ImageBind と OpenVINO を使用したマルチモーダル・データのバインド#
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

周囲の世界を探索するとき、人々は、にぎやかな通りを見たり、車のエンジン音を聞いたりするなど、複数の感覚から情報を得ます。ImageBind は、さまざまな形式の情報から同時に、総合的に、直接的に学習する人間の能力にマシンを一歩近づけるアプローチを導入します。ImageBind は、明示的な監視 (生データを整理してラベル付けするプロセス) を必要とせずに、6 つのモダリティーからのデータを一度にバインドできる最初の AI モデルです。この画期的な技術は、画像とビデオ、音声、テキスト、深度、熱、慣性計測装置 (IMU) などのモダリティー間の関係を認識することで、マシンがさまざまな形式の情報をより適切に分析できるようにし、AI の進歩に貢献します。
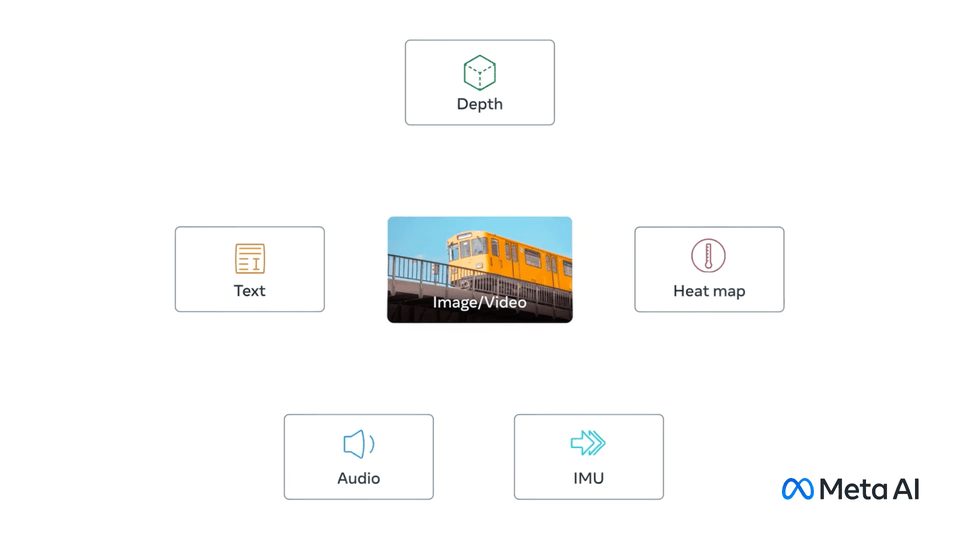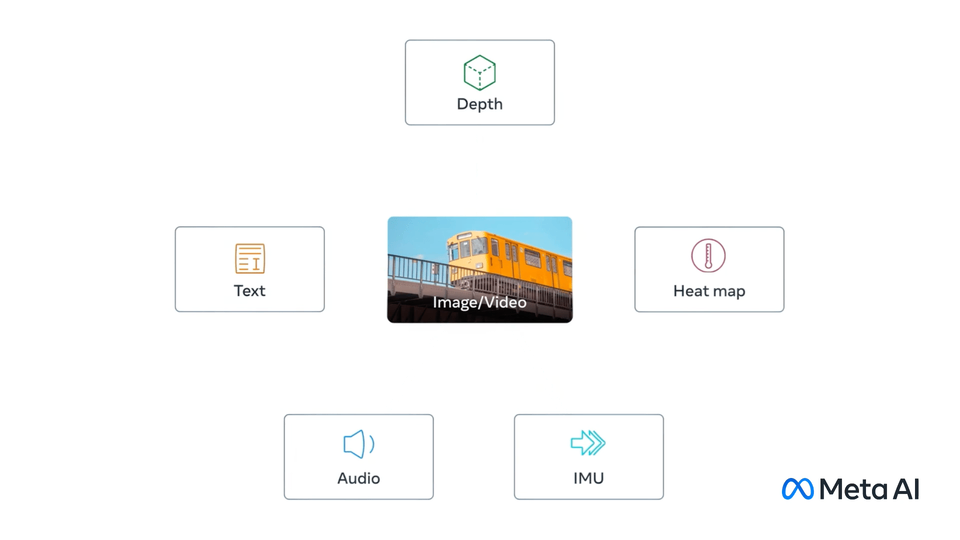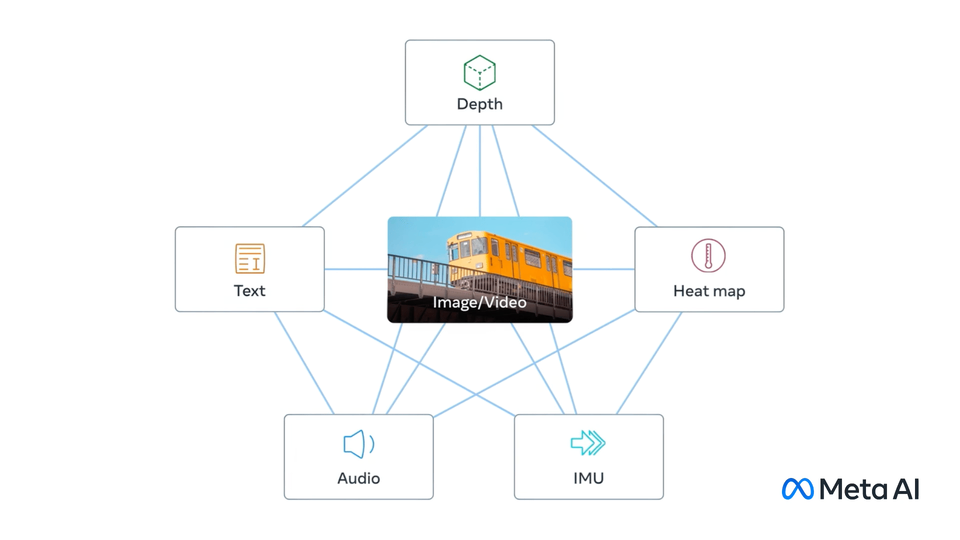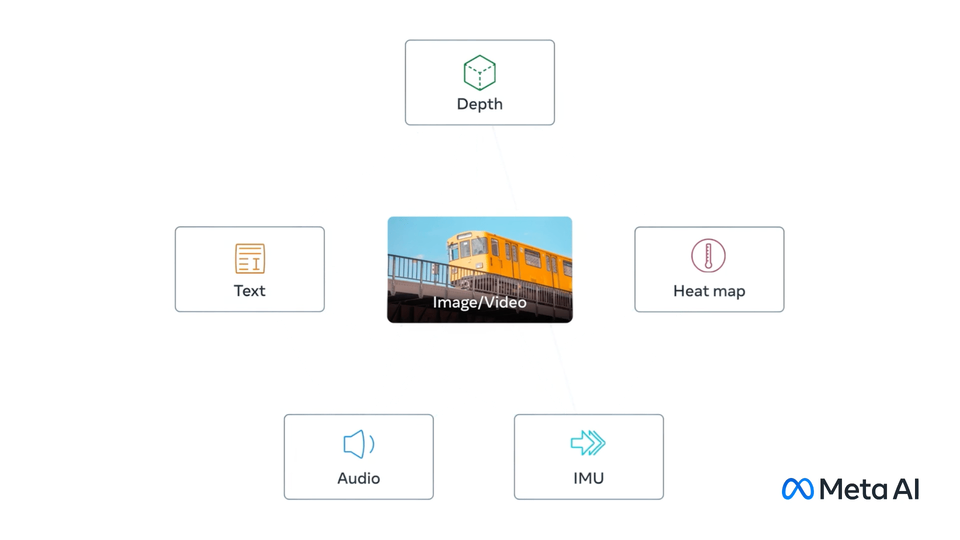
ImageBind#
このチュートリアルでは、OpenVINO を使用して ImageBind モデルを変換して実行する方法について説明します。
このチュートリアルは次のステップで構成されます:
事前トレーニングされたモデルをダウンロードします。
入力データの例を準備します。
モデルを OpenVINO 中間表現形式 (IR) に変換します。
モデル推論を実行し、結果を分析します。
ImageBind について#
2023 年 5 月に Meta Research によってリリースされた ImageBind は、画像とビデオ、テキスト、オーディオ、熱画像、深度、加速度計や方向モニターなどのセンサーを含む IMU の 6 つのモダリティーからのデータを組み合わせる埋め込みモデルです。ImageBind を使用すると、オーディオなどの 1 つのモダリティーでデータを提供して、ビデオや画像などのさまざまなモダリティーで関連するドキュメントを見つけることができます。
ImageBind はデータのペアを使用してトレーニングされました。各ペアは、ビデオを含む画像データを別のモダリティーにマッピングし、結合されたデータを使用して埋め込みモデルをトレーニングしました。ImageBind は、トレーニングに使用した画像データを使用して、さまざまなモダリティーの特徴を学習できることを発見しました。ImageBind からの注目すべき結論は、画像を別のモダリティーとペアリングし、その結果を同じ埋め込み空間で組み合わせるだけで、マルチモーダル埋め込みモデルを作成できることです。モデルの詳細については、モデル・リポジトリー、論文、Meta AI ブログ投稿をご覧ください。
すべての埋め込みモデルと同様に、ImageBind には、情報検索、ゼロショット分類、下流のタスク (画像生成など) の入力として ImageBind 表現によって作成された使用例など、多数の潜在的な使用例があります。下の画像に示されている潜在的な使用例の一部は次のとおりです:
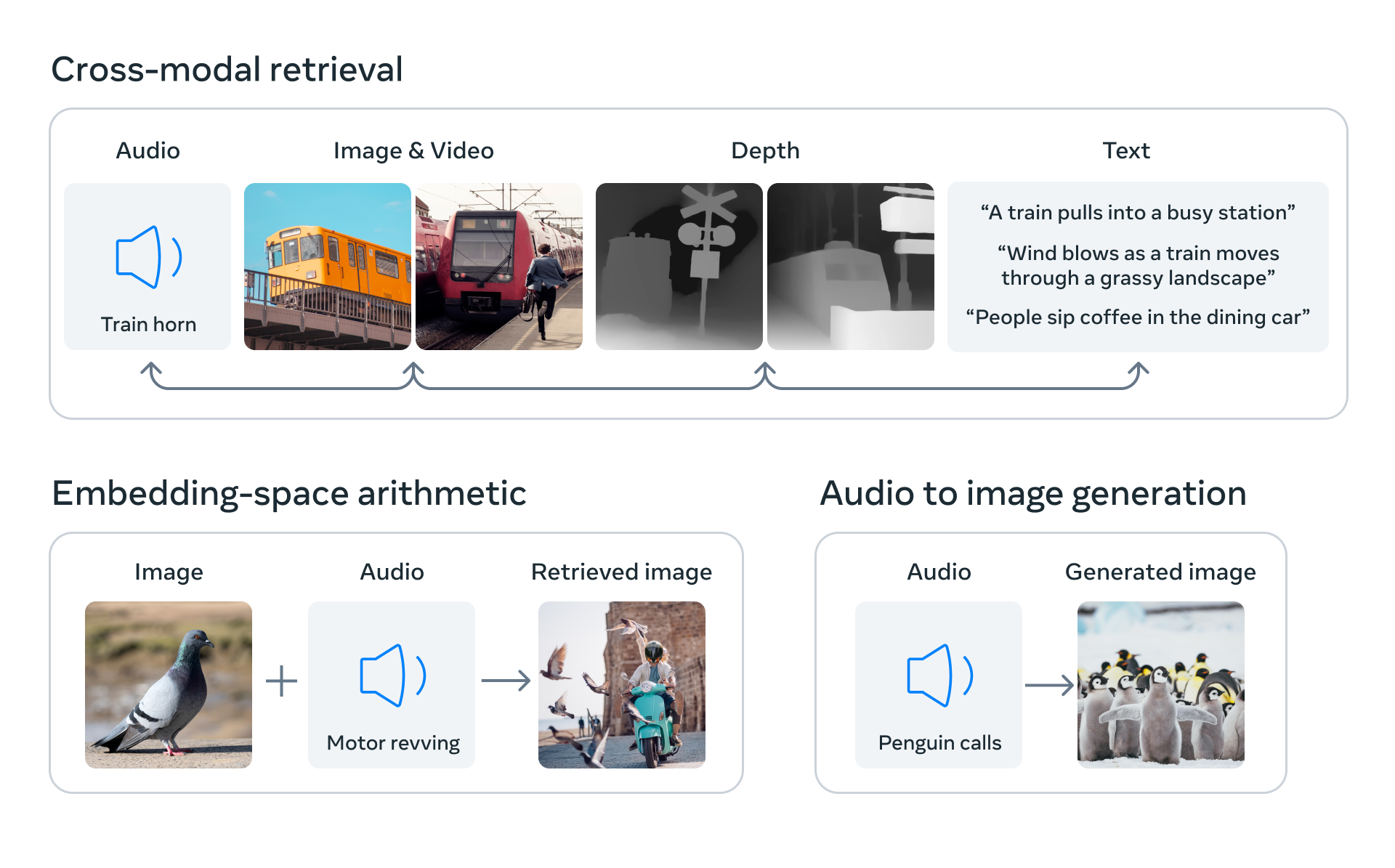
ユースケース#
このチュートリアルでは、マルチモーダル・ゼロショット分類に ImageBind を使用する方法について説明します:
目次:
必要条件#
import platform
%pip install -q "torch>=2.0.1" "torchvision>=0.15.2,<0.17.0" "torchaudio>=2.0.2" --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q datasets regex librosa soundfile pytorchvideo ftfy "timm>=0.6.7" einops fvcore "openvino>=2024.0.0" "nncf>=2.9.0" numpy scipy --extra-index-url https://download.pytorch.org/whl/cpu
if platform.system() != "Windows":
%pip install -q "matplotlib>=3.4"
else:
%pip install -q "matplotlib>=3.4,<3.7"from pathlib import Path
repo_dir = Path("ImageBind")
if not repo_dir.exists():
!git clone https://github.com/facebookresearch/ImageBind.git
%cd {repo_dir}PyTorch モデルをインスタンス化#
