cores per socket}
export batch_size=64
export MODEL=resnet50 {or inception3}
export python_script= {path for tf_cnn_benchmark.py script}
mpirun -x LD_LIBRARY_PATH -x OMP_NUM_THREADS -cpus-per-proc 20 --map-by socket --overscribe
--report-bindings -n 2 python $python_script --mkl=True --forward_only=False --num_batches=200
--kmp_blocktime=0 --num_warmup_batches=50 --num_inter_threads=$inter_op --distortions=False
--optimizer=sgd --batch_size=$batch_size --num_intra_threads=$intra_op --data_format=NCHW
--model=$MODEL --variable_update horovod --horovod_device cpu --data_dir <path-to-real-dataset>
--data_name <dataset_name>
ノードごとに 1 つの MPI プロセスを実行する場合、設定は次のようになり、ほかの環境変数に影響はありません。
export intra_op=38 export batch_size=128 mpirun -x LD_LIBRARY_PATH -x OMP_NUM_THREADS --bind-to none --report-bindings -n 1 python $python_script --mkl=True --forward_only=False --num_batches=200 --kmp_blocktime=0 --num_warmup_batches=50 --num_inter_threads=$inter_op --distortions=False --optimizer=sgd --batch_size=$batch_size --num_intra_threads=$intra_op --data_format=NCHW --model=$MODEL --variable_update horovod --horovod_device cpu --data_dir <path-to-real-dataset> --data_name <dataset_name>
注: 精度を上げるためモデルをトレーニングするには、-distortions=True オプションを使用します。その他のハイパーパラメーターも変更する必要があるかもしれません。
マルチノード・クラスター上でモデルを実行するには、上記と同様のスクリプトを使用します。例えば、インテル® Xeon® Gold 6148プロセッサー・ベースの 64 ノード (ノードあたり 2 MPI) クラスターで実行する場合、次のように分散トレーニングを開始します。すべてのエクスポート・ノードは、上記と同じになります。
mpirun -x LD_LIBRARY_PATH -x OMP_NUM_THREADS -cpus-per-proc 20 --map-by node --report-bindings -hostfile host_names -n 128 python $python_script --mkl=True --forward_only=False --num_batches=200 --kmp_blocktime=0 --num_warmup_batches=50 --num_inter_threads=$inter_op --distortions=False --optimizer=sgd --batch_size=$batch_size --num_intra_threads=$intra_op --data_format=NCHW --model=$MODEL --variable_update horovod --horovod_device cpu --data_dir <path-to-real-dataset> --data_name <dataset_name>
ここで、host_names ファイルには、ワークロードを実行するホスト名のリストを指定します。
インテル® Xeon® スケーラブル・プロセッサー上の DL トレーニングにとっての分散 TensorFlow* の意味
CPU と GPU 上で分散 TensorFlow* を実装するため、さまざまな取り組みが行われてきました。例えば、gRPC、VERBS、TensorFlow* 組込み MPI などです。これらのテクノロジーはすべて TensorFlow* コードベースに組込まれています。Uber* Horovod は、インテル® Xeon® スケーラブル・プロセッサーの能力を利用できる分散型 TensorFlow* テクノロジーの 1 つであり、MPI を基礎としてリングベースのリダクションにより、ディープラーニング・パラメーターを集約します。Wang 氏と Abuzaina 氏のブログ (https://ai.intel.com/using-intel-xeon-for-multi-node-scaling-of-tensorflow-with-horovod/#gs.5KdIleg0) で説明されているように、インテル® Xeon® スケーラブル・プロセッサー上の Horovod は、64 ノードで Resnet-50 (最大 94%) や Inception-v3 (最大 89%) など既存の DL ベンチマーク・モデルにおいて優れたスケーリングを示しています。つまり、64 個のインテル® Xeon® スケーラブル・プロセッサーを使用すると、DL ネットワークのトレーニングにかかる時間を、シングルノードと比較して 1/57 (Resnet-50) および 1/58 (Inception-v3) に短縮できます。現在、インテル社は、TensorFlow* ユーザーはインテル® Xeon® スケーラブル・プロセッサーで構成されるマルチノードのトレーニング向けに、インテル® Optimization for TensorFlow* と Horovod* MPI を使用することを推奨しています。
オプション 2: AI コンテナーの使用
シングルノードのインストール:
ハードウェアとソフトウェアの構成
| 項目 | 製造元 | モデル/バージョン |
|---|---|---|
| ハードウェア | ||
| (2x) インテル® Xeon® スケーラブル・プロセッサー | インテル | インテル® Xeon® Platinum 8164 プロセッサー |
| (12x) 32GB DDR4 @ 2666MT/s | ||
| (3x) インテル® SSD 800GB、1.6TB | インテル | RS3WC080 |
| ソフトウェア | ||
| CentOS* | CentOS* 7.5 | |
| カーネル | 3.10.0-862.el7.x86_64 | |
| TensorFlow* | 1.9 |
ステップ 1: Linux* オペレーティング・システムのインストール
ここでは、CentOS* 7.4 を使用しています。ソフトウェアの更新バージョンは、CentOS* ウェブサイト (英語) からダウンロードします。
付録を参照して OS のインストール手順を確認してください。
ステップ 2. YUM の設定
パブリック・ネットワークがインターネット・アクセス向けにプロキシーサーバーを実装している場合、Yellowdog Updater Modified* (YUM) を設定して使用する必要があります。
/etc/yum.conf ファイルを開いて修正します。
main セクションで次の行を追加します。
proxy=http://<address>:<port>;
ここで、<address> は proxy サーバーのアドレスで、<port> は HTTP ポートです。
ファイルを [Save (保存)] して [Exit (終了)] します。
更新や追加を無効にします。このドキュメントの手順には、カーネルパッケージのリビルドが必要なものがあります。将来のカーネル・アップデートで、ビルドされたパッケージと新しいカーネルとの互換性が維持されない可能性があるため、リポジトリーの更新と追加を無効にすることを推奨します。
ここで記載される内容は、アップデートされた CentOS* に 「そのまま」適用することはできません。アップデート後にこのドキュメントを使用するには、CentOS* vault (英語) で CentOS* 7.3 を指すようにリポジトリー・パスを再定義する必要があります。リポジトリーの更新と追加を無効にするには次のコマンドを実行します: Yum-config-manager –disable updates –disable extras。
ステップ 3. EPEL のインストール
Extra Packages for Enterprise Linux * (EPEL)は、Linux* ディストリビューションの 100% 高品質アドオン・ソフトウェア・パッケージを提供します。EPEL をインストールするには次を実行します (すべてのパッケージで最新バージョンが必要)。
yum -y install
(https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm からダウンロードできます。)
ステップ 4. GNU* C コンパイラーのインストール
GNU* コンパイラー・コレクション (GCC) がインストールされているか確認します。これは本来、OS インストールの開発ツール・インストールの一部であるべきです (付録を参照)。次のコマンドで確認できます。
gcc --version or whereis gcc
インストールされていない場合、こちら (英語) で最新版を確認してください。
次のコマンドを使用して、CentOS* の公式リポジトリーから GCC をインストールできます。
yum -y install gcc
ステップ 5. Anaconda* のダウンロードとインストール
Anaconda* をダウンロードしてインストールするには、Anaconda* ダウンロード・サイト (英語) の指示に従ってください。
Python* 2.7 向けの Anaconda* ソースファイルをダウンロードします。
(現時点では、TensorFlow* は Python* 2.7 と Python* 3.5 のみをサポートしているため、Python* 2.7 を使用することを推奨します。ここでは、Python* 2.7 を使用します。)
次のコマンド (英語) で Anaconda* をインストールします。
bash Anaconda-latest-Linux-x86_64.sh
画面の指示に従ってインストールを完了します。
注: Anaconda* のインストールをアクティブにするには、新しいターミナルを開く必要があります。
ステップ 6. Anaconda* から最新のインテル® Optimization for TensorFlow* をインストール
次のコマンドで Anaconda* プロンプトを開きます。
conda install tensorflow
画面の指示に従ってパッケージをダウンロードして展開します。
次のような出力が表示されます。
Anaconda* チャネルがデフォルトで最優先チャネルでない、または最優先チャネルであるかどうか不明な場合、次のコマンドで適切なインテル® Optimization for TensorFlow* を入手します。
conda install -c anaconda tensorflow3
次のような出力が表示されます。
この他に、インテル® Optimization for TensorFlow* は、Wheels、Docker* イメージ、および conda パッケージが https://ai.intel.com/tensorflow/ で配布されています。ここでは、Docker* イメージを使用したインテル® Optimization for TensorFlow* のインストールについて説明します。
ステップ 7. Docker* のインストール
システムに Docker* をインストールします。すでに Docker* がインストールされている場合は、ステップ 8 へ進んでください。
CentOS* (英語) に Docker* をインストールします。
yum install docker
完了すると次のような出力が表示されます。

