GPU オフロードの手順
プログラムを GPU にオフロードすると、デフォルトでレベルゼロのランタイムが利用されます。OpenCL* ランタイムに切り替えるオプションも用意されています。SYCL* および OpenMP* オフロードでは、各ワーク項目は SIMD レーンにマップされます。サブグループは並列に実行されるワーク項目で形成される SIMD 幅に分割され、サブグループは GPU の EU スレッドにマップされます。ローカルデータを同期または共有するワーク項目を含むワークグループは、計算ユニット (ストリーミング・マルチプロセッサーまたは Xe コア – サブスライスとも呼ばれます) での実行に割り当てられます。最後に、ワーク項目のグローバル ND-Range 全体が GPU 全体にマップされます。
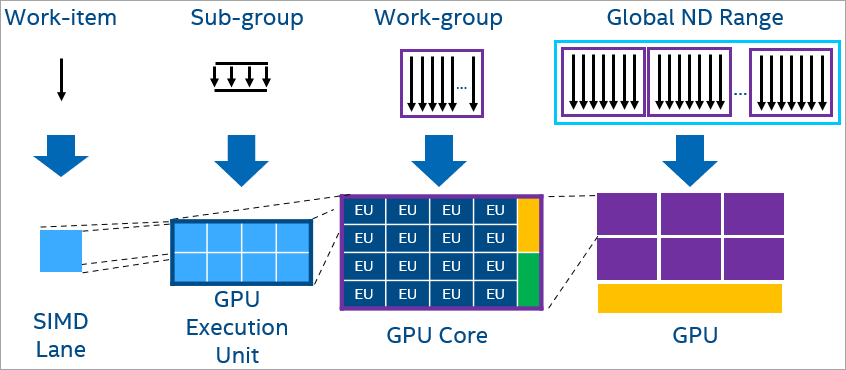
図. 11 PRG インターフェイスの PRG ワークグループ
GPU 実行の詳細については、「各種 oneAPI 計算ワークロードに対する CPU、GPU、および FPGA の利点の比較」(英語)を参照してください。
インテル® Iris® Xe GPU アーキテクチャーの詳細については、『GPU 最適化ガイド』(PDF) を参照してください。
GPU オフロード向けの設定
setvars または oneapi-vars スクリプトの実行を含む、oneAPI 開発環境の設定セクションのすべての手順を実行したことを確認します。
ドライバーをインストールして GPU システムを構成し、ユーザーを video グループに追加します。詳細については、「導入ガイド」を参照ください:
sycl-ls コマンドを使用して、サポートされている GPU と必要なドライバーがインストールされていることを確認します。次の例では、OpenCL* およびレベルゼロのドライバーがインストールされている場合、GPU に関連付けられたランタイムごとに 2 つのエントリーが表示されています:
CPU : OpenCL 2.1 (Build 0)[ 2020.11.12.0.14_160000 ] GPU : OpenCL 3.0 NEO [ 21.33.20678 ] GPU : 1.1[ 1.2.20939 ]
次のサンプルコードを使用して、コードが GPU で実行されていることを確認します。サンプルコードは、整数の大きなベクトルにスカラーを加算し、結果を検証します。
SYCL*
SYCL* では GPU で実行するための組込みデバイスセレクターが用意されています。これは、device_selector 基本クラスを使用し、gpu_selector で GPU デバイスを選択できます。独自のカスタムセレクターを作成することもできます。詳細については、『Data Parallel C++』書籍の「Choosing Devices (デバイスの選択)」 (英語) を参照してください。
SYCL* サンプルコード:
#include <CL/sycl.hpp>
#include <array>
#include <iostream>
using namespace sycl;
using namespace std;
constexpr size_t array_size = 10000;
int main(){
constexpr int value = 100000;
try{
//
// デフォルトのデバイスセレクターは、最もパフォーマンスの高いデバイスを選択
default_selector d_selector;
queue q(d_selector);
// USM を使用して共有メモリーを割り当て
int *sequential = malloc_shared<int>(array_size, q);
int *parallel = malloc_shared<int>(array_size, q);
// シーケンシャル iota
for (size_t i = 0; i < array_size; i++) sequential[i] = value + i;
// SYCL の並列 iota
auto e = q.parallel_for(range{array_size}, [=](auto i) { parallel[i] = value + i; });
e.wait();
// 2 つの結果が等しいことを確認
for (size_t i = 0; i < array_size; i++) {
if (parallel[i] != sequential[i]) {
cout << "Failed on device.\n";
return -1;
}
}
free(sequential, q);
free(parallel, q);
}catch (std::exception const &e) {
cout << "An exception is caught while computing on device.\n";
terminate();
}
cout << "Successfully completed on device.\n";
return 0;
}次のコマンドでサンプルコードをコンパイルします:
icpx -fsycl simple-iota-dp.cpp -o simple-iota生成したバイナリーを実行します:
./simple-iota
