CPU オフロードの手順
デフォルトでは、CPU デバイスへオフロードする場合、OpenCL* ランタイムを使用します。OpenCL* ランタイムは、並列処理にインテル® oneAPI スレッディング・ビルディング・ブロック (oneTBB) も活用します。
CPU にオフロードする場合、ワークグループは異なる論理コアに割り当てられ、これらのワークグループは並列に実行できます。ワークグループ内のワーク項目は、CPU の SIMD レーンにマップできます。ワーク項目 (サブグループ) は、SIMD 方式で同時に実行されます。
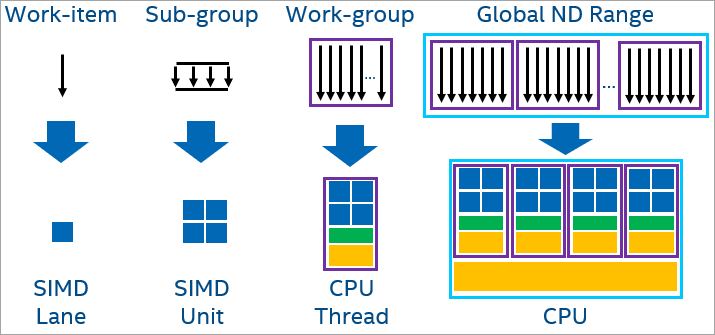
図. 10 CPU ワークグループ
CPU 実行の詳細については、「各種 oneAPI 計算ワークロードに対する CPU、GPU、および FPGA の利点の比較」(英語)を参照してください。
CPU オフロード向けの設定
setvarsやoneapi-varsスクリプトの実行を含む、oneAPI 開発環境の設定セクションのすべての手順を実行したことを確認します。sycl-lsコマンドを実行して、OpenCL* ランタイムが CPU に関連付けられていることを確認します。以下に例を示します:$sycl-ls CPU : OpenCL 2.1 (Build 0)[ 2020.11.12.0.14_160000 ] GPU : OpenCL 3.0 NEO [ 21.33.20678 ] GPU : 1.1[ 1.2.20939 ]
次のサンプルコードを使用して、コードが CPU で実行されていることを確認します。サンプルコードは、整数の大きなベクトルにスカラーを加算し、結果を検証します。
SYCL*
SYCL* では CPU で実行するための組込みデバイスセレクターが用意されています。これには、基本クラスとして device_selector を使用します。cpu_selector は、CPU を選択します。
または、default_selector を使用して、実装で定義されたヒューリスティックに従って次の環境変数によって実行時にデバイスを選択することもできます。
export ONEAPI_DEVICE_SELECTOR=cpuSYCL* サンプルコード:
#include <CL/sycl.hpp>
#include <array>
#include <iostream>
using namespace sycl;
using namespace std; constexpr size_t array_size = 10000;
int main(){
constexpr int value = 100000;
try{
cpu_selector d_selector;
queue q(d_selector);
int *sequential = malloc_shared<int>(array_size, q);
int *parallel = malloc_shared<int>(array_size, q);
// シーケンシャル iota
for (size_t i = 0; i < array_size; i++) sequential[i] = value + i;
// SYCL* の並列 iota
auto e = q.parallel_for(range{array_size}, [=](auto i) { parallel[i] = value + i; });
e.wait();
// 2 つの結果が等しいことを確認
for (size_t i = 0; i < array_size; i++) {
if (parallel[i] != sequential[i]) {
cout << "Failed on device.\n";
return -1;
}
}
free(sequential, q);
free(parallel, q);
}catch (std::exception const &e) {
cout << "An exception is caught while computing on device.\n";
terminate();
}
cout << "Successfully completed on device.\n";
return 0;
}次のコマンドでサンプルコードをコンパイルします:
dpcpp simple-iota-dp.cpp -o simple-iota.追加のコマンドはサンプルの CPU コマンドから取得できます。
生成したバイナリーを実行します:
./simple-iota
Running on device: Intel® Core™ i7-8700 CPU @ 3.20GHz
Successfully completed on device.OpenMP*
OpenMP* のサンプルコード:
#include<iostream>
#include<omp.h>
#define N 1024
int main(){