EPEL リポジトリーをインストールして、システムで有効にします。
yum install epel-release yum install docker-io
Docker* パッケージをインストール後、デーモンを開始します。システム全体で有効にして、次のコマンドで状況を確認します。
systemctl start docker systemctl status docker systemctl enable docker
最後に、コンテナー・テスト・イメージを実行し、次のコマンドで Docker* が正しく動作していることを確認します。
docker run hello-world
Docker* が正しく動作している場合、次のような表示が表示されます。
注: プロキシーサーバーの影響により (企業内の設定など)、Docker* 接続タイムアウトの問題が発生する場合、Docker* システム・サービス・ファイル (英語) の設定を変更する必要があるかもしれません。
ステップ 8. 最新のインテル® Optimization for TensorFlow* Docker* イメージを既存の Python* インストールに追加
この Docker* イメージは、すべて intelaipg/intel-optimized-tensorFlow 名前空間の dockerhub (英語) で公開されており、次のコマンドを使用して取得できます。
docker pull docker.io/intelaipg/intel-optimized-tensorflow:<tag>
例:
docker pull docker.io/intelaipg/intel-optimized-tensorflow:latest-devel-mkl
利用可能なコンテナーの設定とタグは、https://software.intel.com/en-us/articles/intel-optimization-for-tensorflow-installation-guide にあります。
Docker* の取得が完了すると次のような出力が表示されます。
システムで利用可能なすべての Docker* イメージのリストを表示するには、次のコマンドを使用します。
docker images

次のコマンドで Python* 2.7 データ・サイエンス・コンテナーの例を実行し、Jupyter* Notebook で開きます。
docker run -it -p 8888:8888 intelaipg/intel-optimized-tensorflow
ブラウザーで http://localhost:8888/ にアクセスします。

‘devel‘ を含まない ‘latest’ およびその他のタグでは、デフォルトで対話型ターミナルは開きません。
docker run コマンドの最後に ‘/bin/bash‘ を追加することで、対話型ターミナルを強制的に開くことができます。例えば次のように入力します。
docker run -ti intelaipg/intel-optimized-tensorflow:latest /bin/bash
ステップ 9. 最新のベンチマークを入手
GitHub* から現在の TensorFlow* ベンチマークを取得します。
git clone https://github.com/tensorflow/benchmarks cd benchmarks/scripts/tf_cnn_benchmarks
以下で説明するように、tf_cnn_benchmarks.py を実行します。
注: コンテナーは最小限の機能を含むイメージであり、yum、wget、vi などの基本的な Linux* パッケージを Docker* コンテナーイメージにインストールする必要があります。ここでは、ベンチマークをクローン化する前に次のステップを実行しました。コンテナーイメージは Ubuntu* をベースにしています。
apt-get update apt-get install vim -y apt-get install yum apt-get install git
コンテナーに必要な更新/変更を加えたら、次のコマンドを使用して変更を終了し、イメージのローカルバージョンに保存します。
docker commit <container_ID> <name_you_like>
ここで、Container_ID は、最初にコンテナーを実行したときに示された ID です。
例:

ステップ 10: TensorFlow* ベンチマークを実行
ここでは、TensorFlow* CNN ベンチマークの実行に必要なコマンドについて説明します。
cd benchmarks/scripts/tf_cnn_benchmarks python tf_cnn_benchmarks.py --forward_only=True --device=cpu --mkl=True --kmp_blocktime=0 --nodistortions --batch_size=32 --model=inception3 --data_format=NCHW --num_intra_threads=4 --num_inter_threads=1
「TensorFlow* パフォーマンス・ガイド」 (https://www.tensorflow.org/performance/performance_guide#optimizing_for_cpu) に示されるコマンドを使用して、CPU 向けに最適化された結果を得る方法を理解します。上記のコマンド例は Inception-v3 モデル用ですが、tf_cnn_benchmark ディレクトリー内のその他のモデルにも使用できます。
マルチノードのインストール:
この記事の執筆時点では、インテル® テクノロジー向けに最適化された Docker* コンテナーはマルチノードで利用できないため、テスト手順には説明が含まれていません。しかし、「MLT を使用する Kubernetes* の Horovod 分散トレーニング」 (https://ai.intel.com/horovod-distributed-training-on-kubernetes-using-mlt/) のような公開済みのドキュメントを Kubernetes* での分散トレーニング向けに一読することを推奨します。さらに、TensorFlow* をマルチノードのコンテナー経由で展開するには、「インテル® Xeon® スケーラブル・プロセッサー・ベースのクラスターで TensorFLow* を使用してディープラーニングをスケールする方法」 (https://ai.intel.com/white-papers/best-known-methods-for-scaling-deep-learning-with-tensorflow-on-intel-xeon-processor-based-clusters/) と Nauta (https://www.intel.ai/nauta/#gs.87FTzVVC) を参照してください。このドキュメントでは、マルチノード環境で Singularity* コンテナーを作成し、展開/実行する方法を説明します。
オプション 3: クラウド上の AI
シングルノードのインストール:
クラウドを介して AI ワークロードを展開するため、さまざまなクラウド・サービス・プロバイダー (CSP) を利用できます。この記事では、クラウドに AI を展開する例として、主要な CSP を紹介します。
この例は、Amazon Web Services* (AWS)* 向けですが、その他の CSP を選択することもできます。
出典: AWS* 深層学習チュートリアル
ステップ 1: AWS* マネージメント・コンソールにサインイン
ユーザー名とパスワードを入力して、AWS* マネージメント・コンソールにサインインします。EC2* インスタンスを選択します。
ステップ 2: インスタンスの設定
- EC2* インスタンスを選択して [Launch Instance] をクリックします。
- AWS* 深層学習 AMI を選択します。
「TensorFlow* パフォーマンス・ガイド」 (https://www.tensorflow.org/performance/performance_guide#optimizing_for_cpu) に記載されているように、Amazon* Machine Instance (AMI) は Ubuntu* と Amazon* Linux* の両方で利用できます。アプリケーションに最適なものを選択します。このガイドでは、深層学習 AMI (Ubuntu) を選択します。
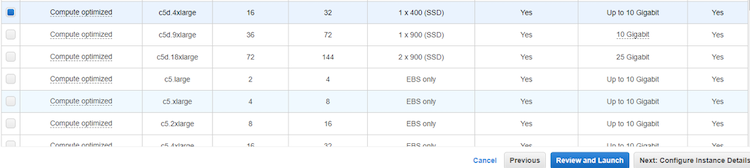
- 深層学習と展開のニーズに合わせてインスタンスのタイプを選択します。CPU 向けに最適化されたハードウェアとソフトウェアを利用するには、Compute Optimized Instance (C5) を選択して、[Review and Launch] をクリックします。
例:
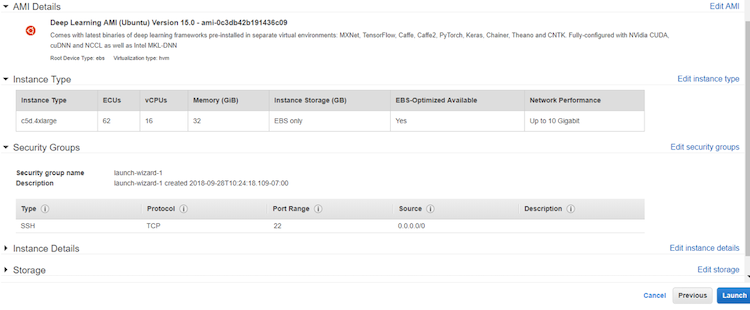
- [Review] ページで [Launch] を選択します。
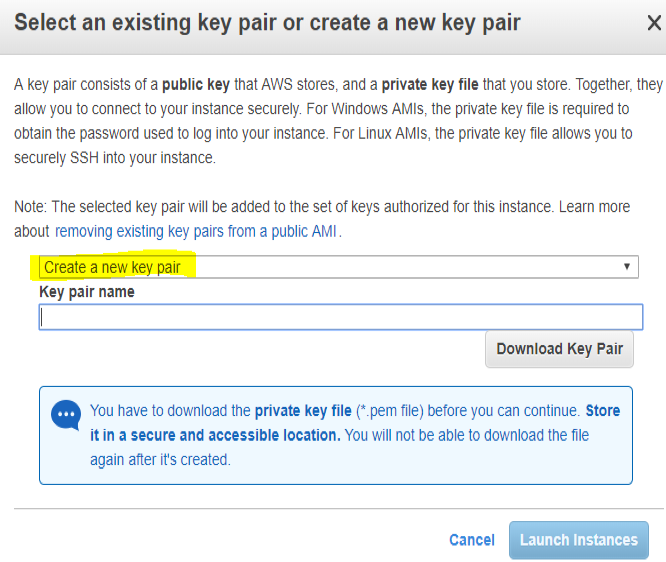
- [Create New Key Pair] を選択してプライベート・キー・ファイルを作成し、安全な場所にダウンロードします。インスタンスを起動します。次のような画面が表示されます。
注: 「your account is currently being verified.」というメッセージが表示されることがあります。認証は通常 2 時間以内で完了します。30 分後にインスタンスの起動を再試行できます。
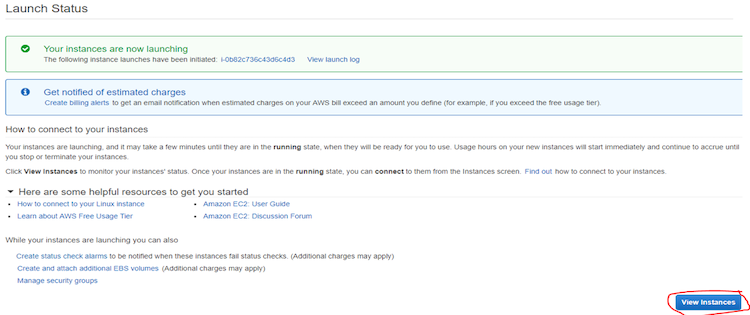
- インスタンスの状態を見るには、[View Instance] をクリックします。
例:
- [View Instance] をクリックしたら、インスタンスのパブリック DNS を見つけてコピーします。
表示例:
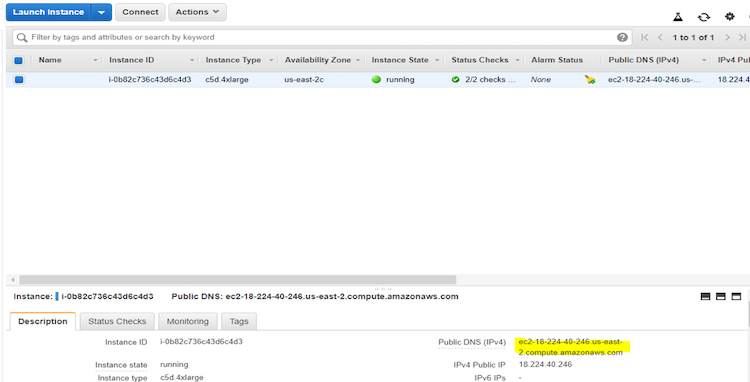
ステップ 3: インスタンスに接続
Windows* で AWS* 上のインスタンスと通信するためコマンドライン・ターミナルを起動するには、コマンドプロンプトを使用するか、Git for Windows* (英語) をダウンロードします。
- 以下のステップは [24] で説明されています。コマンドターミナルを開きます。
- セキュリティー・キーが格納されているディレクトリーに移動します。
- キー・ペア・ファイルのパーミッションを変更します。
- SSH を使用してインスタンスに接続します。
例:
cd /user/xzy/Downloads/ chmod 0400 <key_file_name.per> ssh -l localhost:8888:localhost:8888 -i <key_file_name.per> ubuntu@<your_instance_DNS_that_you_copied>
注: 企業内のネットワークに接続している場合、プロキシーを介してインスタンスに接続する必要があるかもしれません。
PuTTY* を使用:
- PuTTY* ダウンロード・ページ (英語) から PuTTY* をダウンロードしてインストールします。
- PuTTY* は、AWS* EC2* で生成される .pem ファイルをネイティブでサポートしていないため、.pem キーファイルを PuTTY* 形式 (.ppk) に変換します。
- プライベート・キーを変換します。
- Puttygen を起動します。
- [Key] メニューで生成するタイプに [RSA] を選択します。古いバージョンの PuTTYgen を使用している場合、[SSH-2 RSA key] を選択します。

- [Actions] で [Load] をクリックします。デフォルトで PuTTY* は .ppk ファイルのみを表示します。.pem ファイルを表示するには、ドロップダウン・メニューから [All Files (*.*)] を選択します。

