SYCL* 実行とメモリー階層
実行階層
SYCL* 実行モデルは、GPU 実行の抽象化ビューを提供します。SYCL* スレッド階層は、ワーク項目の 1、2、または 3 次元のグリッドで構成されます。これらのワーク項目は、ワークグループと呼ばれる同一サイズのグループにグループ化されます。そして、ワークグループのワーク項目は、サブグループと呼ばれる同じサイズのグループに分割されます。
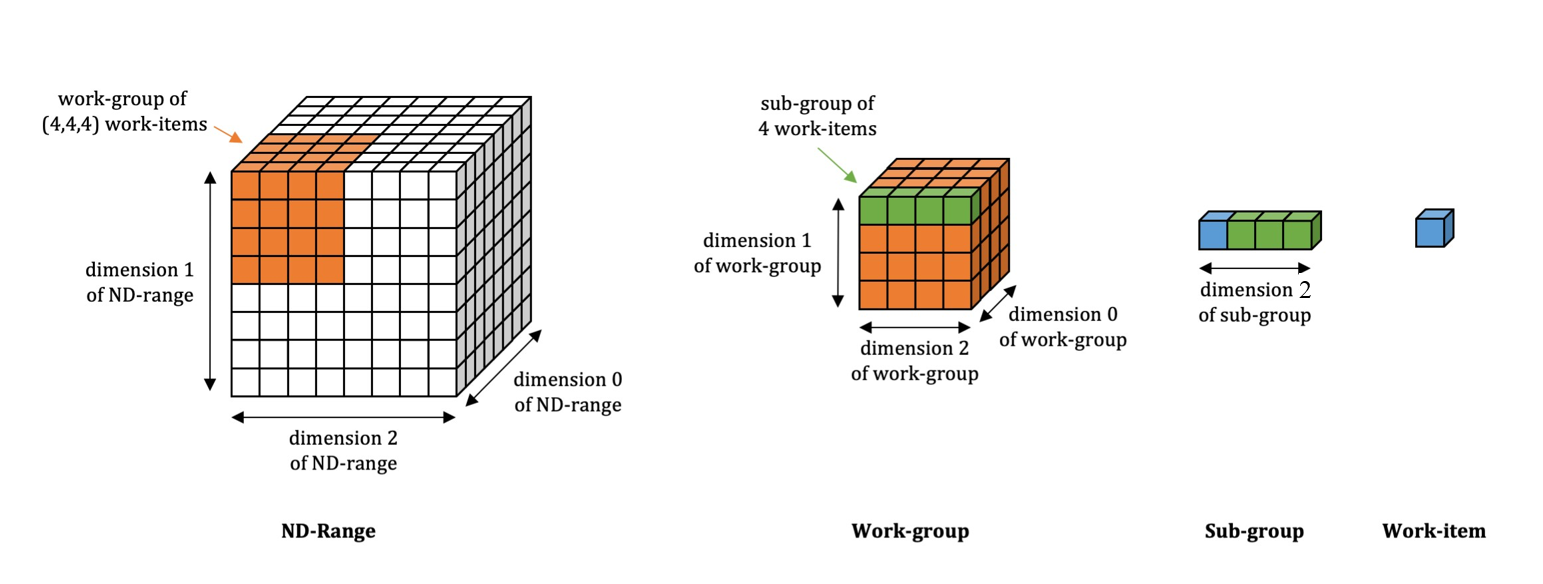
この階層が GPU またはインテル® UHD グラフィックス搭載の CPU でどのように機能するかは、『oneAPI GPU 最適化ガイド』の「スレッドのマッピングと GPU 占有率」を参照してください。
メモリーアクセスの最適化
インテル® VTune™ プロファイラーを使用すると、パフォーマンスを妨げているメモリーのボトルネックを特定できます。詳細については、『インテル® VTune™ プロファイラー・ユーザー・ガイド』の「メモリー割り当て API」のセクションを参照してください。
問題領域が特定されたら、『インテル® oneAPI GPU 最適化ガイド』に記載されているツールを使用して、カーネル内のワーク項目がどのように同期してデータを交換、更新、および相互に連携してタスクを実行できるか学習します。詳細については、GPU 最適化ガイドの以下のセクションを参照してください:
メモリー階層
汎用 GPU (GPGPU) の計算モデルは、1 つ以上の計算デバイスに接続されたホストで構成されます。各計算デバイスは、実行ユニット (EU) またはベクトルエンジン (XVE) と呼ばれる多数の GPU 計算エンジン (CE) で構成されています。また、計算デバイスは、次の図に示すように、キャッシュ、共有ローカルメモリー (SLM)、高帯域幅メモリー (HBM) などを含む場合があります。アプリケーションは、ホスト上のソフトウェア (ホスト・フレームグラフごと) と、ホストから送出されるカーネルの組み合わせとして構築され、事前に定義された分岐ポイントで VE 上で実行されます。
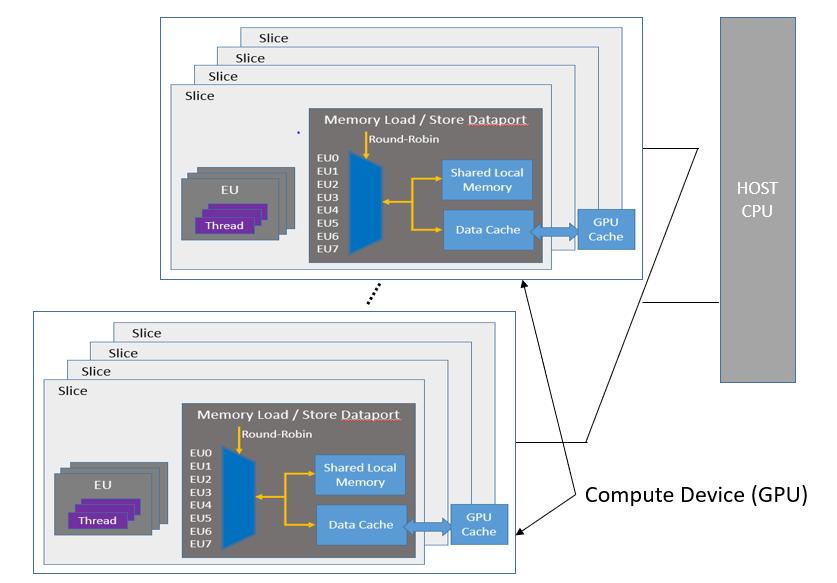
場合によっては、SYCL 2020 仕様で要求される動作によって、特定のデバイスで作成された kernel_bundle に互換性のあるカーネルが含まれないことがあります。詳細は、SYCL* カーネルの互換性を参照してください。
汎用 GPU (GPGPU) 計算モデル内のメモリー階層の詳細については、『oneAPI GPU 最適化ガイド』の「実行モデルの概要」を参照してください。
データ・プリフェッチを使用して GPU のメモリー・レイテンシーを削減
データ・プリフェッチを利用すると、ライトバックの量が減り、レイテンシーが短縮され、インテル® GPU のパフォーマンスが向上します。
oneAPI でのプリフェッチの仕組みの詳細については、『oneAPI GPU 最適化ガイド』の「プリフェッチ」を参照してください。