モデルでの作業を開始するには、PyTorch モデルクラスをインスタンス化する必要があります。imagebind_model.imagebind_huge(pretrained=True) はモデルの重みをダウンロードし、ImageBind 用の PyTorch モデル・オブジェクトを作成します。現在、ダウンロード可能な ImageBind モデルは imagebind_huge のみです。詳細については、モデルカードをご覧ください。
インターネット接続速度によっては、モデルのダウンロード処理に時間がかかる場合があります。また、モデル・チェックポイントを保存するには、ディスク上に少なくとも 5 GB の空き容量が必要です。
import imagebind.data as data
import torch
from imagebind.models import imagebind_model
from imagebind.models.imagebind_model import ModalityType
# モデルのインスタンス化
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval();/home/ea/work/my_optimum_intel/optimum_env/lib/python3.8/site-packages/torchvision/transforms/functional_tensor.py:5: UserWarning: The torchvision.transforms.functional_tensor module is deprecated in 0.15 and will be removed in 0.17. Please don't rely on it. You probably just need to use APIs in torchvision.transforms.functional or in torchvision.transforms.v2.functional. warnings.warn( /home/ea/work/my_optimum_intel/optimum_env/lib/python3.8/site-packages/torchvision/transforms/_functional_video.py:6: UserWarning: The 'torchvision.transforms._functional_video' module is deprecated since 0.12 and will be removed in the future. Please use the 'torchvision.transforms.functional' module instead. warnings.warn( /home/ea/work/my_optimum_intel/optimum_env/lib/python3.8/site-packages/torchvision/transforms/_transforms_video.py:22: UserWarning: The 'torchvision.transforms._transforms_video' module is deprecated since 0.12 and will be removed in the future. Please use the 'torchvision.transforms' module instead. warnings.warn(
入力データを準備#
ImageBind は 6 つの異なるモダリティーにわたるデータを処理します。それぞれに前処理の手順が必要です。data モジュールは、各モダリティーのデータの読み取りと前処理を担当します。
data.load_and_transform_textは、テキストラベルのリストを受け取り、トークン化します。data.load_and_transform_vision_dataは、入力画像へのパスを受け入れ、それを読み取り、小さい辺サイズ 224 でアスペクト比を保存するようにサイズを変更して、中央の切り取りを実行し、データを [0, 1] 浮動小数点範囲に正規化します。data.load_and_transofrm_audio_dataは、指定されたパスからオーディオファイルを読み取り、サンプルごとに分割し、メル・スペクトログラムを計算します。
# Prepare inputs
text_list = ["A car", "A bird", "A dog"]
image_paths = [
".assets/dog_image.jpg",
".assets/car_image.jpg",
".assets/bird_image.jpg",
]
audio_paths = [
".assets/dog_audio.wav",
".assets/bird_audio.wav",
".assets/car_audio.wav",
]
