有効となる解析
GPU カーネルのみのパースペクティブを収集 (サーベイ、特性化) + GPU カーネルのみのパフォーマンスのモデル化
結果の解釈
生成された結果は次のように表示できます。
- コマンドプロンプトまたはターミナルに出力された結果のサマリーと結果ファイルの場所を確認します。
- インテル® Advisor グラフィカル・ユーザー・インターフェイス (GUI) でプロジェクト・ディレクトリーに生成された結果を確認します。
- <project-dir>/e<NNN>/report ディレクトリーに生成された HTML レポートを確認します。
- <project-dir>/e<NNN>/pp<NNN>/data.0 ディレクトリーに生成された、詳細メトリックテーブルを含む CSV レポートを確認します。
このトピックでは、インテル® Advisor GUI のオフロードのモデル化レポートに示されるデータについて説明します。結果を HTML 形式で表示することもできますが、データの配置とペインが異なることがあります。
生成される GPU - GPU 間のパフォーマンスのモデル化レポートの構造と制御は、CPU - GPU 間のオフロードのオフロードのモデル化レポートと似ていますが、GPU - GPU 間のモデル化では、インテル® Advisor はアプリケーションの GPU 領域のみをモデル化するため、表示される内容が異なります。
サポートを開くと、最初に [Summary (サマリー)] タブが表示されます。このタブでは、アプリケーションの GPU カーネルのモデル化の結果のサマリーと、推測されるパフォーマンス・メトリックを確認できます。
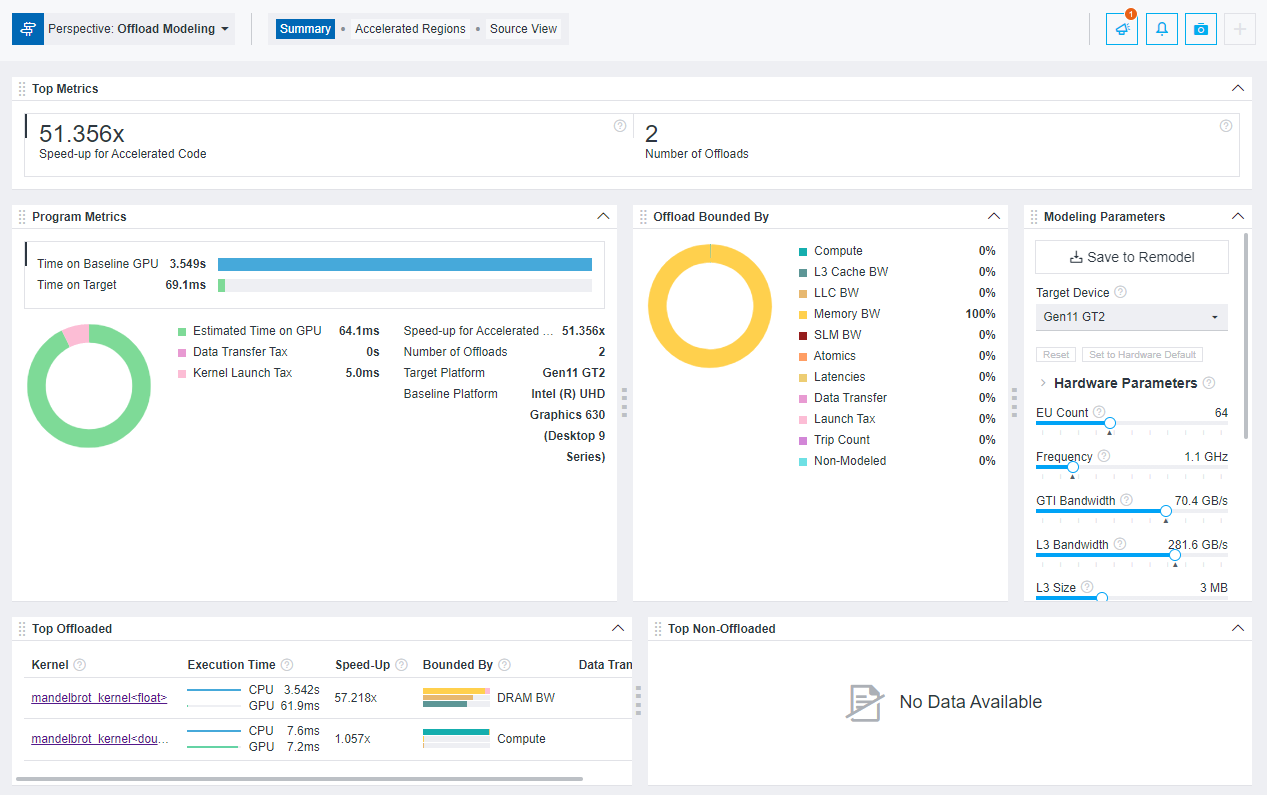
- [Program Metrics (プログラム・メトリック)] ペインで、ベースライン GPU 時間とターゲット GPU 時間を比較して、高速化されたコードのスピードアップを調査し、アプリケーションの GPU カーネルがターゲット GPU で高いパフォーマンスを発揮するか確認できます。ベースライン GPU 時間には、GPU カーネルの実行時間のみが含まれ、CPU 領域は無視されます。ターゲット GPU 時間には、ターゲット GPU 上の GPU カーネルの推測される実行時間とオフロードコストが含まれます。
表示される円グラフで、GPU 実行時間とオフロードのコスト (カーネル起動コストとデータ転送コスト) の比率を確認し、GPU カーネルで最も時間が費やされる場所を特定します。
- [Offloads Bounded by (オフロードの制限)] ペインで、GPU カーネルがターゲット GPU でどのような制限を受けるか調査します。最も高いパーセンテージのパラメーターは、GPU カーネルが最も時間を費やす場所であることを意味します。他のタブでもこれらのパラメーターの詳細なメトリックを確認して、それに対処してアプリケーションを最適化する必要があるか判断してください。
