

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Exploiting Data Parallelism in Ordered Data Streams」(https://software.intel.com/content/www/us/en/develop/articles/exploiting-data-parallelism-in-ordered-data-streams.html) の日本語参考訳です。
編集注記:
本記事は、2011 年 5 月 4 日に公開されたものを、加筆・修正したものです。
多くの計算主体のアプリケーションでは、順序付き入力データを順序付き出力データに変換する複雑な処理が行われます。具体的な例としては、オーディオ変換、ビデオ変換、ロスレスデータ圧縮、地震データ解析などがあります。これらの変換で使用されるアルゴリズムの多くは並列性を備えますが、I/O の順序による依存関係の管理にはいくつかの課題があります。この記事は、これらの課題について説明し、並列パフォーマンスを維持しながら課題に取り組む方法を示します。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
ライブビデオ (非圧縮のビデオソース) をリアルタイムに処理してディスクやネットワーク・クライアントに転送するように設計されたビデオ圧縮エンジンのマルチスレッド化を考えます。このようなアプリケーションのリアルタイム処理では、複数のプロセッサーを活用することが有益であることは明らかです。
MPEG2 や MPEG4 のようなビデオ圧縮規格は、信頼性の低いリンク上のストリーミング向けに設計されています。このため、単一のビデオストリームをより小さなスタンドアロン・ストリームのシーケンスとして扱うことが容易です。この場合、小さなストリームを並列に処理することで、大幅なスピードアップを達成できます。マルチスレッド化によって並列処理を行うには、以下のような課題があります。
- 問題のオーバーラップしない部分を定義してスレッドに割り当てる。
- 入力データを正しい順序で一度だけ読み取る。
- 処理が実際に終了した順序に関係なく、大幅にパフォーマンスを低下させることなく正しい順序でブロックを出力する。
- 入力データの実際の範囲について事前知識なしに上記の処理を行う。
ロスレスデータ圧縮のようなケースでは、多くの場合、入力データのサイズをあらかじめ決定して、データを独立した入力ブロックに明示的に分割します。ここで説明する手法は、このケースにも同様に適用できます。
アドバイス
生産と消費のチェーンをセットアップする方法が考えられるかもしれませんが、このアプローチはスケーラブルではなく、ロード・インバランスが発生しやすくなります。代わりに、この記事では、よりスケーラブルなデータ分解を使用して上記の課題に取り組みます。
ここで採用するアプローチは、ビデオのブロックを読み取り、エンコードして、リオーダーバッファーに出力するスレッドのチームを作成します。各ブロックの処理が完了すると、スレッドは次のビデオブロックを読み取って処理します。この動的な割り当てにより、ロード・インバランスを最小限に抑えます。リオーダーバッファーは、完了した順序に関係なく、コード化されたビデオのブロックが正しい順序で書き込まれることを保証します。
オリジナルのビデオ・エンコーディング・アルゴリズムは以下のとおりです。
inFile = OpenFile ()
outFile == InitializeOutputFile ()
WriteHeader (outFile)
outputBuffer = AllocateBuffer (bufferSize)
while (frame = ReadNextFrame (inFile))
{
EncodeFrame (frame, outputBuffer)
if (outputBuffer size > bufferThreshold)
FlushBuffer(outputBuffer, outFile)
}
FlushBuffer (outputBuffer, outFile)
最初に、フレームシーケンスの読み取りとエンコードをブロックベースのアルゴリズムに変更して、スレッドのチームで分解を行うようにコードを設定します。
WriteHeader (outFile)
while (block = ReadNextBlock (inFile))
{
while(frame = ReadNextFrame (block))
{
EncodeFrame (frame, outputBuffer)
if (outputBuffer size > bufferThreshold)
FlushBuffer (outputBuffer, outFile)
}
FlushBuffer (outputBuffer, outFile)
}
データブロックの定義はアプリケーションによって異なりますが、ビデオストリームの場合、最小および最大ブロックサイズの制約により、自然なブロック境界が、シーンの入力で検出される最初のフレームである可能性があります。ブロックベースで処理を行うためには、処理の前にバッファーが設定されるように、入力バッファーの割り当てとソースコードの変更が必要です。また、ファイルではなくバッファーから読み取りを行うように readNextFrame メソッドを変更する必要もあります。
次に、バッファーの出力方法を変更して、ブロック全体が 1 つのユニットとして書き込まれるようにします。ブロックが単に正しい順序で出力されれば良いため、このアプローチは出力のリオーダー処理を単純化します。以下のコードは、出力をブロックベースで行うように変更したものです。
最大ブロックサイズに対応するサイズの出力バッファーが必要です。
各ブロックは独立しているため、各出力ブロックは特別なヘッダーで始まります。MPEG ビデオストリームの場合、このヘッダーはフレーム間予測を行わない基準フレーム (I フレーム) に先行します。 結果的に、ヘッダーはブロックからループ内部へ移動されます。
while (block = ReadNextBlock (inFile))
{
WriteHeader (outputBuffer)
while (frame = ReadNextFrame (block))
{
EncodeFrame (frame, outputBuffer)
}
FlushBuffer (outputBuffer, outFile)
}