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, "cpu"),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, "cpu"),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, "cpu"),
}モデルを OpenVINO 中間表現 (IR) 形式に変換#
OpenVINO は、モデル・トランスフォーメーション API を通じて PyTorch をサポートします。モデルを IR 形式に変換するには、モデル変換 Python API を使用します。ov.convert_model 関数は、デバイスにロードする準備が整った OpenVINO モデル・クラス・インスタンスを返すか、ov.save_model を使用して次回ロードするためにディスクに保存します。
ImageBind は、さまざまなモダリティーを同時に任意の組み合わせで表すデータを受け入れますが、それらの処理は互いに独立しています。データの受け渡しの柔軟性が失われないよう、各モダリティー・エンコーダーを独立したモデルとしてエクスポートします。以下のコードは、単一モダリティーの埋め込みのみを取得するためのモデルのラッパーを定義します。
class ModelExporter(torch.nn.Module):
def __init__(self, model, modality):
super().__init__()
self.model = model
self.modality = modality
def forward(self, data):
return self.model({self.modality: data})import openvino as ov
core = ov.Core()推論デバイスの選択#
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
deviceDropdown(description='Device:', index=3, options=('CPU', 'GPU.0', 'GPU.1', 'AUTO'), value='AUTO')ov_modality_models = {}
modalities = [ModalityType.TEXT, ModalityType.VISION, ModalityType.AUDIO]
for modality in modalities:
export_dir = Path(f"image-bind-{modality}")
file_name = f"image-bind-{modality}"
export_dir.mkdir(exist_ok=True)
ir_path = export_dir / f"{file_name}.xml"
if not ir_path.exists():
exportable_model = ModelExporter(model, modality)
model_input = inputs[modality]
ov_model = ov.convert_model(exportable_model, example_input=model_input)
ov.save_model(ov_model, ir_path)
else:
ov_model = core.read_model(ir_path)
ov_modality_models[modality] = core.compile_model(ov_model, device.value)ImageBind と OpenVINO を使用したゼロショット分類#
ゼロショット分類では、データの一部が埋め込まれ、モデルに入力されて、データの内容に対応するラベルが取得されます。ImageBind では、音声、画像、その他のサポートされているモダリティーの情報を分類できます。CLIP モデルを使用してゼロショット画像分類を実行する方法についてはすでに説明しました (詳細についてはこのノートブックを確認してください)。ImageBind では、サポートされているモダリティーの任意の組み合わせを分類に使用できるため、このタスクに対する ImageBind の機能はより広範囲にわたります。
ImageBind を使用してゼロショット分類を実行するには、次の手順を実行する必要があります:
要求されたモダリティーのデータバッチを前処理します (この場合、1 つのモダリティーはデータソースとして扱われ、他のモダリティーはラベルとして扱われます)。
各モダリティーの埋め込みを計算します。
埋め込みベクトル間のドット積を求めて確率行列を取得します。
ソースをラベル空間にマッピングするため最も高い確率を持つラベルを取得します。
前のステップですでにデータを前処理したので、埋め込みを取得するためにモデル推論を実行する必要があります。
embeddings = {}
for modality in modalities:
embeddings[modality] = ov_modality_models[modality](inputs[modality])
