コンパイルの手順
オフロードを行うプログラムを作成する場合、コンパイラーはホストとデバイス向けの両方のコードを生成する必要があります。oneAPI は、この複雑な作業を開発者から見えないようにします。開発者は、インテル® oneAPI DPC++ コンパイラー (icpx -fsycl) を使用して SYCL* アプリケーションをコンパイルするだけで (一度のコンパイルコマンドで)、ホストとデバイス向けのコードを生成できます。
注
システム要件に記載されているインテル® プロセッサーに加えて、AMD* (Linux* のみ) および NVIDIA* (Linux および Windows*) GPU もターゲットとなる場合があります:
AMD* GPU をインテル® oneAPI DPC++ コンパイラーで使用するには、Codeplay から AMD GPU 用 oneAPI プラグインを入手してインストールします。
NVIDIA* GPU をインテル® oneAPI DPC++ コンパイラーで使用するには、Codeplay から NVIDIA GPU 用 oneAPI プラグインを入手してインストールします。
デバイスコードには、Just-in-Time (JIT) コンパイルと ahead-of-time (AOT) コンパイルの 2 つのオプションがありますが、JIT がデフォルトです。このセクションでは、ホストコードのコンパイル方法と、デバイスコードを生成する 2 つの方法を説明します。詳しくは、「Data Parallel C++ の書籍」 (英語) の 13 章をご覧ください。
従来のコンパイル手順 (ホストのみのアプリケーション)
従来のコンパイル手順は、C、C++、またはそのほかの言語で利用される標準のコンパイル方法です。デバ イスへのオフロードがない場合に使用されます。
コンパイル手順を図に示します。
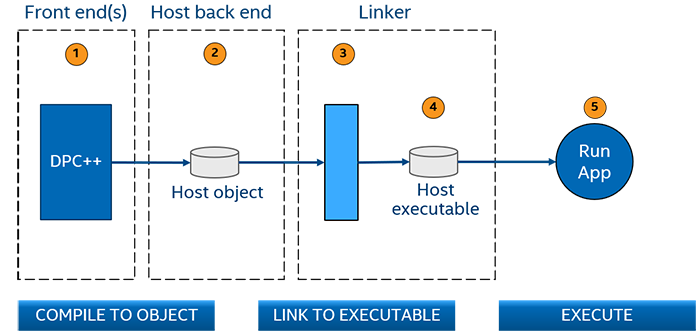
図. 5 従来のコンパイルフェーズ
フロントエンドは、ソースを中間表現に変換し、バックエンドに渡します。
バックエンドは、中間表現をオブジェクト・コードに変換してオブジェクト・ファイル (Windows* では
host.obj、Linux* ではhost.o) を出力します。1 つ以上のオブジェクト・ファイルがリンカーに渡されます。
リンカーは実行ファイルを生成します。
これで、アプリケーションを実行できます。
SYCL* オフロードコードのコンパイル手順
SYCL* オフロードコードのコンパイル手順には、従来のコンパイル手順にデバイスコードの JIT および AOT オプションを追加します。この手順では、開発者は icpx -fsycl を使用して、SYCL* アプリケーションをコンパイルし、出力としてホストコードとデバイスコードの両方を含む実行可能ファイルを作成します。
SYCL* オフロードコードの基本コンパイル手順を次に示します。
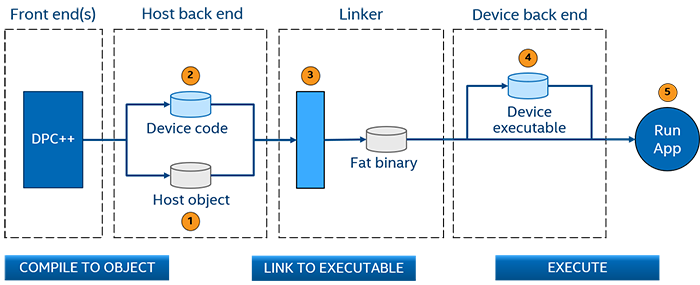
図. 6 SYCL* オフロードコードの基本的なコンパイルフェーズ
ホストコードは、バックエンドでオブジェクト・コードに変換されます。
デバイスコードは SPIR-V* 形式またはデバイスバイナリーに変換されます。
リンカーは、ホスト・オブジェクト・コードとデバイスコード (SPIR-V またはデバイスバイナリー) を、デバイスコードが埋め込まれたホストバイナリーを含む実行可能ファイルに結合します。これは、ファットバイナリーと呼ばれます。
バイナリーが起動されると、オペレーティング・システムはホスト・アプリケーションを実行します。オフロードが行われる場合、ランタイムはデバイスコードをロードします(必要に応じて SPIR-V* をデバイスバイナリーに変換します)。
アプリケーションは、ホストと利用可能なデバイスで実行されます。
JIT のコンパイル手順