これらの変更により、スレッド・ライブラリー (Pthread や Win32* ネイティブスレッディング API) や OpenMP* を使用した並列化が可能になります。
// outputBuffer、block、frame のプライベート・コピー、
// inFile と outFile の共有コピーを含むスレッドチームを生成
while (AcquireLock,
block = ReadNextBlock (inFile),
ReleaseLock, block)
{
WriteHeader (outputBuffer)
while (frame = ReadNextFrame (block))
{
EncodeFrame (frame, outputBuffer)
}
FlushBuffer (outputBuffer, outFile)
}
これは単純ですが、データを安全かつインオーダーで読み取る効果的な手法です。各スレッドはロックされ、データのブロックを読み取った後、リリースされます。入力ファイルの共有により、データブロックが正しい順序で一度だけ読み取られることが保証されます。準備が完了したスレッドは常にロックされるため、ブロックは動的または先着順でスレッドに割り当てられ、通常、ロード・インバランスが最小限に抑えられます。
最後に、ブロックが安全かつ正しい順序で出力されるようにします。簡単な方法は、ロックと共有出力ファイルを使用して一度に 1 つのブロックのみ書き込まれるようにすることでしょう。このアプローチではスレッドセーフであることは保証されますが、オリジナルと異なる順序でブロックが出力される可能性があります。出力をフラッシュする前に以前のすべてのブロックが書き込まれるまでスレッドを待機させることもできますが、スレッドが書き込みを待つ間アイドル状態になるため、効率は悪くなります。
ここでは、出力ブロックの循環リオーダーバッファーを導入するアプローチを考えます。各ブロックに連続した番号を割り当て、バッファーの「末尾」が次のブロックを指すようにします。スレッドは、バッファーの末尾が指していないデータブロックの処理を完了した場合、ブロックを適切なバッファーの位置に入れてから、次の利用可能なブロックの読み取りと処理を行います。
また、バッファーの末尾が指しているブロックの処理を完了した場合、そのブロックとキューに入れられていた連続するブロックを書き込みます。最後に、次に出力するブロックを指すようにバッファーの末尾を更新します。リオーダーバッファーを利用することで、ブロックを順番に書き込むことを保証しながら、完了したブロックをアウトオブオーダーで (順序に関係なく) キューに入れることができます。
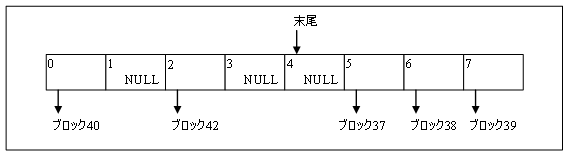
図 1. 書き込み前のリオーダーバッファーの状態。
図 1 は、リオーダーバッファーのある状態を示しています。ブロック 0 から 35 まではすでに処理され書き込まれています。一方、ブロック 37、38、39、40 および 42 は処理され、書き込みのためにキューに入れられています。スレッドがブロック 36 の処理を完了すると、ブロック 36 から 40 までを書き込みます。リオーダーバッファーの状態は図 2 のようになります。ブロック 42 はブロック 41 が完了するまでキューに入れられたままです。
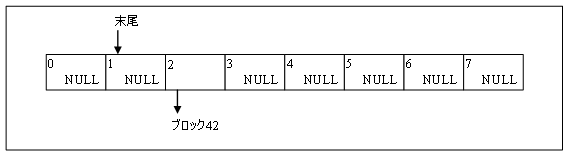
図 2. 書き込み後のリオーダーバッファーの状態。
アルゴリズムが強固で高速に動作するように、以下を行う必要があります。
- データ構造を共有している場合、読み取りまたは書き込みの際にロックする。
- バッファーのスロット数をスレッド数より多くする。
- バッファーの適切なスロットが利用できない場合、スレッドを効率的に待機させる。
- スレッドごとに複数の出力バッファーをあらかじめ割り当てる。バッファーを指すポインターをキューに入れることで、余分なデータコピーやメモリー割り当てが回避できます。
出力キューを使用した最終的なアルゴリズムは以下のようになります。
inFile = OpenFile ()
outFile == InitializeOutputFile ()
// outputBuffer、block、frame のプライベート・コピー、
// inFile と outFile の共有コピーを含むスレッドチームを生成
while (AcquireLock,
block = ReadNextBlock (inFile),
ReleaseLock, block)
{
WriteHeader (outputBuffer)
while (frame = ReadNextFrame (block))
{
EncodeFrame (frame, outputBuffer)
}
QueueOrFlush (outputBuffer, outFile)
}
このアルゴリズムによりインオーダー I/O が可能になりますが、ハイパフォーマンスなアウトオブオーダーの並列処理の柔軟性は保たれたままです。
利用ガイド
場合によっては、データの読み取りと書き込み時間がデータの処理時間よりも長くなることがあります。その場合は、以下の手法を利用します。
- Linux* および Windows* には、読み取りや書き込みを初期化した後、完了まで待機するか、または完了を通知する API が用意されています。ほかの計算を行っている間に、これらのインターフェイスを使用して入力データの「プリフェッチ」や出力データの「ポストライト」を行うことで、I/O レイテンシーを効果的に隠蔽できます。Windows の場合、非同期 I/O でファイルを開くには、FILE_FLAG_OVERLAPPED フラグを指定します。Linux で非同期操作を行うには、libaio の aio_* 関数を使用します。
- 入力データの量が非常に多い場合、静的な分解テクニックを利用すると、ハードウェアで同時に大量の連続していない読み取りが試行され、物理ディスクの「スラッシング」が発生します。上記の共有ファイルおよび動的な先入れ先出しスケジューリング・アルゴリズムの説明に従うことで、インオーダーの連続した読み取りが行われ、I/O サブシステム全体のスループットが向上します。
データブロックのサイズと数を選択するときは十分注意してください。通常、ブロックの数が多いとスケジューリングを柔軟に行えるため、ロード・インバランスを減らすことができます。一方、ブロックの数を非常に少なくすると、不必要なロックによるオーバーヘッドが発生し、データ圧縮アルゴリズムを効率良く利用できません。
関連情報
- OpenMP* 仕様 (英語)