[ov_modality_models[modality].output(0)]確率行列は、ソース埋め込みとラベル埋め込みの対応を示します。これは 2D 行列であり、x 次元はラベル・モダリティー・データを表し、y 次元はソース・モダリティー・データを表します。これは埋め込みベクトル間のドット積として計算でき、softmax を使用して [0,1] の範囲に正規化できます。次に、x ラベルと y ラベルの交差部分のスコアが高くなると、それらが同じオブジェクトを表す信頼性が高くなります。
import matplotlib.pyplot as plt
import numpy as np
from scipy.special import softmax
def visualize_prob_matrix(matrix, x_label, y_label):
fig, ax = plt.subplots()
ax.matshow(matrix, cmap="winter")
for (i, j), z in np.ndenumerate(matrix):
ax.text(j, i, "{:0.3f}".format(z), ha="center", va="center")
ax.set_xticks(range(len(x_label)), x_label)
ax.set_yticks(range(len(y_label)), y_label)
image_list = [img.split("/")[-1] for img in image_paths]
audio_list = [audio.split("/")[-1] for audio in audio_paths]テキスト画像分類#
text_vision_scores = softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, axis=-1)
visualize_prob_matrix(text_vision_scores, text_list, image_list)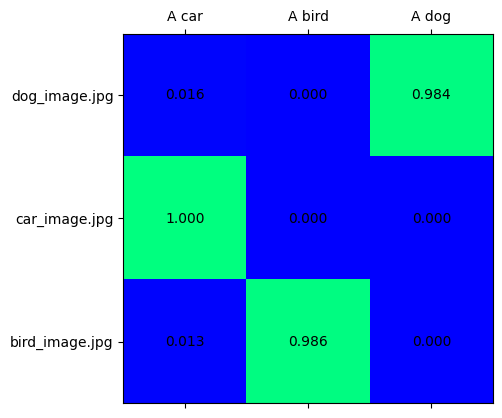
テキスト音声分類#
text_audio_scores = softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, axis=-1)
visualize_prob_matrix(text_audio_scores, text_list, audio_list)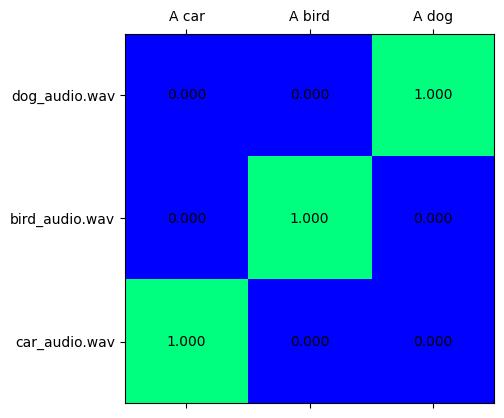
画像音声の分類#
audio_vision_scores = softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, axis=-1)
visualize_prob_matrix(audio_vision_scores, image_list, audio_list)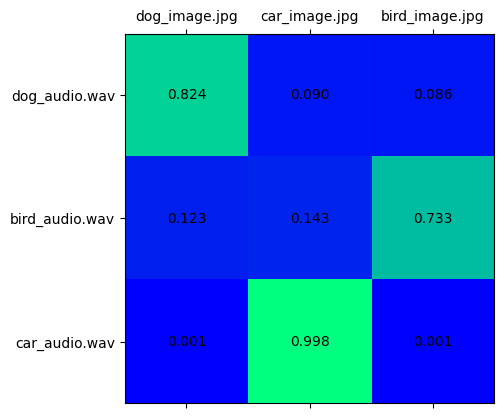
これらすべてを組み合わせることで、データのテキスト、画像、音声を一致させることができます。
import IPython.display as ipd
from PIL import Image
text_image_ids = np.argmax(text_vision_scores, axis=0)
text_audio_ids = np.argmax(text_audio_scores, axis=0)
print(
f"Predicted label: {text_list[0]} \nprobability for image - {text_vision_scores[text_image_ids[0], 0]:.3f}\nprobability for audio - {text_audio_scores[0, text_audio_ids[0]]:.3f}"
)
display(Image.open(image_paths[text_image_ids[0]]))
ipd.Audio(audio_paths[text_audio_ids[0]])Predicted label: A car
probability for image - 1.000
probability for audio - 1.000
print(
f"Predicted label: {text_list[1]} \nprobability for image - {text_vision_scores[text_image_ids[1], 1]:.3f}\nprobability for audio - {text_audio_scores[1, text_audio_ids[1]]:.3f}"
)
display(Image.open(image_paths[text_image_ids[1]]))
