インテル® Advisor は、コマンドラインからオフロードのモデル化パースペクティブを実行するいくつかの方法を提供します。次のいずれかを使用します。
- 手法 1 事前定義されたコマンドライン・コレクションを使用して、オフロードのモデル化を実行します。インテル® Advisor の基本的な解析やモデル化機能、特に初期の実行解析ではこの方法を使用します。この方法を使用すると、単一コマンドで複数の解析を実行し、モデル化の精度を制御できます。
- 手法 2 オフロードのモデル化解析を個別に実行します。MPI アプリケーションを解析する場合、またはより高度な解析のカスタマイズが必要な場合は、この方法を使用します。この方法を使用すると、アプリケーションで収集するパフォーマンス・データを選択して、それぞれの解析を個別に設定できます。
- 手法 3 Python* スクリプトでオフロードのモデル化を実行します。さらに解析のカスタマイズが必要な場合は、この方法を使用します。この方法には適度な柔軟性があり、データ収集とパフォーマンスのモデル化の手順をカスタマイズできます。
上記のいずれかの方法でオフロードのモデル化を実行した後、インテル® Advisor のグラフィカル・ユーザー・インターフェイス (GUI)、コマンドライン・インターフェイス (CLI)、または対話型 HTML レポートで結果を表示できます。例えば、対話型 HTML レポートは次のようになります。
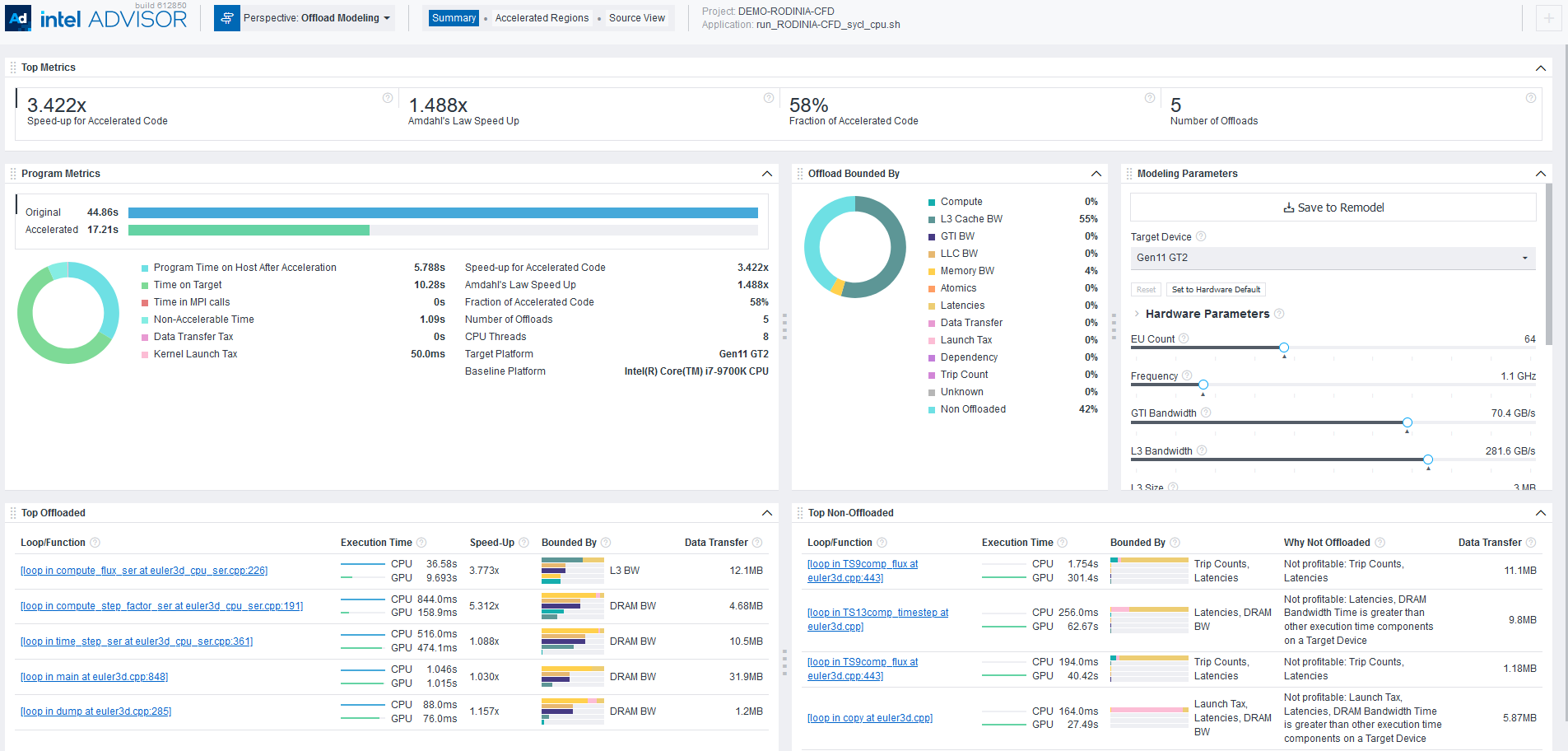
必要条件
- 自動スクリプトでインテル® Advisor の環境変数を設定します。
このスクリプトは、Advisor コマンドライン・インターフェイス (CLI)、advisor-python コマンドライン・ツール、およびオフロードのモデル化スクリプトが含まれるディレクトリーを示す APM 環境変数を有効にして、それらを使用します。
- SYCL*、OpenMP* target、 OpenCL* アプリケーションの場合: インテル® Advisor の環境変数を設定して、解析のためアプリケーションを一時的に CPU にオフロードします。
注
GPU - GPU パフォーマンス・モデル化を実行して、SYCL*、OpenMP*、および OpenCL* アプリケーションを解析することを推奨します。正確な見積もりが得られます。
オプション: 事前定義されたコマンドラインの生成
インテル® Advisor では、アプリケーションとハードウェア向けに事前設定されたコマンドラインを生成できます。この機能は次の場合に使用します。
- MPI アプリケーションの解析
- 事前設定されたオフロードのモデル化コマンドをカスタマイズ