- インスタンスの起動時に指定した AWS* キーペアの .pem ファイルを選択して、[開く] をクリックします。[OK] をクリックしてダイアログボックスを閉じます。
- [Save private key] を選択して、PuTTY* が使用可能な形式でキーを保存します。パスフレーズなしでキーを保存することに対して、PuTTYgen が警告を表示します。[Yes] をクリックします。
- キーペアに使用したキーと同じ名前を指定します。PuTTY* は自動的に .ppk ファイル拡張子を追加します。
- PuTTY* セッションを開始します。
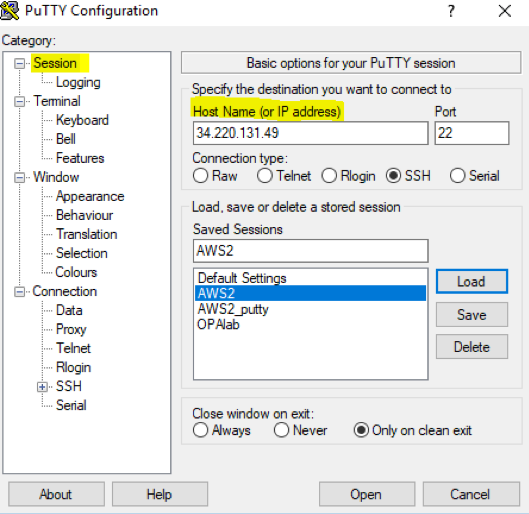
- PuTTY* を起動します。
- カテゴリーで [Session] をクリックして、[Host Name] に EC2* インスタンスの Ipv4 パブリック IP アドレスを入力します。
例:
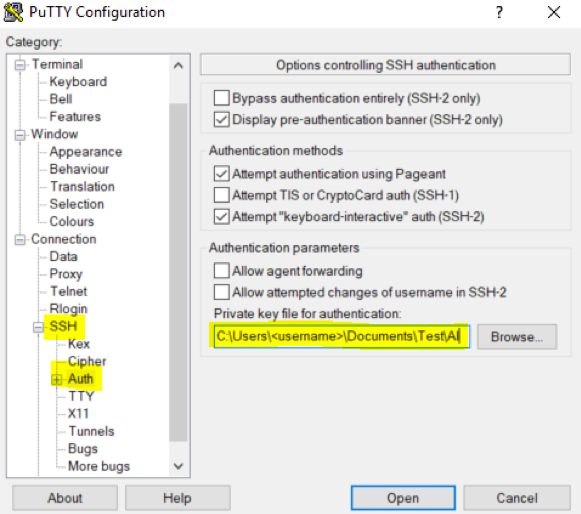
- [Connection] の下にある [SSH] をクリックして展開し、[Auth] をクリックします。[Auth] で、.pem ファイルから作成した .ppk ファイルへのリンクを追加します。
例:
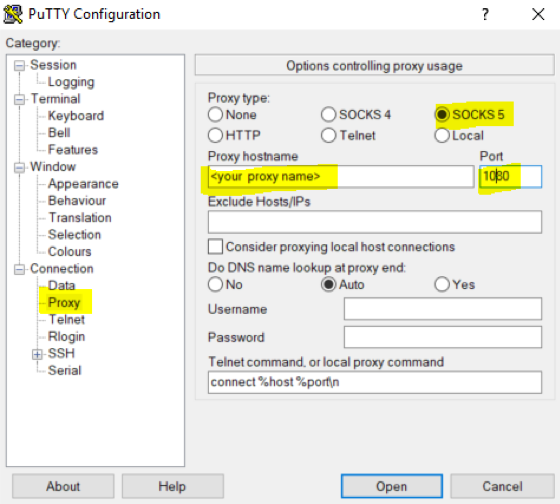
- 企業内のネットワークに接続している場合、[Proxy] をクリックして [Socks5] を選択して、プロキシー・ネットワークの名前を入力し、ポート 1080 を追加します。
例:
- 必要に応じて、[Session] タブで [Saved Sessions] に名前を付けて [Save] をクリックして保存します。
- 保存したら [Open] をクリックします。
- ubuntu としてログインします。
- 次の表示例のようにセッションは正常に開始されます。
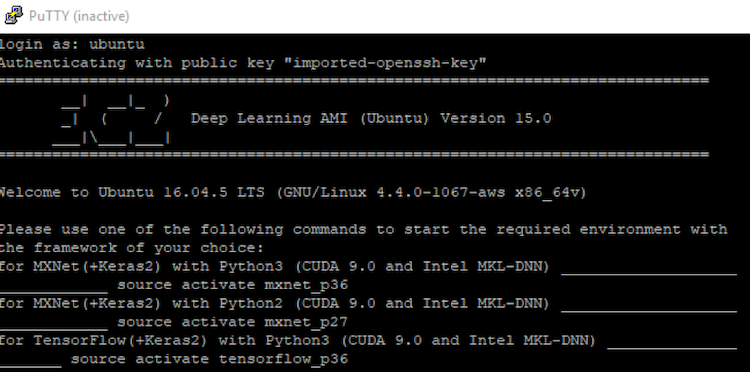
ステップ 4: 深層学習フレームワークを実行
Jupyter* を使用して、またはコマンドターミナルで直接深層学習フレームワークを開始します。
Jupyter* から実行する場合:
jupyter notebook と入力します。
Notebook にアクセスする URL をコピーして、深層学習フレームワークを開始します。
ターミナルから実行する場合:
この記事では、コンテナーを使用してインテル® Optimization for TensorFlow* フレームワークをインストールして、ベンチマークのサンプルを実行しています。実行中の AWS* インスタンスには、Docker* がインストールされているはずです。
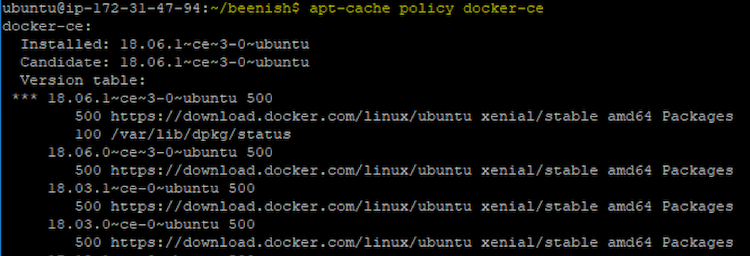
- Docker* のインストールを確認するには、次のコマンドを入力します。
apt-cache policy docker-ce
これで、Docker* がインストールされるはずです。「Installed: (none)」と表示される場合、インスタンスに Docker* をインストールします。Ubuntu* で Docker* をインストールするには、こちら (英語) の手順または同様のドキュメントに従ってください。
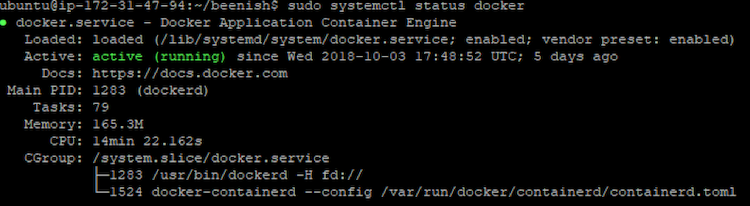
- Docker* の起動を確認するには、次のコマンドを使用します。
sudo systemctl status docker
Docker* が正しくインストールされているか確認するため、Docker* hello-world を実行します。
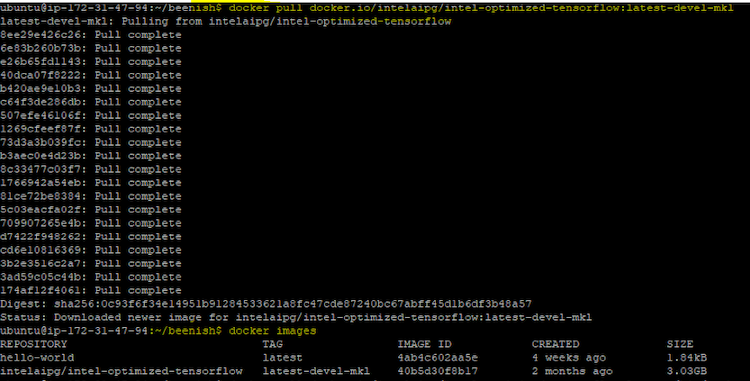
- 次のコマンドを使用して、インテル® Optimization for TensorFlow* Docker* コンテナーを取得します。オプション 2 の手順に従って詳細を確認します。
docker pull docker.io/intelaipg/intel-optimized-tensorflow:latest-devel-mkl
システムで利用可能なすべての Docker* イメージのリストを表示するには、次のコマンドを使用します。
docker images
- インテル® Optimization for TensorFlow* Docker* イメージを実行します。
‘devel’ を含まない ‘latest’ およびすべてタグでは、デフォルトで対話型ターミナルは開きません。
Jupyter* Notebook では、次のコマンドを使用します。
docker run -it -p 8888:8888 intelaipg/intel-optimized-tensorflow
ブラウザーで http://localhost:8888/ にアクセスします。
コマンドターミナルでは、次のコマンドを使用します。
docker run -ti intelaipg/intel-optimized-tensorflow:latest /bin/bash
‘latest’ タグは、自動的に最適化されたコンテナーの最新バージョンをロードします。
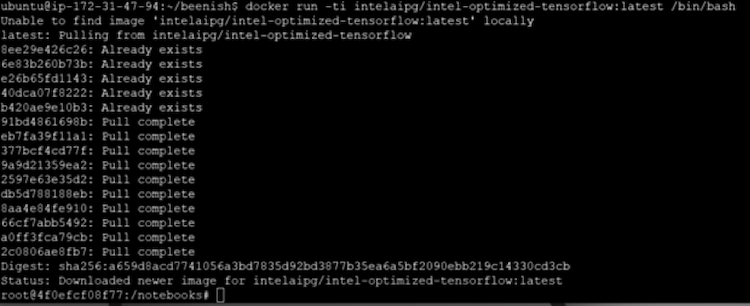
ステップ 5: TensorFlow* ベンチマークを実行
TensorFlow* コンテナーは最小限の機能を含むイメージであり、ベンチマークを実行する前に yum、wget、vi などの基本的な Linux* パッケージを Docker* コンテナーイメージにインストールする必要があります。ここでは、ベンチマークをクローン化する前に次のステップを実行しました。コンテナーイメージは Ubuntu* をベースにしています。
apt-get update apt-get install vim -y apt-get install yum apt-get install git
コンテナーに必要な更新/変更を加えたら、次のコマンドを使用して変更を終了し、イメージのローカルバージョンに保存します。
root@<container_ID>:/notebooks# exit root@<container_ID>:/notebooks# docker commit <container_ID> <name_you_like>
ここで、container_ID は、最初にコンテナーを実行したときの ID です。
例:

新しい Docker* イメージを実行します。
docker run -ti <new_name_you_gave_to_container_saved_above>:latest /bin/bash
例:

GitHub* から現在の TensorFlow* ベンチマークを取得します。
git clone https://github.com/tensorflow/benchmarks cd benchmarks/scripts/tf_cnn_benchmarks
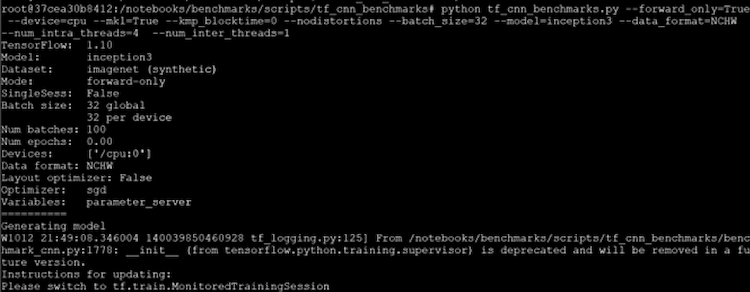
ここでは、TensorFlow* CNN ベンチマークの実行に必要なコマンドについて説明します。
python tf_cnn_benchmarks.py --forward_only=True --device=cpu --mkl=True --kmp_blocktime=0 --nodistortions --batch_size=32 --model=inception3 --data_format=NCHW --num_intra_threads=4 --num_inter_threads=1
ここで示されるコマンドを使用して、CPU 向けに最適化された結果が得られます。上記のコマンド例は Inception-v3 モデル用ですが、tf_cnn_benchmark ディレクトリー内のその他のモデルにも使用できます。
上記のコマンドを実行すると、次のような出力が表示されます。
注: Python* コマンドを実行すると、次のエラーメッセージが出力されます: 「No module experimental.ops,」。これはコンテナーの TensorFlow* のバージョンがベンチマークのバージョンと互換性がないことを意味します。
例: ベンチマークが TensorFlow* v1.12 と互換性があり、コンテナーが TensorFlow* v1.10 である場合、次のコマンドを使用して互換性のあるベンチマークをダウンロードできます。
git clone -b cnn_tf_v1.10_compatible https://github.com/tensorflow/benchmarks
ステップ 6: インスタンスの終了
マルチノードのインストール:
ここでは、Google Cloud Platform* と Google* Machine Learning (ML) エンジンを使用して、分散 TensorFlow* を実行する手順を説明します。Google* ML エンジンでインスタンスを実行し、TensorFlow* を展開して、分散トレーニングを実行する際に standard_1 層を選択することで割り当てられる全 CPU マルチノード設定でサンプル・トレーニングを実行する方法を詳しく説明します。ここで説明する手順の大部分は、Google* ML エンジンの「入門ガイド」 (https://ai.intel.com/white-papers/best-known-methods-for-scaling-deep-learning-with-tensorflow-on-intel-xeon-processor-based-clusters) を参照しています。
Google Cloud Platform* (GCP) の使用
出典: TensorFlow* 入門ガイド (https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction)
ステップ 1: Google* アカウントにサインイン
ステップ 2: [リソースマネージ] ページで GCP プロジェクトを選択または作成
ステップ 3: これらの手順に従って、プロジェクトの請求先を有効にする
ステップ 4: このリンクをクリックして、Cloud Machine Learning エンジンと Compute Engine API を有効にする:
次のような画面が表示されます。プロジェクトを選択して、[Continue] をクリックします。API を有効にするにはしばらく時間がかかります。
API が有効になると、次のような画面が表示されます。
ステップ 5: 認証の設定
- GCP コンソールで、サービスアカウントのキーを作成ページに移動します。
- [service account] ドロップダウン・リストから、[New Service Account] を選択します。
- [Service Account Name] フィールドに名前を入力します。
- [Role] ドロップダウン・リストで、[Project] > [Owner] を選択します。
- [Create] をクリックします。キーを含む JSON ファイルがコンピューターにダウンロードされます。
ステップ 6: 環境変数の設定
環境変数 GOOGLE_APPLICATION_CREDENTIALS に、サービス・アカウント・キーを含む JSON ファイルのパスを設定します。この変数は現在のシェルセッションでのみ有効です。新しいセッションを開いた場合、変数を再度設定してください。
Windows* では、コマンドプロンプトで次を実行します。
set GOOGLE_APPLICATION_CREDENTIALS= "<PATH>"
ステップ 7: こちら (英語) の手順に従って、Cloud SDK をインストールして初期化
- Cloud SDK のインストーラーをダウンロードして、正しい Google* 認証情報でサインインします。
注: 企業のファイアウォール内からダウンロードして「Download Failed: connecting to host」というメッセージが表示された場合、ファイアウォールを回避できない際はこちら (英語) の手順に従ってアーカイブからインストールしてください。
- インストーラーを起動し、指示に従ってください。
- インストールが完了したら次の操作を行います。
- Cloud SDK シェルを開始します (Windows* 環境では、デフォルトで起動しない場合、インストールされている SDK を見つけてクリックします)。次のようなコマンドプロンプトが開きます。

- gcloud init を実行します (Windows* では、ターミナルウィンドウで gcloud init と入力します)。
認証が完了し、次のような Web ページが表示されることを確認します。
注: ネットワーク・プロキシーを使用している場合、適切な HTTPS_PROXY と HTTP_PROXY アドレスを gcloud セットアップで設定します。
例:
- Cloud SDK シェルを開始します (Windows* 環境では、デフォルトで起動しない場合、インストールされている SDK を見つけてクリックします)。次のようなコマンドプロンプトが開きます。
- クラウド・プロジェクトの設定が完了すると、システムはタイムゾーンの設定を促します。ここで設定するタイムゾーンは、非常に重要です。後でクラウドで分散トレーニング中に、クラウド・ストレージ・バケットの地域を作成する必要があり、その地域と ML Cloud エンジンを実行するために選択したタイムゾーンが一致する必要があります。
- 完了すると、Google Cloud* SDK が設定され、利用可能になったことを示すメッセージが表示されます。
例:
ステップ 8: 環境設定
ここで説明する手順は、Google Cloud* AI と機械学習プロダクトページ (https://ai.intel.com/white-papers/best-known-methods-for-scaling-deep-learning-with-tensorflow-on-intel-xeon-processor-based-clusters) を参照しています。Google* は、macOS* と Cloud Shell (macOS*、Linux*、および Windows* 向け) の両方でローカル環境を設定する手順を公開しています。ここでは、Windows* マシンで実行されている Cloud Shell の手順のみを説明します。
- Google Cloud Platform* コンソール (英語) を開きます。
次のようなページページが開きます。左上のドロップダウン・メニューからプロジェクトを選択できます。
- コンソール・ウィンドウの上部にある [Activate Google Cloud Shell] ボタンをクリックします。

次のような画面が開きます。[Start Cloud Shell] をクリックして開始します。
Cloud Shell マシンが開始されるのを待ちます。

Cloud Shell セッションは、Google Cloud Platform* ページの下部の新しいフレームに開きます。次のような画面が表示されます。
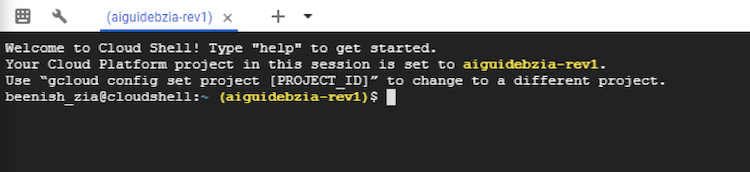
- Google Cloud Platform* ページでプロジェクト ID を選択していない場合、次のコマンドを使用して設定するか、別のプロジェクト ID に変更します。
gcloud config set project <project-ID>
ステップ 9: Google Cloud* SDK コンポーネントを確認
- モデルをリストします。
gcloud ml-engine models list
まだモデルを作成していない場合、このコマンドは空のリストを表示します。

- gcloud がすでにインストールされている場合、gcloud を更新します。
gcloud components update
TensorFlow* のインストール
TensorFlow* をインストールするには、次のコマンドを実行します。
pip install -user -upgrade tensorflow