ipd.Audio(audio_paths[text_audio_ids[1]])Predicted label: A bird
probability for image - 0.986
probability for audio - 1.000
print(
f"Predicted label: {text_list[2]} \nprobability for image - {text_vision_scores[text_image_ids[2], 2]:.3f}\nprobability for audio - {text_audio_scores[2, text_audio_ids[2]]:.3f}"
)
display(Image.open(image_paths[text_image_ids[2]]))
ipd.Audio(audio_paths[text_audio_ids[2]])Predicted label: A dog
probability for image - 0.984
probability for audio - 1.000
NNCF を使用した ImageBind モデルのトレーニング後の量子化#
このチュートリアルは、NNCF(Neural Network Compression Framework) から 8 ビットのトレーニング後の量子化を適用してモデルを高速化し、OpenVINO™ ツールキットを介して量子化されたモデルを推論する方法を示します。
最適化プロセスには次の手順が含まれます。
- 量子化データセット 2 を準備します。
- NNCF を使用して OpenVINO モデルを量子化します。
- 入力データの例について、変換されたモデルと量子化されたモデルの間で確率行列を比較します。
- 変換および量子化されたモデルのモデルサイズを比較します。
- 変換および量子化されたモデルのパフォーマンスを比較します。
modalities = [ModalityType.TEXT, ModalityType.VISION, ModalityType.AUDIO]
fp_model_paths = {modality: Path(f"image-bind-{modality}") / f"image-bind-{modality}.xml" for modality in modalities}
int8_model_paths = {modality: Path(f"image-bind-{modality}") / f"image-bind-{modality}_int8.xml" for modality in modalities}データセットの準備#
Conceptual Captions データセットは、キャプションの注釈が付けられた約 330 万枚の画像で構成されています。データセットは、画像およびテキストモデルを量子化するために使用されます。
import imagebind.data as data
import os
import requests
import tempfile
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
def check_text_data(data):
"""
Check if the given data is text-based.
"""
if isinstance(data, str):
return True
if isinstance(data, list):
return all(isinstance(x, str) for x in data)
return False
def collate_fn(examples, image_column="image_url", text_column="caption"):
"""
Collates examples into a batch for processing.
Preprocesses each example by loading and transforming image and text data.
Checks if the text data in the example is valid by calling the `check_text_data` function.
Downloads the image specified by the URL in the image_column of the example dictionary.
Constructs and returns a dictionary representing the collated batch with the following keys:
- "pixel_values": The pixel values of the preprocessed example.
- "input_ids": The transformed text data of the preprocessed example.
"""
assert len(examples) == 1
example = examples[0]