- [Top offloaded (上位オフロード)] ペインで、ターゲット GPU で推測されるオフロードのゲイン (秒単位) が最も高い上位 5 つの GPU カーネルを確認します。このゲインは、(ベースライン GPU で測定された時間 - ターゲット GPU で推測される時間) として求められます。
ペイン内のカーネルごとに、スピードアップ、ベースラインとターゲット GPU の時間、主な制限要因、および推測されるデータ転送量を確認できます。インテル® Advisor はカーネルを 1 対 1 でモデル化し、推測されるスピードアップが 1 未満のカーネルも除外せず表示します。
注
[Top non offloaded (オフロードされない上位)] ペインには、モデル化できない GPU カーネルのみが表示されます。すべてのカーネルがモデル化されると、このペインは空になります。GPU - GPU 間のモデル化では、推測されるスピードアップが 1 未満であっても、カーネルをオフロードできない理由とはなりません。GPU カーネルのパフォーマンスの詳細を確認するには、[Accelerated Regions (アクセラレートされた領域)] タブに移動します。
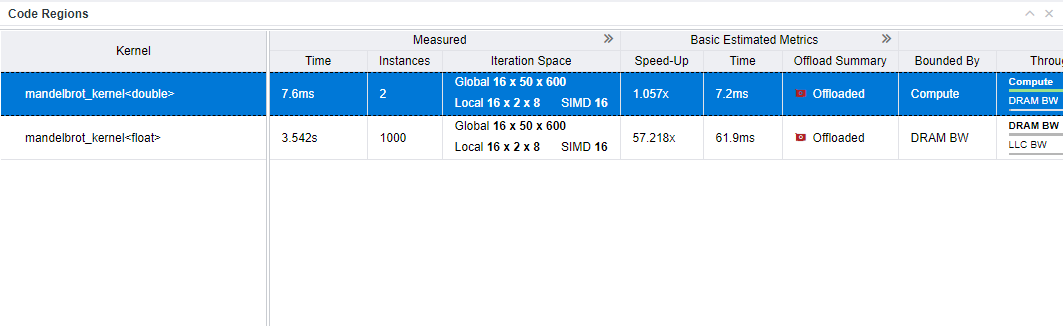
- コード領域テーブルで、GPU カーネルの詳しいパフォーマンス・メトリックを確認します。[Measured (測定)] カラムには、ベースライン GPU で測定されたメトリックが表示されます。他のカラムグループには、ターゲット GPU に対して推測されたメトリックが示されます。カラムグループを展開すると、さらに多くのメトリックを表示できます。
また、テーブル内のカーネルを選択し、右のペインの [Details (詳細)] タブでカーネルで測定されたメトリックと推測されたメトリックをハイライトして、注目すべき事項を特定することもできます。
例えば、ボトルネックの可能性を検出します。
- [Bounded by (制限要因)] カラムと [Throughput (スループット)] カラムに注目し、[Estimated Bounded by (推測される制限)] カラムグループを調べます。[Bounded by (制限要因)] カラムには、主なボトルネックとそれに次ぐボトルネックが表示されます。[Throughput (スループット)] カラムは、グラフで表示される計算またはメモリー・スループット、レイテンシー、およびオフロードコストを時間経過とともにボトルネックを示します。ボトルネックの詳細については、制限要因を参照してください。