Running on device: Intel® UHD Graphics 630 [0x3e92]
Successfully completed on device.OpenMP*
OpenMP* のサンプルコード:
#include <stdlib.h>
#include <omp.h>
#include <iostream>
constexpr size_t array_size = 10000;
#pragma omp requires unified_shared_memory
int main(){
constexpr int value = 100000;
// デフォルトのターゲットデバイスを返します
int deviceId = (omp_get_num_devices() > 0) ? omp_get_default_device() : omp_get_initial_device();
int *sequential = (int *)omp_target_alloc_host(array_size, deviceId);
int *parallel = (int *)omp_target_alloc(array_size, deviceId);
for (size_t i = 0; i < array_size; i++)
sequential[i] = value + i;
#pragma omp target parallel for
for (size_t i = 0; i < array_size; i++)
parallel[i] = value + i;
for (size_t i = 0; i < array_size; i++) {
if (parallel[i] != sequential[i]) {
std::cout << "Failed on device.\n";
return -1;
}
}
omp_target_free(sequential, deviceId);
omp_target_free(parallel, deviceId);
std::cout << "Successfully completed on device.\n";
return 0;
}次のコマンドでサンプルコードをコンパイルします:
icpx -fsyclsimple-iota-omp.cpp -fiopenmp -fopenmp-targets=spir64 -o simple-iota生成したバイナリーを実行します:
./simple-iota Successfully completed on device.注
オフロード領域が存在し、アクセラレーターがない場合、OMP_TARGET_OFFLOAD=mandatory 環境変数が指定されない限り、カーネルは従来のホストコンパイル(OpenCL* ランタイムなし)にフォールバックします。
GPU へコードをオフロード
どの GPU ハードウェアで、どのコード領域をオフロードするか決定するには、「GPU 最適化ワークフロー・ガイド」(英語)を参照してください。
オフロードするコード領域を特定するには、インテル® Advisor のオフロードのモデル化 (英語) が役立ちます。
GPU コードのデバッグ
以下のリストには、オフロードされるコードの基本的なデバッグのヒントが示されています。
CPU またはホスト/ターゲットをチェック、またはランタイムを OpenCL* に切り替えてコードが正しいことを確認します。
printf を使用して、アプリケーションをデバッグします。SYCL* と OpenMP* オフロードでは、どちらもカーネルコードで printf がサポートされます。
環境変数を設定して詳細なログ情報を取得します。
SYCL では、次のデバッグ環境変数を利用できます。すべての変数については GitHub をご覧ください。
名前 |
値 |
説明 |
|---|---|---|
|
|
|
|
1|2|-1 |
1: SYCL* ランタイムプラグインの基本トレースログを出力します 2: SYCL* ランタイムプラグインのすべてのAPI トレースを出力します -1: "2" のすべてと追加のデバッグ情報を出力します |
|
任意の値で定義された変数 (有効) |
この環境変数は、DPC++ ランタイムが使用された際にレベルゼロ・バックエンドからのデバッグ出力を有効にします。以下が報告されます: * レベルゼロ API の呼び出し * レベルゼロのイベント情報 |
OpenMP* では、次のデバッグ環境変数が推奨されます。利用可能なすべての環境変数については、「LLVM/OpenMP* ドキュメント」 (英語) を参照してください。
名前 |
値 |
説明 |
|---|---|---|
|
cpu | gpu |
Select |
|
1 |
詳細なデバッグ情報を出力します |
|
LLVM/OpenMP* のドキュメント (英語) で利用可能な値 |
ユーザーが |
事前 (AOT) コンパイルを使用して、ジャストインタイム (JIT) コンパイルを AOT コンパイルに移行します。
CL_OUT_OF_RESOURCES エラー
CL_OUT_OF_RESOURCES エラーは、エミュレーターがデフォルトでサポートする __private メモリー、もしくは __local メモリーよりも多くのメモリーをカーネルが使用すると発生する可能性があります。
このエラーが発生すると、次のようなメッセージが表示されます。
$ ./myapp :
