
この記事は、『The Parallel Universe Magazine 45 号』に掲載されている「OpenMP* Accelerator Offload」の日本語参考訳です。

OpenMP* 標準は、バージョン 4.0 からアクセラレーター・オフロードをサポートしています。これらのプラグマは、エンドユーザーがデータと計算を GPU などのデバイスへオフロードできるようにします。これにより、移植性に優れたヘテロジニアス並列コードを容易に記述できます。この記事では、いくつかの OpenMP* オフロードプラグマと、その使用方法をサンプルコードを用いて説明します。また、OpenACC* から OpenMP* への移行例も紹介します。
OpenACC* から OpenMP* への移行
OpenACC* は、NVIDIA GPU 向けのプラグマベースのプログラミング手法ですが、ほかのベンダーによりサポートされていないため、1 つのプラットフォームに限定されています。一方、OpenMP* オフロードは、oneAPI フレームワーク、NVIDIA の HPC SDK、AMD の ROCm* スタック、IBM の XL コンパイラー・スイートなど、業界で幅広くサポートされています。OpenACC* プラグマは OpenMP* へほぼ 1 対 1 でマッピングできます (表 1)。そのため、通常は既存の OpenACC* コードから OpenMP* へ簡単に移行できます。表 1 は、一般的な OpenACC* プラグマと同等の OpenMP* プラグマです。
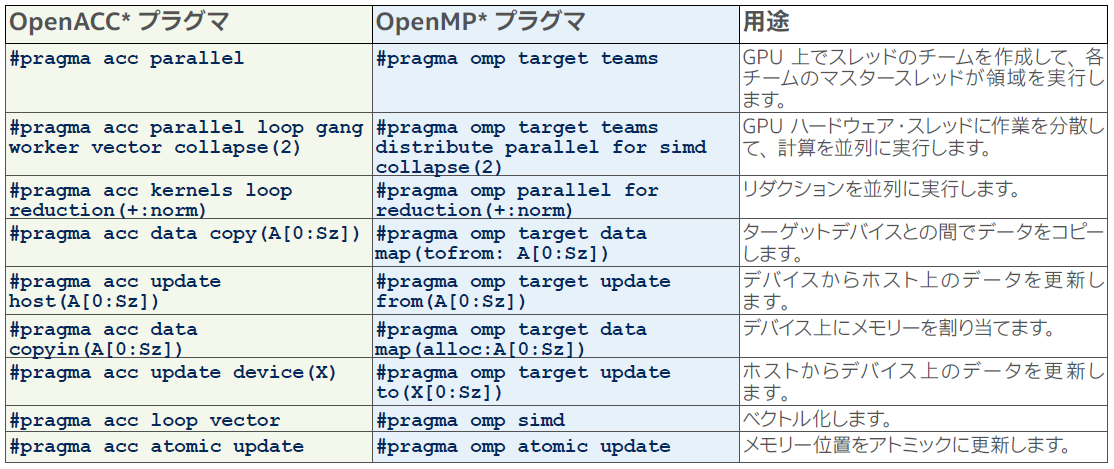
表 1. 一般的な OpenACC* プラグマと同等の OpenMP* プラグマ
図 1a と 1b は、OpenACC* から OpenMP* へ移行されたコードスニペットです。これは、電波天文パッケージ tConvolveACC (英語) のカーネルです。OpenACC* プラグマ #pragma acc parallel loop は、OpenMP* オフロードプラグマ #pragma omp target parallel for とターゲットデバイスとの間の明示的なデータ転送プラグマに置き換えられます。OpenACC* 実装では、暗黙のコピーや統合共有メモリー割り当てを使用してデータ転送を管理している可能性があります。
degridKernelACC(...)
{
...
#pragma acc parallel loop
for (dind = 0; dind < d_size; ++dind) {
...
}
}
...
gridKernelACC(...)
{
...
#pragma acc parallel loop
...
#pragma acc atomic update
gptr_re[0] = gptr_re[0] + cval.real();
...
}
図 1a. OpenACC* で記述された tConvolveACC 実装からのサンプルカーネル
degridKernelOmpOffload(...)
{
...
#pragma omp target parallel for \
map(tofrom:d_data[0:d_size]) \
map(to:d_grid[:grid.size()]) \
map(to:d_C[:C.size()]) ...
for (dind = 0; dind < d_size; ++dind) {
...
}
}
...
gridKernelOmpOffload(...)
{
...
#pragma omp target teams distribute parallel for \
map(tofrom:d_grid[:grid.size()]) ...
...
#pragma omp atomic update
gptr_re[0] = gptr_re[0] + cval.real();
...
}
図 1b. OpenMP* で記述された tConvolveACC 実装からのサンプルカーネル
インテル・プラットフォーム上での OpenMP* オフロード
オフロードコードをビルドして実行するために必要な手順を見てみましょう。インテル® oneAPI ベース・ツールキット 2021.2.0 で以下のコンパイラー・オプションを使用して、OpenMP* オフロードコードをテストします。
-fiopenmp -fopenmp-targets=spir64="-mllvm \ -vpo-paropt-enable-64bit-opencl-atomics=true \ -fp-model=precise"
-fiopenmp と -fopenmp-targets=spir64 の 2 つの新しいオプションは、GPU 向けのファットバイナリーを生成するようにコンパイラーに指示します。-vpo-paropt-enable-64bit-opencl-atomics=true コンパイラー・オプションは、アトミック操作とリダクション操作を有効にします。詳細は、オンライン・ドキュメントを参照してください。
GPU 上で OpenMP* オフロードコードを実行するため、ユーザーは OMP_TARGET_OFFLOAD 環境変数を設定する必要があります (GPU が利用できない場合、ランタイムエラーになります)。また、ユーザーはレベルゼロ (英語) または OpenCL* バックエンドを選択できます。
export OMP_TARGET_OFFLOAD = MANDATORY
export LIBOMPTARGET_PLUGIN = {LEVEL0|OPENCL}
LIBOMPTARGET_DEBUG (英語) 環境変数を 1 以上に設定すると、GPU オフロードのデバッグ情報を取得できます。図 2a では、tConvolveACC の OpenMP* オフロードカーネルをレベルゼロプラグインで実行した場合のデバッグ情報をハイライト表示しています。2 つのオフロード領域は、Benchmark クラスの gridKernelACC 関数と degridKernelACC 関数にあります。図 2b は、map 節でターゲットデバイスへ転送される変数を示します。図 2c は、ホストからターゲットデバイスへ転送されるデータを示します。計算に必要なすべてのデータがデバイスで利用可能になると、図 2a の下部に示すように、カーネルが実行されます。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
