インテル® Advisor を使用すると、CPU バージョンを指定することなく、別の GPU デバイスのグラフィックス処理ユニット (GPU) で実行されている SYCL*、OpenCL*、OpenMP* target アプリケーションのパフォーマンスをモデル化できます。これには、オフロードのモデル化パースペクティブの GPU - GPU 間モデル化ワークフローを実行します。
GPU 間のモデル化は、GPU 計算カーネルのみを解析し、CPU で実行されるアプリケーション領域を無視します。その結果、モデル化のフローにいくつかの変更が加えられています。
- 計算カーネルの特性は、インテル® Advisor のGPU プロファイル機能を使用して収集されます。
- コールスタック処理、キャッシュおよびデータ転送シミュレーション、依存関係解析など、オーバーヘッドの高い機能を無効にできます。
- CPU - GPU 間のデータ転送シミュレーションの代わりに、ホストとデバイスのメモリー間で転送されるメモリー・オブジェクトがトレースされます。
ワークフロー
GPU - GPU 間のパフォーマンスのモデル化ワークフローは、CPU - GPU 間のモデル化と似ており、次の手順が含まれます。
- サーベイ解析では、インテル® グラフィックスで実行されている GPU 対応カーネルのハードウェア・カウンターを使用して、実行時間、キャッシュ、および GTI トラフィックを測定します。
- 特性化解析では、インテル® グラフィックスで実行されているカーネルの各種 GPU 命令を個別にカウントして、計算操作数を測定します。例えば、SQRT、EXP、DIV などのハードウェアで実装される 32 ビット数学関数向けに個別のカウンターを実装しています。
- パフォーマンスのモデル化解析では、収益性の有無にかかわらず、ターゲット GPU デバイス上のすべてのカーネルのパフォーマンスをモデル化します。
注
メモリー・オブジェクトを正確にトレースするには、GPU カーネルを oneAPI レベルゼロ・バックエンドで実行する必要があります。必要条件
- GPU カーネル解析向けにシステムを設定します。
- 自動スクリプトを使用してインテル® Advisor の環境変数を設定し、インテル® Advisor のコマンドライン・インターフェイス (CLI) 利用できるようにします。
GPU - GPU 間のパフォーマンスのモデル化を実行
コマンドラインから GPU - GPU 間のパフォーマンスをモデル化するには、次のいずれかの方法を行います。
- 手法 1: インテル® Advisor のコマンドライン・インターフェイス (CLI) を使用して、事前設定された収集を実行し、単一のコマンドで複数の解析を実行してモデル化の精度を制御します。
- 手法 2: 解析ごとに高度なカスタマイズが必要な場合、インテル® Advisor の CLI を使用して解析を個別に実行します。
- 手法 3: 収集およびモデル化の手順をさらにカスタマイズする場合、Python* スクリプトを実行します。
インテル® Advisor のグラフィカル・ユーザー・インターフェイス (GUI) から GPU - GPU 間のオフロードのモデル化を実行することもできます。GUI からオフロードのモデル化パースペクティブを実行を参照してください。
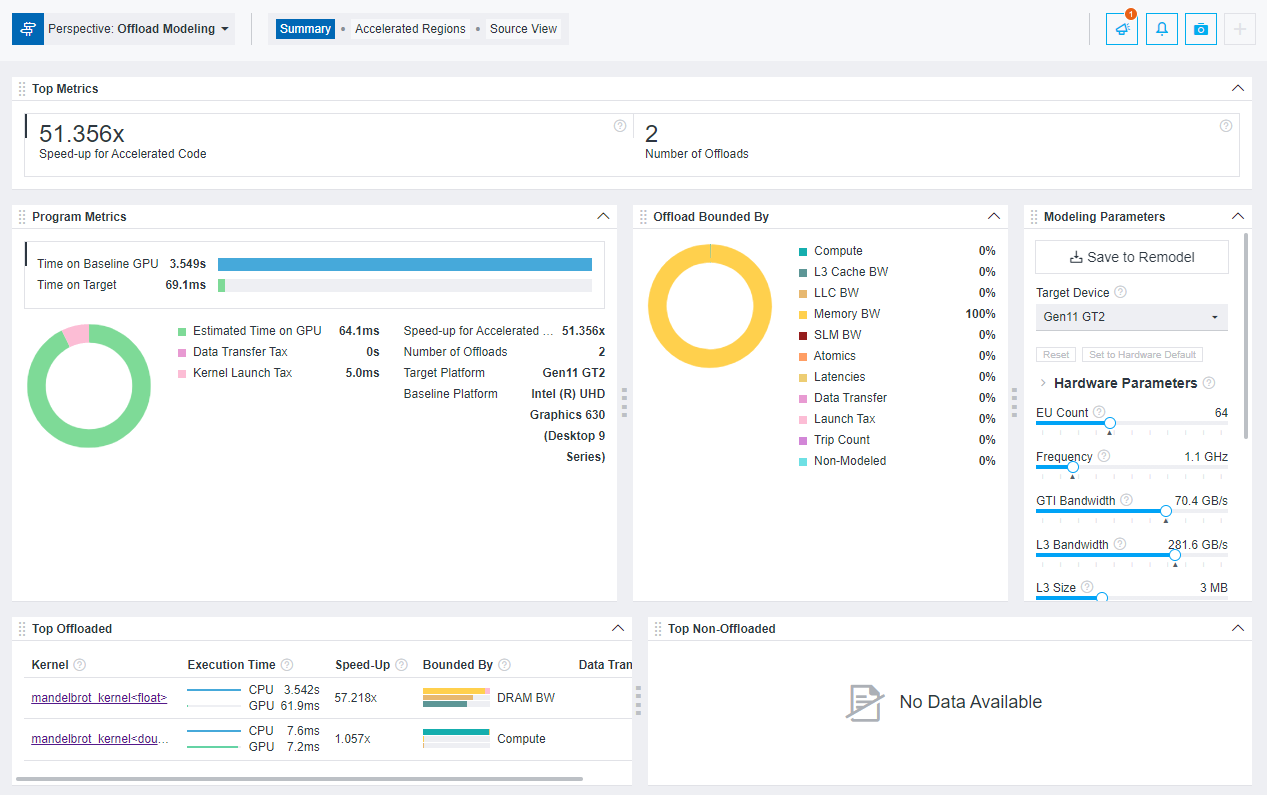
上記のいずれかの方法でオフロードのモデル化を実行した後、インテル® Advisor のグラフィカル・ユーザー・インターフェイス (GUI)、コマンドライン・インターフェイス (CLI)、または対話型 HTML レポートで結果を表示できます。例えば、対話型 HTML レポートは次のようになります。
ヒント
MPI アプリケーションを解析する場合、事前設定されたコマンドラインを生成し、コピーして 1 つずつ実行できます。詳細については、事前定義されたコマンドラインを生成を参照してください。手法 1: 事前定義された収集を使用する
事前設定された GPU - GPU 間のモデル化を実行するには、--collect=offload アクションとともに --gpu オプションを使用します。収集を実行すると、GPU 上のデータ収集とパフォーマンスのモデル化のステップが順番に実行されます。特定の解析とオプションは、収集に指定した精度レベルによって異なります。
注以下のコマンドでは、コマンドを実行する前に myApplication をアプリケーションの実行可能形式へのパスと名前に置き換える必要があります。アプリケーションが引数を必要とする場合、実行可能ファイル名の後にそれらを指定します。
例えば、GPU - GPU 間のモデル化をデフォルト (中) 精度レベルで実行するには、次のコマンドを使用します。
- Linux*:
advisor --collect=offload --gpu --project-dir=./advi_results -- ./myApplication - Windows*:
advisor --collect=offload --gpu --project-dir=.\advi_results -- myApplication.exe
収集の進行状況と、実行された解析のコマンドがターミナル/コマンドプロンプトに出力されます。収集が完了すると、結果のサマリーが表示されます。
異なる精度レベルを指定して、実行する解析とオプションを変更することもできます。利用可能な精度レベルは、low (低)、medium (中) (デフォルトt)、および high (高) です。
例えば、high (高) 精度レベルの解析を実行します。
advisor --collect=offload --accuracy=high --gpu --project-dir=./advi_results -- ./myApplicationそれぞれの精度レベルで実行されるコマンドを確認する場合、--dry-run と --gpu オプションを指定して収集を実行します。コマンドはターミナルまたはコマンドプロンプトに出力されます。
それぞれの精度レベルについては、コマンドラインでのオフロードのモデル化精度レベルを参照してください。
手法 2: 事前定義の収集を使用
個別のコマンドでそれぞれのオフロードのモデル化解析を実行し、アプリケーションのデータを収集してパフォーマンスをモデル化できます。GPU - GPU 間のモデル化を有効にするには、実行するそれぞれの解析で --profile-gpu オプションを使用します。
次のワークフローの例について考えてみます。この例では、サーベイ、トリップカウント、および FLOP 解析を実行して GPU で実行されるアプリケーションをプロファイルし、パフォーマンスのモデル化を実行して、インテル® Iris® Xe MAX グラフィックス (gen12_dg1 設定) でのパフォーマンスをモデル化します。
注以下のコマンドでは、コマンドを実行する前に myApplication をアプリケーションの実行可能形式へのパスと名前に置き換える必要があります。アプリケーションが引数を必要とする場合、実行可能ファイル名の後にそれらを指定します。
Linux*:
- サーベイ解析を実行します。
advisor --collect=survey --profile-gpu --project-dir=./advi_results -- ./myApplication - データ転送予測によるトリップカウント & FLOP 解析を実行します。
advisor --collect=tripcounts --profile-gpu --flop --target-device=gen12_dg1 --data-transfer=light --project-dir=./advi_results -- ./myApplication - パフォーマンスのモデル化解析を実行します。
advisor --collect=projection --profile-gpu --config=gen12_dg1 --project-dir=./advi_results結果のサマリーがコマンドプロンプトに出力されます。
Windows*:
- サーベイ解析を実行します。
advisor --collect=survey --project-dir=.\advi_results -- myApplication.exe - データ転送とトリップカウント & FLOP 解析を実行します。
advisor --collect=tripcounts --profile-gpu --flop --stacks --target-device=gen12_dg1 --data-transfer=light --project-dir=.\advi_results -- myApplication.exe - パフォーマンスのモデル化解析を実行します。
advisor --collect=projection --profile-gpu --config=gen12_dg1 --project-dir=.\advi_results結果のサマリーがコマンドプロンプトに出力されます。
手法 3: Python* スクリプトを使用
インテル® Advisor には、インテル® Advisor Python* API を使用してオフロードのモデル化を行う 3 つのスクリプト、run_oa.py、collect.py、analyze.py が用意されています。スクリプトは、インテル® Advisor の advisor-python コマンドライン・インターフェイス、またはローカルの Python* 3.6 または 3.7 を使用して実行できます。
GPU - GPU 間のモデル化を有効にするには、実行するそれぞれのスクリプトで --gpu オプションを使用します。
注
