

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Using Intel® Inspector XE 2011 to Find Data Races in Multithreaded Code」の日本語参考訳です。
編集注記:
本記事は、2012 年 2 月 24 日に公開されたものを、加筆・修正したものです。
はじめに
インテル® Inspector は、インテル® Parallel Studio XE のコンポーネントの 1 つで、Windows*/Linux* アプリケーションの正当性エラーの発見に使用します。メモリーエラー、デッドロックまたはデッドロックが発生する可能性のある条件、データ競合、スレッドストールなどを自動的に検出します。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
背景
デバッガーを利用してもランタイム時の再現性の問題から、競合状態が表面化しないことがあるため、マルチスレッド・アプリケーションのデバッグは困難です。PRINT 文でさえも、問題を発見しにくくすることがあります。これは、PRINT 文が、同期およびオペレーティング・システム関数を使用するためです。どのようなスレッドエラーが潜んでいるか、次のコードサンプルについて考えてみましょう。
color col;
static color_t render_one_pixel (
int x,
int y,
unsigned int *local_mbox,
unsigned int &serial,
int startx,
int stopx,
int starty,
int stopy) {
・・・// テンポラリー変数 tcol をここで宣言
col = trace(&primary); // tcol へ書き込み。この領域を並列化すると仮定
・・・// 共有領域の col へこの tcol の内容を追加
R = (int) (col.r * 255);
・・・
}
一般的なスレッドエラーについて詳しく見ていきます。このサンプルコードでは、グローバル変数 col が関数 render_one_pixel で変更されています。複数のスレッドが変数 col へ書き込みを行う場合、col の値はどのスレッドが最後に書き込むかによって決まります。これはデータ競合の典型的な例です。
競合状態を検出するのは困難です。場合によっては、たまたま正しい順序で実行され、競合が発生せずにプログラムが正しく動作することもあるからです。一度正常に実行できたからといって、そのプログラムが常に正常に実行できるとは限りません。ハイパースレッディング・テクノロジーに対応したマシンや複数の物理プロセッサーを搭載したマシンなど、さまざまなマシンでプログラムをテストしてみるのも 1 つの方法ですが、労力を消費するだけでなく、テスト中に必ず問題が再現されるとは限りません。
この場合、インテル® Inspector のようなツールが有効です。従来のデバッガーでは、1 つのスレッドが競合を停止しても、その間にほかのスレッドは処理を継続し、ランタイム動作を著しく変更してデータ競合を見つけにくくしてしまうことがあるため、競合状態の検出には役立ちません。
アドバイス
インテル® Inspector を利用することで、マルチスレッド・アプリケーションのデバッグを効率良く行うことができます。インテル® Inspector は、有益な並列実行情報とデバッグのヒントを提供します。動的なバイナリー・インストルメンテーション機能により、アプリケーションを実行して、コーディング・エラーを識別するため、一般的なスレッド API とすべてのメモリーアクセスをモニターします。
テスト中には発生しないのに、顧客サイトでは常に発生するような再現性が確実でないエラーも検出することができます。このような問題は断続的な不具合と呼ばれ、マルチスレッド・プログラミング固有のものです。インテル® Inspector はこのような厄介な問題も検出し、特定するように設計されています。このツールを使用するときは、データ収集プロセスを高速化するため、最小限のデータですべてのコードパスにアクセスすることが重要です。解析時間を短縮するには、アプリケーションで処理するデータ量を減らすようにソースコードやデータセットを少し変更する必要があるでしょう。
インテル® Inspector で解析を行うには、最適化を無効にし、デバッグシンボルを有効にしてプログラムをコンパイルする必要があります。そして、Windows* の [スタート] メニューからスタンドアロンのインテル® Inspector を起動し、 新しいプロジェクトを作成して、解析対象のアプリケーションとその作業ディレクトリーを指定します。次に、ツールバーにある [New Analysis (新しい解析)] ボタンをクリックし、 [Threading Error Analysis (スレッドエラー解析)] 以下の [Locate Deadlocks and Data Races (デッドロックとデータ競合の特定)] を選択して、[Start (開始)] をクリックします。