if not check_text_data(example[text_column]):
raise ValueError("Text data is not valid")
url = example[image_column]
with tempfile.TemporaryDirectory() as tempdir:
f_name = os.path.join(tempdir, "image.jpg")
try:
response = requests.get(url, verify=False, timeout=20)
with open(f_name, "wb") as file:
file.write(response.content)
pixel_values = data.load_and_transform_vision_data([f_name], "cpu")
except Exception:
print(f"Can't load image from url: {url}")
return None
text = data.load_and_transform_text([example[text_column]], "cpu")
return {"pixel_values": pixel_values, "input_ids": text}from datasets import load_dataset
import itertools
import torch
from tqdm.notebook import tqdm
def collect_vision_text_data(dataloader, init_steps):
"""
This function collects vision and text data from a dataloader for a specified number of initialization steps.
It iterates over the dataloader, fetching batches and storing the relevant vision and text data.
Returns a tuple containing the collected vision_data and text_data lists.
"""
text_data = []
vision_data = []
print(f"Fetching {init_steps} for the initialization...")
counter = 0
for batch in tqdm(dataloader):
if counter == init_steps:
break
with torch.no_grad():
if batch:
counter += 1
text_data.append(batch["input_ids"].to("cpu"))
vision_data.append(batch["pixel_values"].to("cpu"))
return vision_data, text_data
def prepare_vision_text_dataset(opt_init_steps=50):
"""
Prepares a vision-text dataset for quantization by collecting vision and text data.
"""
dataset = load_dataset("google-research-datasets/conceptual_captions", streaming=False, trust_remote_code=True)
train_dataset = dataset["train"].shuffle(seed=0) dataloader = torch.utils.data.DataLoader(train_dataset, collate_fn=collate_fn, batch_size=1)
vision_data, text_data = collect_vision_text_data(dataloader, opt_init_steps)
return vision_data, text_dataESC-50 データセットは、ImageBind モデルのオーディオ・モダリティーを量子化するために使用されます。データセットは、環境音分類のベンチマーク方法に適した 2000 件の環境音声録音のラベル付きコレクションです。データセットは、50 のセマンティック・クラスに編成された 5 秒間の録音で構成されています。
import numpy as np
import torchaudio
def collect_audio_data(dataloader, init_steps=300):
"""
This function collects audio data from a dataloader for a specified number of initialization steps.