デフォルトでは、TensorFlow* はすでにインストールされているため、最新の TensorFlow* のバージョンと要件に関するメッセージが表示されます。
簡単な TensorFlow* Python* プログラムの実行 (オプション)
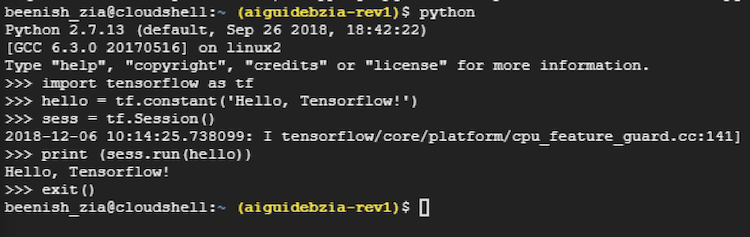
次の Python* プログラムを実行して、TensorFlow* のインストールの正当性を確認してください。
import tensorflow as tf
hello= tf.constant('Hello, Tensorflow!')
sess = tf.Session()
print(sess.run(hello))
実行に成功すると以下が出力されます。
Hello, Tensorflow! >>> exit()
テストの結果は次のようになります。
Google Cloud* AI と機械学習プロダクトページ (https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction) に示されるように、Cloud ML エンジンはデフォルトで Python* 2.7 を実行しますが、ここでのサンプルコードも Python* 2.7 を使用しています。Python* 3.5 を使用してジョブを送信する方法については、Google Cloud* AI と機械学習プロダクトページ (https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction) で確認してください。
ステップ 10: サンプルコードのダウンロード
ここでは、Windows* で Cloud Shell を実行する手順を示します。Google Cloud* AI と機械学習プロダクトページ (https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction) のスタートガイドでは、macOS* と Cloud Shell での手順が紹介されています。
- GitHub* リポジトリーから、サンプルの zip ファイルをダウンロードします (https://github.com/GoogleCloudPlatform/cloudml-samples/archive/master.zip)。
サンプル zip ファイルを unzip して cloudml-samples-master ディレクトリーを展開します。
unzip master.zip
出力例:
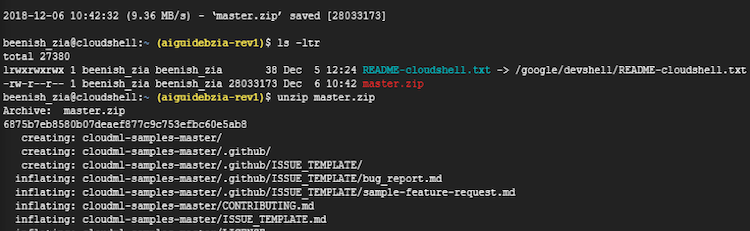
- cloudml-samples-master/census/estimator ディレクトリーに移動します。この記事で示すコマンドは、estimator ディレクトリーで実行する必要があります。
cd cloudml-samples-master/census/estimator
ステップ 11: トレーニング・データの取得
Google* は、このセッションで使用する関連データファイル adult.data と adult.test を保持するパブリックなクラウド・ストレージ・バケットをホストしています。
- データ・ディレクトリーを作成し、estimator ディレクトリーにデータをダウンロードします。
mkdir data gsutil -m cp gs://cloud-samples-data/ml-engine/census/data/* data/
- 変数 TRAIN_DATA と EVAL_DATA にファイルパスを設定します。
例:
TRAIN_DATA=<local path>/data/adult.data.csv EVAL_DATA=<local path=>/data/adult.test.csv
ステップ 12: 依存関係のインストール
TensorFlow* は、Cloud Shell にインストールされていますが、このセクションのサンプルは TensorFlow* 1.10 をベースにしています。同じバージョンの TensorFlow* と必要な依存関係がインストールされていることを確認するため、サンプルに含まれる requirements.txt ファイルを実行します。
現在のディレクトリーが clouldml-samples-master/census/estimator であることを確認します。
requirements.txt ファイルは 1 つ上の階層にあります。
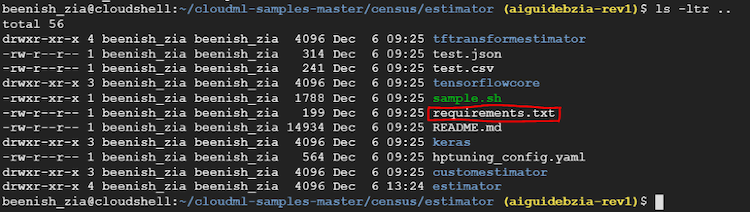
次を実行します。
pip install --user -r ../requirements.txt
ステップ 13: クラウド・ストレージ・バケットの設定
- 新しいバケットの名前を指定します。この名前は、クラウドストレージのすべてのバケットで一意である必要があります。
BUCKET_NAME ="<your bucket name>"
注: バケット名が一意になるように、次のコマンド例のようにプロジェクト名に -mlengine を付けることを推奨します。
PROJECT_ID=$(gcloud config list project -format "value(core.project)") BUCKET_NAME=${PROJECT_ID}-mlengine - 作成したバケット名を確認します。
echo $BUCKET_NAME
出力例:

- バケットの地域を選択して、環境変数を設定します。
REGION=<name of region>
例:
REGION=us-west1
注 1: バケットに固有の地域を指定します。複数の地域を設定することはできません。Google Cloud* AI と機械学習プロダクトページ (https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction) で Cloud ML エンジンが利用可能な地域を検索してください。
注 2: Cloud ML エンジンジョブを実行しようとする地域 (「Google Cloud Platform* の使用」サブセクションの手順 7 で選択した地域) と同じ地域を使用します。
注 3: セッションを再開すると、BUCKET_NAME と REGION 環境変数が失われる可能性があります。次のステップに進む前に、(特に Cloud Shell を再起動した場合) 変数の設定を確認することを推奨します。
- 新しいバケットを作成します。
gsutil mb -l $REGION gs://$BUCKET_NAME
出力例:

ステップ 14: クラウド・ストレージ・バケットにデータファイルをアップロード
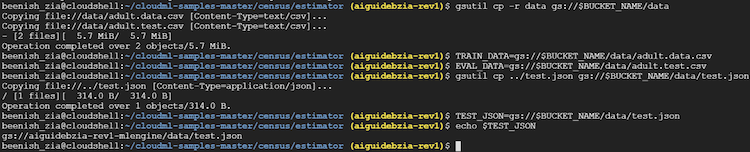
- gsutil を使用して、2 つのファイルを新たに作成したクラウド・ストレージ・バケットにコピーします。
gsutil cp -r data gs://$BUCKET_NAME/data
- TRAIN_DATA と EVAL_DATA 環境変数が、クラウド・ストレージ・バケットのファイルの場所を示すように設定します。
TRAIN_DATA=gs://$BUCKET_NAME/data/adult.data.csv EVAL_DATA=gs://$BUCKET_NAME/data/adult.test.csv
- gsutil を使用して JSON テストファイルをクラウド・ストレージ・バケットにコピーします。
gsutil cp ../test.json gs://$BUCKET_NAME/data/test.json
- TEST_JSON にファイルのパスを設定します。
TEST_JSON=gs://$BUCKET_NAME/data/test.json
クラウド・ストレージ・バケットへのデータファイルのアップロードの例を次に示します。
ステップ 15: クラウドで分散トレーニングを実行
Google Cloud*でトレーニング・ジョブを分散モードで実行するコマンドは、単一インスタンスでトレーニングを実行するコマンドと良く似ています。この記事では、Google Cloud*の単一インスタンスでトレーニングを実行する手順はカバーしませんが、Google Cloud* AI と機械学習プロダクトページ (https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction) でご覧いただけます。単一インスタンスとマルチインスタンスのトレーニングの主な違いは、単一インスタンス比較して層を調整するため-scale-tier を設定することです。Google Cloud* ML エンジンで利用可能なスケール層に関する情報は、https://cloud.google.com/ml-engine/docs/tensorflow/machine-types をご覧ください。
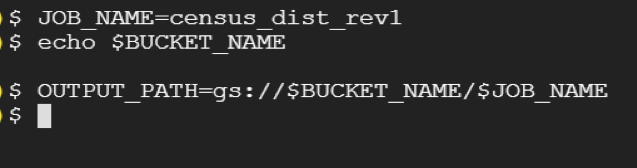
- 分散トレーニング・ジョブに名前を付けます。
JOB_NAME=<your distributed training name>
例:
JOB_NAME=census_dist_rev1
- OUTPUT_PATH を作成します。ジョブ間でチェックポイントを再利用しないように、JOB_NAME を追加することを推奨します。
注: 新しい Shell セッションを開始したときは、BUCKET_NAME を再定義する必要があります。echo $BUCKET_NAME を実行して、変数が正しく設定されていることを確認します。
OUTPUT_PATH=gs://$BUCKET_NAME/$JOB_NAME
例:
- 次のコマンドを実行して、複数のワーカーを使用する分散トレーニング・ジョブを Google Cloud* に送信します。この例では、すべての CPU ベースの構成を使用するため standard_1 スケール層を選択しています。ジョブを開始するにはしばらく時間がかかります。
ユーザー引数とコマンドライン引数を区切る — の前に –scale-tier をを指定します。
例31:
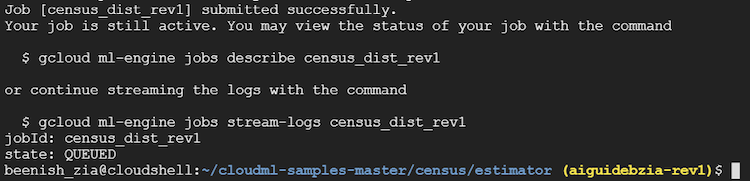
gcloud ml-engine jobs submit training $JOB_NAME \ --job-dir $OUTPUT_PATH \ --runtime-version 1.10 \ --module-name trainer.task \ --package-path trainer/ \ --region $REGION \ --scale-tier STANDARD_1 \ -- \ --train-files $TRAIN_DATA \ --eval-files $EVAL_DATA \ --train-steps 1000 \ --verbosity DEBUG \ --eval-steps 100
ジョブが正しく送信されると次のような出力が表示されます。
コマンドラインの出力をモニターするか、Google Cloud Platform* コンソールで [ML Engine] > [Jobs] を選択して進捗状況を監視します。
完了すると次のような画面が表示されます。
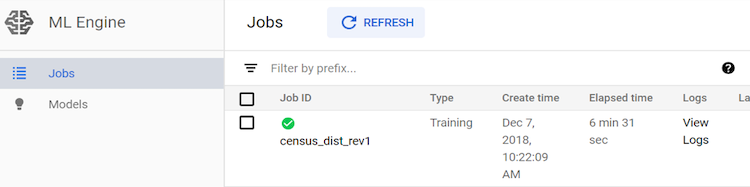
次のコマンドで Cloud Shell のジョブ状態を表示します。
gcloud ml-engine jobs describe census_dist_rev1
これにより、次のような出力が表示されます。
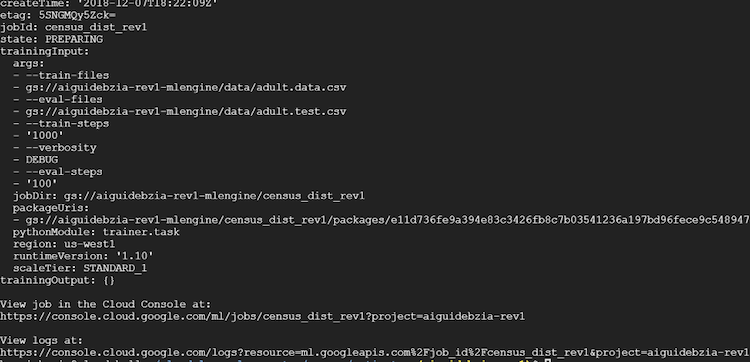
トレーニングが完了すると、状態変数は “SUCCEEDED” を示します。
ステップ 16: ログを調査
分散トレーニングによって生成されたログを確認する方法は 2 つあります。
[GCP Console ML Engine] > [Jobs] に移動して、[View Logs] をクリックするか、Cloud Shell ターミナルで次のコマンドを入力します。
gcloud ml-engine jobs stream-logs $JOB_NAME
ハイパーパラメーターのチューニング (オプション)
ハイパーパラメーターのチューニングは、モデルの予測精度を高めるのに役立ちます。このセクションで使用する人口調査の例では、hptuning_config.yaml という名前の YAML ファイルにハイパーパラメーターの設定が格納されています。このファイルをテンプレートとして特定のモデルとトレーニングに使用します。
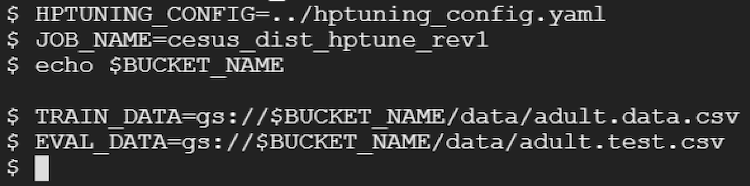
- 新しいジョブ名を選択して、その設定を参照する変数を作成します。
HPTUNING_CONFIG=../hptuning_config.yaml JOB_NAME=cesus_dist_hptune_rev1 echo $BUCKET_NAME TRAIN_DATA=gs://$BUCKET_NAME/data/adult.data.csv EVAL_DATA=gs://$BUCKET_NAME/data/adult.test.csv
出力例:
- 上記のように OUTPUT_PATH を設定します。BUCKET_NAME が定義され、ジョブ間で誤ってチェックポイントを使用していないことを確認します。
OUTPUT_PATH=gs://$BUCKET_NAME/$JOB_NAME
- 次のコマンドを実行して、複数のノードに対してハイパーパラメーター・チューニングを使用するトレーニング・ジョブを送信します。
gcloud ml-engine jobs submit training $JOB_NAME \ --stream-logs \ --job-dir $OUTPUT_PATH \ --runtime-version 1.10 \ --config $HPTUNING_CONFIG \ --module-name trainer.task \ --package-path trainer/ \ --region $REGION \ --scale-tier STANDARD_1 \ -- \ --train-files $TRAIN_DATA \ --eval-files $EVAL_DATA \ --train-steps 1000 \ --verbosity DEBUG \ --eval-steps 100
- GCP コンソールから [ML Engine] > [Jobs] を選択して結果を表示します。
ステップ 17: 予測をサポートするためモデルを展開 (INFERENCE)
- ジョブ名の選択と同様に、モデル名を選択します。名前は文字で始まる必要があり、文字、数字、および下線を含めることができます。
例:
MODEL_NAME=census_rev1
- Cloud ML エンジンモデルを作成します。
gcloud ml-engine models create $MODEL_NAME --regions=$REGION
- 使用する出力パスを作成します。例えば、ジョブ名として census_dist_rev1 を使用します。これは、分散型の非ハイパーパラメーター・チューニングのサブセクションで作成されたものと同じです。
OUTPUT_PATH=gs://$BUCKET_NAME/census_dist_rev1
- エクスポートしたトレーニング済みモデル・ライブラリーへのフルパスを調査します。
gsutil ls -r $OUTPUT_PATH/export
出力例:

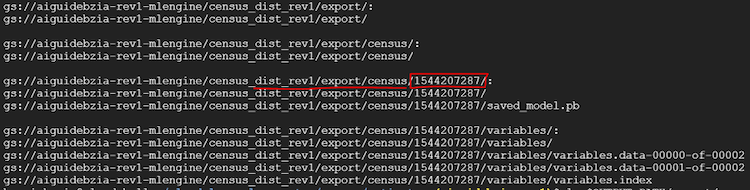
- 上記のステップでは、$BUCKET_NAME/export の下のすべてのディレクトリーが表示されます。$OUTPUT_PATH/export/census/<timestamp> ディレクトリーを検索し、このディレクトリー・パスをコピーして (最後にコロン「:」を追加して) MODEL_BINARIES ラベルに設定します。上記の出力例の赤く強調された部分をご覧ください。
MODEL_BINARIES=gs://$BUCKET_NAME/census_dist_rev1/export/census/1544207287/
- 次のコマンドを実行してバージョン rev1 を作成します。
gcloud ml-engine versions create rev1 --model $MODEL_NAME -origin $MODEL_BINARIES --runtime-version 1.10
これにはしばらく時間がかかります。完了すると次のような画面が表示されます。