- 制限要因の詳細については、カラムグループを展開して、制限要因に対応するカラム (L3 キャッシュ、DRAM BW、または LLC BW など) を見つけます。
- 右にスクロールして、[Memory Estimations (メモリー推測)] カラムを展開し、特定されたボトルネックに対応するカラムを調べます。例えば、帯域幅の利用率は、平均メモリーレベル帯域幅とそのピーク帯域幅の関係として求められます。高い値は、カーネルがメモリーレベルを適切に利用しておらず、潜在的なボトルネックがあることを意味します。
次のデータからボトルネックを検出できます。
- キャッシュまたはメモリー帯域幅の利用率が高い場合 (L3 キャッシュ、SLM、LLC カラムグループ)、パフォーマンスを向上するにはキャッシュ/メモリー・トラフィックの最適化を検討してください。
- [Estimated Bounded By (推測される制限)] カラムグループでレイテンシーが長い場合、カーネルに十分な並列ワークをスケジュールしてスレッド占有率を増やし、キャッシュ/メモリーのレイテンシーを最適化することを検討してください。
- 再利用とデータ転送の推測で高いデータ転送コストが示される場合、データ転送コストの最適化や統合共有メモリー (USM) の利用を検討してください。
- カーネルのデータ転送コストが高い場合は、[Code Regions (コード領域)] テーブルでカーネルを選択し、右の [Data Transfer Estimations (データ転送推測)] ペインでカーネルのホストデバイスとターゲット GPU 間で転送されるメモリー・オブジェクトの詳細を調査します。以下のデータを確認します。
- 転送データのヒストグラムでは、それぞれの方向で転送されたデータ量とそれに対応するオフロードのコストを確認します。
- カーネルによってアクセスされるすべてのメモリー・オブジェクトを含むメモリー・オブジェクト・テーブルには、サイズ、転送方向 (ホストのみ、ターゲットのみ、ホストからターゲット、およびその逆)、オブジェクト・タイプなど、オブジェクトの詳細が示されます。小さなオブジェクトが多数ある場合、カーネルのレイテンシーが長くなる可能性があります。レイテンシーが長いと、データ転送コストが高くなる恐れがあります。
- 選択されたコード領域におけるデータ転送の最適化に関するヒント。
インテル® Advisor は、このデータを使用して、それぞれのカーネルのデータ転送トラフィックとデータ転送を推測します。
次のステップ
- 収集されたデータを基に、別のターゲット GPU へオフロードするようにコードを書き直してパフォーマンスを向上させ、GPU ルーフラインの調査パースペクティブでパフォーマンスを測定します。
- 「oneAPI GPU 最適化ガイド」の GPU で実行される oneAPI アプリケーションの最適化のヒントを参照してください。