このスクリプトは MPI アプリケーションをサポートしません。MPI アプリケーションを解析するには、インテル® Advisor CLI で事前定義された収集を行います。スクリプトとインテル® Advisor CLI を組み合わせてオフロードのモデル化を実行することもできます。例:
- run_oa.py を実行してアプリケーションをプロファイルし、パフォーマンスをモデル化します。
- collect.py を実行してアプリケーションをプロファイルし、analyze.py を実行してパフォーマンスをモデル化します。analyze.py を再実行して異なる設定で再モデル化します。
- インテル® Advisor CLI を実行してパフォーマンス・データを収集し、analyze.py でパフォーマンスをモデル化します。analyze.py を再実行して異なる設定で再モデル化します。
- run_oa.py を実行して初期のデータを収集し、パフォーマンスをモデル化し、analyze.py を実行して異なる構成で再モデル化します。
次の例に示す、Python スクリプトを使用するいくつかの典型的なシナリオを検討してください。
注以下のコマンドでは、コマンドを実行する前に myApplication をアプリケーションの実行可能形式へのパスと名前に置き換える必要があります。アプリケーションが引数を必要とする場合、実行可能ファイル名の後にそれらを指定します。
例 1run_oa.py スクリプトを実行して、GPU 上のアプリケーションをプロファイルし、インテル® Iris® Xe MAX グラフィックス (gen12_dg1 設定) のパフォーマンスをモデル化します。
- Linux*:
advisor-python $APM/run_oa.py ./advi_results --gpu --config=gen12_dg1 -- ./myApplication - Windows*:
advisor-python %APM%\run_oa.py .\advi_results --gpu --config=gen12_dg1 -- myApplication.exe
結果のサマリーがコマンドプロンプトに出力されます。
例 2collect.py を実行して、GPU 上のアプリケーションをプロファイルし、インテル® Iris® Xe MAX グラフィックス (gen12_dg1 設定) のパフォーマンスをモデル化するため analyze.py を実行します。
- Linux*:
- パフォーマンス・データを収集します。
advisor-python $APM/collect.py ./advi_results --gpu --config=gen12_dg1 -- ./myApplication - アプリケーション・パフォーマンスのモデル化。
advisor-python $APM/analyze.py ./advi --gpu --config=gen12_dg1結果のサマリーがコマンドプロンプトに出力されます。
- パフォーマンス・データを収集します。
- Windows*:
- パフォーマンス・データを収集します。
advisor-python %APM%\collect.py .\advi_results --collect=basic --gpu --config=gen12_dg1 -- myApplication.exe - アプリケーション・パフォーマンスのモデル化。
advisor-python %APM%\analyze.py .\advi_results --gpu --config=gen12_dg1結果のサマリーがコマンドプロンプトに出力されます。
- パフォーマンス・データを収集します。
結果を表示
インテル® Advisor で解析が完了すると、結果は次の形式で取得できます。
- コマンドプロンプトまたはターミナルに出力された結果のサマリーと結果ファイルの場所を確認します。
- インテル® Advisor GUI でプロジェクト・ディレクトリーに生成された結果を確認します。
- <project-dir>/e<NNN>/report ディレクトリーに生成された HTML レポートを確認します。HTML レポートに関する詳細は、スタンドアロンで HTML レポートを操作を参照してください。
- <project-dir>/e<NNN>/pp<NNN>/data.0 ディレクトリーに生成された一連のレポートを確認します。このディレクトリーには、report.html という名前の HTML 形式のメインレポートと、詳細なメトリックテーブルを表現する CSV ファイルが含まれます。
例えば、インテル® Advisor GUI の結果は次のようになります。
対話型の HTML レポートを調べるには、事前に収集された GPU ルーフライン・レポートをダウンロード (英語) して、結果と構造を調査できます。
利用可能な結果形式の詳細についてはオフロードのモデル化の結果を調査を、GPU - GPU 間のモデル化の結果の詳細については GPU - GPU 間のモデル化によるパフォーマンス・ゲインを調査を参照してください。