- list コマンドでモデルのリストを取得します。
gcloud ml-engine models list
出力結果は以下のようになります。

ステップ 18: 展開モデルにオンラインの予測要求を送信
モデルを展開したら、予測要求を送信できます。次の gcloud コマンドは、上記のステップでダウンロードされた test.json ファイルを使用してオンラインの予測要求を送信します。
gcloud ml-engine predict --model $MODEL_NAME --version v1 --json-instances ../test.json
コマンドを実行すると次のような結果が表示されます。

この結果は、予測される収入が $50,000 以上か、以下かを示しています。
Google Cloud* AI と機械学習プロダクトページ (https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction) で、バッチ予測ジョブを送信する方法が詳しく説明されています。バッチ予測は、大量のデータを処理し、予測結果を受信するまでのレイテンシーにこだわらない場合に有用です。バッチ予測では、オンライン予測と同じ形式が使用されますが、クラウドストレージ上のデータが利用されます。
バッチ予測は大規模なデータに適しているため、少ないインスタンスでは低速です。
ステップ 19: クリーンアップ
トレーニングと推論の結果出力を解析したら、次のコマンドを使用してクラウドストレージをクリーンアップし、追加の GCP 料金が発生しないようにしてください。
gsutil rm -r gs://$BUCKET_NAME/$JOB_NAME
さまざまなワークロードの展開方法を理解するため、Google* の AI と機械学習プロダクトページ (https://cloud.google.com/ml-engine/docs/tensorflow/samples) には、各種サンプルとチュートリアルが用意されています。
まとめ
この記事では、初心者レベルの AI 実践者向けに、インテル® Xeon® スケーラブル・プロセッサー・プラットフォームで TensorFlow* を展開し、サンプルのトレーニングと推論ジョブを実行する詳しい手順と、AI に関連するビジネス上の考慮事項を紹介しました。
インテルや多くのエコシステム・パートナーは、皆さんが AI を探求するのに役立つ開発者向けのリソースを提供しています。インテルの豊富な AI 製品の詳細については、インテル® AI (英語) をご覧ください。また、AI ビルダーパートナー、AI ブログ、ソリューション、リファレンス・デザイン、および導入事例などは、インテル® AI Builders (https://builders.intel.com/ai) で紹介されています。
付録
Linux* オペレーティング・システムのインストール
ここでは、CentOS* 7-x86_64-*1611.iso が必要です。このソフトウェア・コンポーネントは、CentOS* ウェブサイト (英語) からダウンロードできます。
この記事で説明した手順の実装と検証には DVD ISO を使用しましたが、Everything ISO と Minimal ISO も使用できます。
Linux* のインストール手順
- CentOS* 7.3 1611 インストール・ディスク/USB を挿入します。ドライブから起動して、[Install CentOS 7 (CentOS 7 をインストール)] を選択します。
- [Date (日付)] と [Time (時間)] を設定します。
- 必要に応じて、[Installation Destination (インストール先)] を設定します。
- [automatic partitioning (自動的にパーティションを作成)] オプションを選択します。
- ホームに戻るには [Done (完了)] をクリックします。パーティション作成ウィザードでプロンプトが表示されたら、すべてデフォルトの設定を使用します。
- [Network and hostname (ネットワークとホスト名)] を選択します。
- ホスト名に “<hostname>” を入力します。
- [Apply (適用)] をクリックしてホスト名を有効にします。
- [Ethernet enp3s0f3 (イーサーネット enp3s0f3)] を選択して、[Configure (設定)] をクリックし外部インターフェイスを設定します。
- [General (全般)] セクションで、[Automatically connect to this network when it’s available (ネットワークが利用可能になったら自動的に接続)] をオンにします。
- 必要に応じて外部インターフェイスを設定します。[Save (保存)] して [Exit (終了)] します。
- インターフェイスのトグルを [ON (オン)] にします。
- インターフェイスのトグルを [ON (オン)] にします。
- ホスト名に “<hostname>” を入力します。
- [Software Selection (ソフトウェアの選択)] を選択します。左にある [Base Environment (基本環境)] ボックスで、[Infrastructure server (インフラストラクチャー・サーバー)] を選択します。
- ホームに戻るには [Done] をクリックします。
- [Begin Installation (インストールの開始)] ボタンが表示されるまで待ちます。これには時間がかかることがあります。ボタンが表示されたらクリックして続行します。
- インストールが完了するまでの間に root のパスワードを設定します。
- インストールが完了したら [Reboot (再起動)] をクリックします。
- プライマリー・デバイスからブートして root でログインします。
参考資料
- 人口知能の多彩な定義
https://newsroom.intel.com/news/many-ways-define-artificial-intelligence/#gs.96QbZ - Ubuntu* で TensorFlow* をインストール (6/25/18) (https://www.tensorflow.org/install/install_linux)
- インテル® Optimization for TensorFlow* インストール・ガイド (英語)
- AI データ・ライフサイクル
https://ai.intel.com/horovod-distributed-training-on-kubernetes-using-mlt/ - TensorFlow* のダウンロードと設定 (http://www.tensorflow.org/versions/r0.12/get_started/os_setup)
- MLT を使用する Kubernetes* の Horovod 分散トレーニング
https://software.intel.com/en-us/articles/intel-optimization-for-tensorflow-installation-guide - ソースから TensorFlow* をインストール (https://www.tensorflow.org/install/install_sources)
- 移植可能な外部関数インターフェイス・ライブラリー (Libffi) (英語)
- Virtualenv (英語)
- CentOS* 7 で TensorFlow* をインストール (6/25/18) (英語)
- CIFAR-10 データセット (英語)
- CIFAR-10 の詳細 (https://www.tensorflow.org/tutorials/deep_cnn)
- TensorFlow* のモデル (英語)
- エポック、バッチサイズおよび反復の違い (https://towardsdatascience.com/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9)
- 小さな画像から複数レイヤーの特徴を学習する (PDF)、Alex Krizhevsky、2009 (英語)
- ニューラル・ネットワークにおけるバッチサイズとは? (英語)
- TensorFlow* パフォーマンス・ガイド (https://www.tensorflow.org/performance/performance_guide#optimizing_for_cpu)
- Horovod と TensorFlow* のマルチノードのスケーリングにインテル® Xeon® プラットフォームを使用
https://ai.intel.com/using-intel-xeon-for-multi-node-scaling-of-tensorflow-with-horovod/ - クラスター設計のリファレンス・アーキテクチャー (英語)
- PuTTY* ダウンロード・ページ (英語)
- AI データ・ライフサイクル (英語)
- Conda* ダウンロード・ガイド (英語)
- CentOS* と RHEL 7/6 で Docker* をインストールして基本的なコンテナーについて理解する – パート 1 (英語)
- カスタム Docker* デーモンのオプション (英語)
- TensorFlow* パフォーマンス・ガイド – CPU 向けに最適化 (https://www.tensorflow.org/performance/performance_guide#optimizing_for_cpu)
- AWS* 深層学習 AMI を起動する
- Git ダウンロード・ガイド (英語)
- Ubuntu* 16.04 に Docker* をインストールして使用する方法 (英語)
- インテル® Xeon® プロセッサー・ベースのクラスター上で TensorFlow* を使用したディープラーニングをスケールする最も一般的な手法 (https://ai.intel.com/white-papers/best-known-methods-for-scaling-deep-learning-with-tensorflow-on-intel-xeon-processor-based-clusters/)
- AWS* Deep Learning AMI とは?
- トレーニングと予測の入門ガイド (https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction)
- マシンタイプまたはスケール階層の指定 (https://cloud.google.com/ml-engine/docs/tensorflow/machine-types)
- Thomas W. Malone、MIT (https://cci.mit.edu/malone/)
- TensorFlow* のサンプル (https://cloud.google.com/ml-engine/docs/tensorflow/samples)
- CPU 上で TensorFlow* のパフォーマンスを最大化: 推論ワークロード向けの考察と推奨 (英語)
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