Problem size: c(150,600) = a(150,300) * b(300,600)
terminate called after throwing an instance of 'cl::sycl::runtime_error’
what(): Native API failed.Native API returns: -5 (CL_OUT_OF_RESOURCES) -5 (CL_OUT_OF_RESOURCES)
Aborted (core dumped)
$または、onetrace を使用する場合は、次のようなメッセージが表示されます:
$ onetrace -c ./myapp
:
>>>> [6254070891] zeKernelSuggestGroupSize: hKernel = 0x263b7a0 globalSizeX = 163850 globalSizeY = 1 globalSizeZ = 1 groupSizeX = 0x7fff94e239f0 groupSizeY = 0x7fff94e239f4 groupSizeZ = 0x7fff94e239f8
<<<< [6254082074] zeKernelSuggestGroupSize [922 ns] -> ZE_RESULT_ERROR_OUT_OF_DEVICE_MEMORY(0x1879048195)
terminate called after throwing an instance of 'cl::sycl::runtime_error’
what(): Native API failed.Native API returns: -5 (CL_OUT_OF_RESOURCES) -5 (CL_OUT_OF_RESOURCES)
Aborted (core dumped)
$共有ローカルメモリーにコピーされたメモリーとハードウェアの上限を確認するには、デバッグキーを設定します:
export PrintDebugMessages=1
export NEOReadDebugKeys=1これにより、出力は次のようになります。
$ ./myapp
:
Size of SLM (656384) larger than available (131072) terminate called after throwing an instance of 'cl::sycl::runtime_error’
what(): Native API failed.Native API returns: -5 (CL_OUT_OF_RESOURCES) -5 (CL_OUT_OF_RESOURCES)
Aborted (core dumped)
$また、onetrace を使用する場合は次のようになります:
$ onetrace -c ./myapp
:
>>>> [317651739] zeKernelSuggestGroupSize: hKernel = 0x2175ae0 globalSizeX = 163850 globalSizeY = 1 globalSizeZ = 1 groupSizeX = 0x7ffd9caf0950 groupSizeY = 0x7ffd9caf0954 groupSizeZ = 0x7ffd9caf0958 Size of SLM (656384) larger than available (131072)
<<<< [317672417] zeKernelSuggestGroupSize [10325 ns] -> ZE_RESULT_ERROR_OUT_OF_DEVICE_MEMORY(0x1879048195) terminate called after throwing an instance of 'cl::sycl::runtime_error’
what(): Native API failed.Native API returns: -5 (CL_OUT_OF_RESOURCES) -5 (CL_OUT_OF_RESOURCES)
Aborted (core dumped)
$oneAPI で利用可能なデバッグ手法とデバッグツールの詳細については、DPC* ++ および OpenMP* オフロードプロセスのデバッグを参照してください。
GPU コードの最適化
オフロードコードされるコードを最適化するにはいくつかの方法があります。次の表には、最適化のヒントが示されています。詳細については、『oneAPI GPU 最適化ガイド』(PDF) を参照してください。
ホストとデバイス間のメモリー転送のオーバーヘッドを削減します。
コアをビジー状態に維持し、データ転送のオーバーヘッドのコストを軽減するのに十分な量のワークを実行します。
GPU キャッシュ、共有ローカルメモリーなど GPU メモリー階層を活用して、メモリーアクセスを高速化します。
JIT コンパイルの代わりに AOT コンパイル (オフラインコンパイル) を使用します。事前コンパイルでは、コードを特定の GPU アーキテクチャーをターゲットにできます。詳細については、GPU 向けの事前 (AOT) コンパイルを参照してください。
インテル® GPU Occupancy Calculator (英語) を使用すると、特定のカーネルおよびワークグループのパラメーターに対するインテル® GPU の占有率を計算できます。
オフロード・パフォーマンスの最適化で追加の推奨事項が提供されています。