[Start (開始)] をクリックすると、インテル® Inspector は、動的なバイナリー・インストルメンテーションを使用して、アプリケーションを実行します。アプリケーションが終了すると、解析結果のサマリーが表示されます。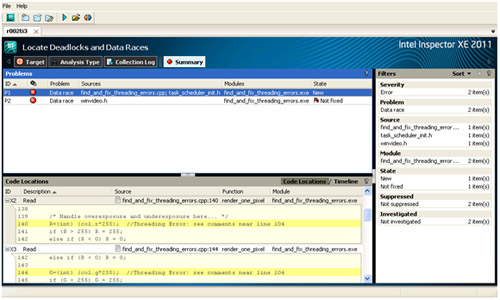
図 1. インテル® Inspector の [Summary (サマリー)] ビュー
問題をより細かく調査できるように、インテル® Inspector には、関連する関数のコールスタックを含む詳細なエラー情報と、フィルタリングや状態管理などの機能があります。ソースコードのクイック・リファレンスにより、エラーが検出されたコード範囲を確認できます。[Summary (サマリー)] リストで問題をダブルクリックして、問題個所のソースを表示します (図 2)。
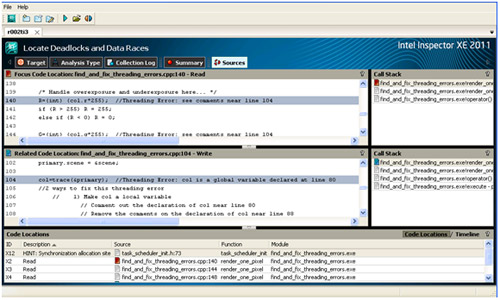
図 2. インテル® Inspector の [Source (ソース)] ビュー
インテル® Inspector でエラーレポートを取得してエラーの原因が判明したら、問題の解決方法を考えます。並列コードでデータ競合状態を回避する一般的な考慮事項と、問題を含むコードの解決方法について以下にアドバイスを示します。
グローバル変数の代わりにローカル変数を使用するようにコードを変更する
このサンプルコードでは、関数の外側で宣言されているグローバル変数 col を、関数内でローカル変数として宣言するように変更します (サンプルコード中のコメントを参照)。各スレッドはグローバルデータを参照する代わりに、その変数の個別のコピーを保持するようになるため、競合はなくなります。これは、この種の問題で推奨される修正方法です。
mutex を使ってグローバルデータを制御する
アルゴリズムの観点からさまざまな理由があり、場合によってはグローバル変数をローカル変数に変更できないことがあります。その場合、通常 mutex を使ってグローバル変数へのアクセスを制御することで、スレッドがそのグローバル変数へ安全にアクセスできるようになります。
このサンプルコードでは、インテル® スレッディング・ビルディング・ブロック (インテル® TBB) を使ってスレッドの生成と管理を行っていますが、インテル® Inspector はその他のスレッド化モデルも多数サポートしています。インテル® TBB は、グローバルデータへのアクセスを制御するために、いくつかの mutex パターンを提供しています。
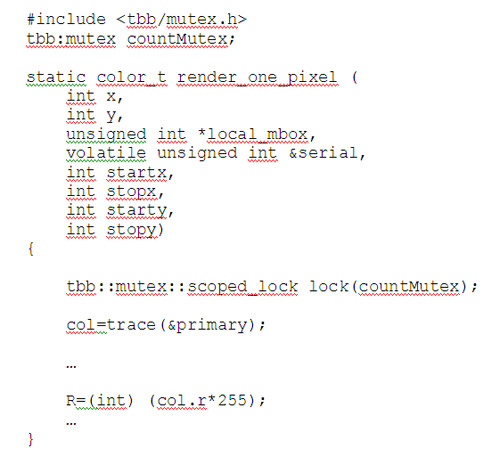
上記のインテル® TBB 版のサンプルコードでは、countMutex が scoped_lock として宣言されています。scoped_lock のセマンティクスは次のとおりです: scoped_lock コンストラクターによりロックが取得され、コードブロックが終了すると scoped_lock のデストラクターにより自動的にロックが解放されます。そのため、常に 1 つのスレッドだけが render_one_pixel() を実行できます。あるスレッドが render_one_pixel() を実行中に別のスレッドが render_one_pixel() を呼び出すと、そのスレッドは scoped_lock に到達した時点で、すでに実行中のスレッドが終了するまで待機します。mutex などの同期はパフォーマンスに影響します。スレッドの待機時間が最小になるように、mutex の範囲はできるだけ小さくすることが重要です。
コンカレント・コンテナーを使ってグローバルデータを制御する
mutex に加えて、インテル® TBB ではグローバルデータへのアクセスを制御するため、いくつかの高度なコンカレント・コンテナー・クラスを提供しています。コンカレント・コンテナーを使用することで、複数のスレッドがコンテナーにアクセスし、安全にデータを更新できるようになります。インテル® TBB のコンテナーは、細粒度のロックとロックフリー (ロックを使用しない) アルゴリズムという 2 つの方法により、高度な並行性を提供します。これらのコンテナーを使用するとオーバーヘッドが増えるため、平行性により得られるスピードアップでオーバーヘッドの増加分を相殺できるかどうかを考慮する必要があります。
利用ガイド
インテル® Inspector は現在、64 ビット版の Microsoft* Windows* 10 上で Microsoft* Visual Studio* 2017/2019 と統合して利用できます。また、64 ビット版の Linux* でも利用可能です。
インテル® Inspector は、静的解析ではなく動的解析を行うことに注意してください。解析は実行されるコードに対してのみ行われます。このため、コード全体をカバーするには、プログラムの異なるコード領域を実行して複数の解析を行う必要があります。
インテル® Inspector のインストルメンテーションはアプリケーションの CPU とメモリー使用量を増加させるため、コンパクトなテスト処理を選択することが非常に重要です。実行時間が数秒のワークロードが最適です。マルチスレッド・コードの該当セクションをテストすることが目的なので、ワークロードが現実的である必要はありません。