float *a = (float *)malloc(sizeof(float)*N);
for(int i = 0; i < N; i++)
a[i] = i;
#pragma omp target teams distribute parallel for simd map(tofrom: a[:N])
for(int i = 0; i < 1024; i++)
a[i]++;
std::cout << "Successfully completed on device.\n";
return 0;
}次のコマンドでサンプルコードをコンパイルします:
icpx simple-ompoffload.cpp -fiopenmp -fopenmp-targets=spir64 -o simple-ompoffloadバイナリーを起動して CPU 上でオフロード領域を実行する前に、次の環境変数を設定します:
export LIBOMPTARGET_DEVICETYPE=cpu
export LIBOMPTARGET_PLUGIN=opencl実行後の結果:
./simple-ompoffload Successfully completed on deviceCPU へコードをオフロード
アプリケーションをオフロードする場合、ボトルネックとオフロードの利点が得られるコード領域を特定することが重要です。計算集約型、または高度なデータ並列カーネルコードがある場合、そのコード領域をオフロードすることを検討してください。
オフロードするコード領域を特定するには、インテル® Advisor のオフロードのモデル化 (英語) が役立ちます。
オフロードされたコードのデバッグ
以下のリストには、オフロードされるコードの基本的なデバッグのヒントが示されています。
ホストターゲットをチェックしてコードが正しいことを確認します。
printfを使用して、アプリケーションをデバッグします。SYCL* と OpenMP* オフロードでは、どちらもカーネルコードでprintfがサポートされます。環境変数を設定して詳細なログ情報を取得します。
SYCL* では、次のデバッグ環境変数を利用できます。すべての環境変数については GitHub (英語) から入手できます。
表 1 SYCL* 推奨デバッグ環境変数 名前
値
説明
ONEAPI_DEVICE_SELECTORbackend:device_type:device_numSYCL_UR_TRACE1|2|-1
1: : SYCL*/DPC++ ランタイムプラグインの基本トレースログを出力します
2: SYCL*/DPC++ ランタイムプラグインのすべての API トレースを出力します
-1: "2" のすべてと追加のデバッグ情報を出力します。
OpenMP* では、次のデバッグ環境変数が推奨されます。利用可能なすべての環境変数については、「LLVM/OpenMP* ドキュメント」 (英語) を参照してください。
表 2 OpenMP* 推奨デバッグ環境変数 名前
値
説明
LIBOMPTARGET_DEVICETYPEcpu|gpu|host
Select
LIBOMPTARGET_DEBUG1
詳細なデバッグ情報を出力します。
LIBOMPTARGET_INFOユーザーが
libomptargetから各種タイプのランタイム情報を要求できるようにします。
事前 (AOT) コンパイルを使用して、ジャストインタイム (JIT) コンパイルを AOT コンパイルに移行します。詳細については、CPU アーキテクチャー向けの事前コンパイルを参照してください。
oneAPI で利用可能なデバッグ手法とデバッグツールの詳細については、SYCL* および OpenMP* オフロードプロセスのデバッグを参照してください。
CPU コードの最適化
CPU オフロードコードのパフォーマンスに影響する可能性がある多くの要因があります。ワーク項目、ワークグループ、および実行されるワーク量は、CPU コア数によって異なります。
コアで実行されるワーク量が計算集約型でない場合、パフォーマンスが低下する可能性があります。これは、スケジュールのオーバーヘッドとスレッドのコンテキスト切り替えが原因です。
CPU では、PCIe* を介したデータ転送が不要であり、オフロード領域がデータを長時間待機する必要がないため、レイテンシーが低くなります。
アプリケーションの性質に基づいて、スレッド・アフィニティーは CPU のパフォーマンスに影響を与える可能性があります。詳細については、マルチコアにおけるバイナリーの実行制御を参照してください。
オフロードコードは、デフォルトで JIT コンパイルを使用しますが、代わりに AOT コンパイル(オフラインコンパイル)を使用します。事前コンパイルでは、コードを特定の CPU アーキテクチャーをターゲットにできます。詳細については、CPU アーキテクチャー向けの最適化オプションを参照してください。
オフロード・パフォーマンスの最適化で追加の推奨事項が提供されています。