It iterates over the dataloader, fetching batches and storing them in a list.
"""
audio_data = []
for _, batch in tqdm(zip(range(init_steps), itertools.islice(dataloader, 0, init_steps))):
with torch.no_grad():
audio_data.append(batch)
return audio_data
def prepare_audio_dataset():
"""
Prepares an "ashraq/esc50" audio dataset for quantization by collecting audio data.
Collects audio data from the dataloader by calling the `collect_audio_data` function.
Returns a list containing the collected calibration audio data batches.
"""
audio_dataset = load_dataset("ashraq/esc50", streaming=True, trust_remote_code=True)
train_dataset = audio_dataset["train"].shuffle(seed=42, buffer_size=1000)
def collate_fn(examples):
assert len(examples) == 1
with tempfile.TemporaryDirectory() as tempdir:
f_name = os.path.join(tempdir, "audio.wav")
audio_data = examples[0]["audio"]["array"]
sample_rate = examples[0]["audio"]["sampling_rate"]
audio_data = torch.from_numpy(audio_data).to(torch.float32).unsqueeze(0)
torchaudio.save(f_name, audio_data, sample_rate)
return data.load_and_transform_audio_data([f_name], "cpu")
dataloader = torch.utils.data.DataLoader(train_dataset, collate_fn=collate_fn, batch_size=1)
calibration_data = collect_audio_data(dataloader)
return calibration_datavision_data, text_data = [], []
if not int8_model_paths[ModalityType.TEXT].exists() or not int8_model_paths[ModalityType.VISION].exists():
vision_data, text_data = prepare_vision_text_dataset()量子化を適用#
import logging
import nncf
import openvino as ov
nncf.set_log_level(logging.ERROR)
core = ov.Core()
def quantize_openvino_model(modality, calibration_data):
model_path = fp_model_paths[modality]
model = core.read_model(model_path)
quantized_model = nncf.quantize(
model=model,
calibration_dataset=calibration_data,
model_type=nncf.ModelType.TRANSFORMER,
)
ov.save_model(quantized_model, int8_model_paths[modality])
return quantized_modelINFO:nncf:NNCF initialized successfully.Supported frameworks detected: torch, tensorflow, onnx, openvino視覚モダリティー用の ImageBind モデルを量子化#
注: 量子化は時間とメモリーを消費する操作です。以下の量子化コードを実行すると、時間がかかる場合があります。
if not int8_model_paths[ModalityType.VISION].exists():
if len(vision_data) == 0:
raise RuntimeError("Calibration dataset is empty.Please check internet connection and try to download images manually from the URLs above.")
vision_dataset = nncf.Dataset(vision_data)
vision_quantized_model = quantize_openvino_model(modality=ModalityType.VISION, calibration_data=vision_dataset)テキスト・モダリティー用の ImageBind モデルを量子化#
if not int8_model_paths[ModalityType.TEXT].exists():
text_dataset = nncf.Dataset(text_data)
text_quantized_model = quantize_openvino_model(modality=ModalityType.TEXT, calibration_data=text_dataset)オーディオ・モダリティー用の ImageBind モデルを量子化#
if not int8_model_paths[ModalityType.AUDIO].exists():
audio_calibration_data = prepare_audio_dataset()
audio_dataset = nncf.Dataset(audio_calibration_data)
audio_quantized_model = quantize_openvino_model(modality=ModalityType.AUDIO, calibration_data=audio_dataset)NNCF は、量子化対応トレーニングや量子化以外のアルゴリズムもサポートしています。詳細については、NNCF リポジトリーの NNCF ドキュメントを参照してください。
OpenVINO FP16 モデルと量子化モデルの結果を比較#
FP16 と INT8 モデルの確率行列を比較します。
# 入力を準備
text_list = ["A car", "A bird", "A dog"]
image_paths = [
".assets/dog_image.jpg",
".assets/car_image.jpg",
".assets/bird_image.jpg",
]
audio_paths = [
".assets/dog_audio.wav",
".assets/bird_audio.wav",
".assets/car_audio.wav",
]
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, "cpu"),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, "cpu"),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, "cpu"),
}推論デバイスの選択#
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します
deviceDropdown(description='Device:', index=3, options=('CPU', 'GPU.0', 'GPU.1', 'AUTO'), value='AUTO')embeddings = {}
for modality in modalities:
ov_model = core.compile_model(fp_model_paths[modality], device.value)
embeddings[modality] = ov_model(inputs[modality])[0]
quantized_embeddings = {}
for modality in modalities:
model = core.compile_model(int8_model_paths[modality], device.value)
quantized_embeddings[modality] = model(inputs[modality])[0]def visualize_prob_matrices(fp_matrix, int_matrix, x_label, y_label):
fig, ax = plt.subplots(1, 2)
for i, matrix in enumerate([fp_matrix, int_matrix]):
ax[i].matshow(matrix, cmap="winter")
for (k, j), z in np.ndenumerate(matrix):
ax[i].title.set_text("FP16 probs" if i == 0 else "INT8 probs")
ax[i].text(j, k, "{:0.3f}".format(z), ha="center", va="center")
ax[i].set_xticks(range(len(x_label)), x_label)
ax[i].set_yticks(range(len(y_label)), y_label)
fig.tight_layout()
image_list = [img.split("/")[-1] for img in image_paths]
audio_list = [audio.split("/")[-1] for audio in audio_paths]fp_text_vision_scores = softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, axis=-1)
int_text_vision_scores = softmax(
quantized_embeddings[ModalityType.VISION] @ quantized_embeddings[ModalityType.TEXT].T,
axis=-1,
)
visualize_prob_matrices(fp_text_vision_scores, int_text_vision_scores, text_list, image_list)
fp_text_audio_scores = softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, axis=-1)
int_text_audio_scores = softmax(
quantized_embeddings[ModalityType.AUDIO] @ quantized_embeddings[ModalityType.TEXT].T,
axis=-1,
)
visualize_prob_matrices(fp_text_audio_scores, int_text_audio_scores, text_list, image_list)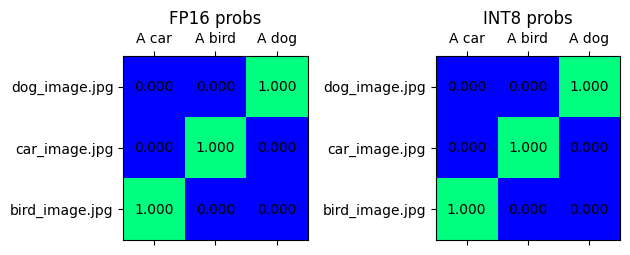
fp_audio_vision_scores = softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, axis=-1)
int_audio_vision_scores = softmax(
quantized_embeddings[ModalityType.VISION] @ quantized_embeddings[ModalityType.AUDIO].T,
axis=-1,
)
visualize_prob_matrices(fp_audio_vision_scores, int_audio_vision_scores, text_list, image_list)
ファイルサイズの比較#
def calculate_compression_rate(modality):
fp16_ir_model_size = Path(fp_model_paths[modality]).with_suffix(".bin").stat().st_size / 1024
quantized_model_size = Path(int8_model_paths[modality]).with_suffix(".bin").stat().st_size / 1024
print(f"Modality: {modality}")
print(f" * FP16 IR model size: {fp16_ir_model_size:.2f} KB")
print(f" * INT8 model size: {quantized_model_size:.2f} KB")
print(f" * Model compression rate: {fp16_ir_model_size / quantized_model_size:.3f}")
for modality in modalities:
calculate_compression_rate(modality)Modality: text
* FP16 IR model size: 691481.69 KB
* INT8 model size: 347006.66 KB
* Model compression rate: 1.993
Modality: vision
* FP16 IR model size: 1235995.15 KB
* INT8 model size: 620132.79 KB
* Model compression rate: 1.993
Modality: audio
* FP16 IR model size: 168429.15 KB
* INT8 model size: 84818.40 KB
* Model compression rate: 1.986FP16 IR と量子化モデルの推論時間を比較#
FP16 と INT8 モデルの推論パフォーマンスを測定するには、キャリブレーション・データセットの推論時間の中央値を使用します。したがって、動的量子化モデルの速度向上を見積もることができます。
注: 最も正確なパフォーマンス推定を行うには、他のアプリケーションを閉じた後、ターミナル/コマンドプロンプトで
benchmark_appを実行することを推奨します。
import time
def calculate_inference_time(model_path, calibration_data):
model = core.compile_model(model_path)
output_layer = model.output(0)
inference_time = []
for batch in calibration_data:
start = time.perf_counter()
_ = model(batch)[output_layer]
end = time.perf_counter()
delta = end - start
inference_time.append(delta)
return np.median(inference_time)ビジョンモデル#
fp16_latency = calculate_inference_time(fp_model_paths[ModalityType.VISION], vision_data)
int8_latency = calculate_inference_time(int8_model_paths[ModalityType.VISION], vision_data)
print(f"Performance speed up: {fp16_latency / int8_latency:.3f}")Performance speed up: 2.375テキストモデル#
fp16_latency = calculate_inference_time(fp_model_paths[ModalityType.TEXT], text_data)
int8_latency = calculate_inference_time(int8_model_paths[ModalityType.TEXT], text_data)
print(f"Performance speed up: {fp16_latency / int8_latency:.3f}")Performance speed up: 1.492オーディオモデル#
fp16_latency = calculate_inference_time(fp_model_paths[ModalityType.AUDIO], audio_calibration_data)
int8_latency = calculate_inference_time(int8_model_paths[ModalityType.AUDIO], audio_calibration_data)
print(f"Performance speed up: {fp16_latency / int8_latency:.3f}")Performance speed up: 5.770