JIT コンパイルの手順では、デバイスコードはバックエンドで SPIR-V* 形式の中間コードに変換され、SPIR-V* としてファットバイナリーに組み込まれ、ランタイムによって SPIR-V* からデバイスバイナリーに 変換されます。アプリケーションが起動されると、ランタイムは利用可能なデバイスを判別してそのデバイス固有のコードを生成します。これにより、AOT (事前) コンパイル手順よりも、アプリケーションの実行環境とパフォーマンスの柔軟性が高まります。しかし、アプリケーションの実行時にコンパイル (JIT) が行われるため、アプリケーションの実行時間が増加する可能性があります。大量のデバイスコードを持つ大規模なアプリケーションでは、パフォーマンスへの影響が顕著に表れることがあります。
ヒント
JIT コンパイル手順は、ターゲットデバイスが不明である場合に役立ちます。
注
JIT コンパイルは、FPGA デバイスではサポートされません。
コンパイル手順を次の図に示します:
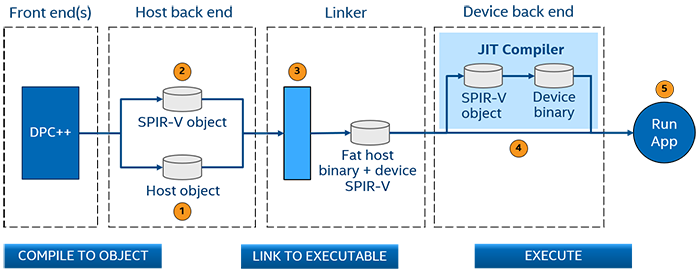
図. 7 JIT コンパイルフェーズ
ホストコードは、バックエンドでオブジェクト・コードに変換されます。
デバイスコードは SPIR-V* 形式に変換されます。
リンカーは、ホスト・オブジェクト・コードとデバイス SPIR-V を組み合わせた (SPIR-V が埋め込まれた)、ホスト実行コードを含むファットバイナリーを生成します。
実行されると次のように処理されます:
ホスト上のデバイスランタイムは、デバイスの SPIR-V をデバイスのバイナリーに変換します。
変換されたデバイスバイナリーはデバイスへロードされます。
アプリケーションは、実行時に利用可能なホストとデバイスで実行されます。
AOT のコンパイル手順
AOT(事前)コンパイルでは、デバイスコードが SPIR-V* に変換されてから、ホスト・バックエンドのデバイ スコードに変換され、最終的に生成されたデバイスコードがファットバイナリーに組み込まれます。AOT(事前)コンパイルでは、デバイスコードが SPIR-V* に変換されてから、ホスト・バックエンドのデバイ スコードに変換され、最終的に生成されたデバイスコードがファットバイナリーに組み込まれます。しかし、実行ファイルの起動時間は JIT 手順よりも短くなります。
ヒント
AOT 手順は、ターゲットデバイスが判明している場合に適しています。
AOT 手順では、デバックサイクルがスピードアップされるため、アプリケーションをデバッグする際の利用が推奨されます。
コンパイル手順を次の図に示します:
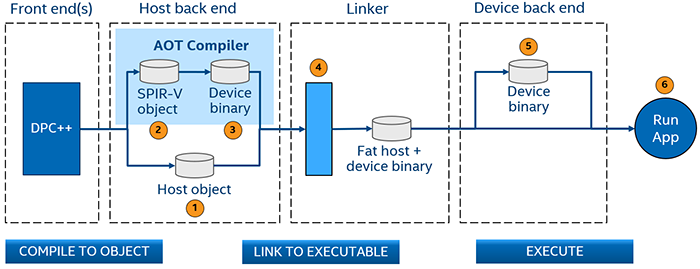
図. 8 AOT コンパイルフェーズ
ホストコードは、バックエンドでオブジェクト・コードに変換されます。
デバイスコードは SPIR-V* 形式に変換されます。
デバイスの SPIR-V* は、コマンドラインでユーザーが指定したデバイス向けのデバイス・コード・オブジェクトに変換されます。
リンカーは、ホスト・オブジェクト・コードとデバイス・オブジェクト・コードを組み合わせた、デバイスバイナリーが埋め込まれたホスト実行コードを含むファットバイナリーを生成します。
実行時に、デバイスバイナリーはデバイスへロードされます。
アプリケーションは、ホストと指定されたデバイスで実行されます。
ファットバイナリー (Fat Binary)
ファットバイナリーは、JIT と AOT コンパイル手順から生成されます。デバイスコードが埋め込まれたホストバイナリーです。デバイスコード自体は、コンパイル手順によって異なります。

図. 9 ファットバイナリー
ホストコードは、ELF (Linux*) または PE (Windows*) 形式の実行ファイルです。
デバイスコードは、JIT 手順では SPIR-V、AOT 手順ではデバイスバイナリー (実行可能) です。実行ファイルは次のいずれかの形式です。
CPU: ELF (Linux*)、PE (Windows*)
GPU: ELF (Windows*、Linux*)
FPGA: ELF (Linux*)、PE (Windows*)