オフロードのモデル化パースペクティブは、同じアプリケーションとプロジェクトに対して実行される複数の解析ステップで構成されます。それぞれのステップを最初から構成することも、プロジェクトのディレクトリーやアプリケーションの実行可能ファイルへのパスを手動で指定する必要がない、事前定義されたコマンドラインを使用することもできます。
オプション 1。--collect=offload と the --dry-run オプションを使用して、事前設定されたコマンドラインを生成します。 オプションは以下を生成します。
- インテル® Advisor CLI の収集ワークフローのコマンド
- 指定された精度レベルに対応するコマンド
- MPI アプリケーションを解析するようにコマンドが設定されていません。MPI コマンドを手動で調整する必要があります。
注: 次のコマンドでは、コマンドを実行する前に myApplication をアプリケーションの実行可能ファイルのパスと名前に置き換えてください。アプリケーションが引数を必要とする場合、実行可能ファイル名の後にそれらを指定します。
ワークフローには次の手順が含まれます。
- --collect=offload アクションと --dry-run オプションを使用してコマンドを生成します。精度レベルとプロジェクト・ディレクトリー、およびアプリケーション実行可能ファイルへのパスを指定します。
例えば、myApplication アプリケーション向けに低精度のコマンドを生成するには以下を実行します。
- Linux* :
advisor --collect=offload --accuracy=low --dry-run --project-dir=./advi_results -- ./myApplication - Windows* :
advisor --collect=offload --accuracy=low --dry-run --project-dir=.\advi_results -- .\myApplication.exe
指定された精度レベル (前述のコマンドの場合は low (低)) でオフロードのモデル化の結果を取得するため、各解析ステップのコマンドリストが表示されます。
- Linux* :
- MPI アプリケーションを解析する場合: 生成されたコマンドラインを任意のテキストエディターにコピーして、MPI ツールを利用するようにコマンドを変更します。構文の詳細については、MPI アプリケーションを解析を参照してください。
- 生成されたコマンドをコマンドプロンプトまたはターミナルで 1 つずつ実行します。
オプション 2。システムでインテル® Advisor グラフィカル・ユーザー・インターフェイス (GUI) が利用でき、コマンドラインから MPI アプリケーションを解析する場合、事前設定されたコマンドラインを GUI から生成できます。
GUI で以下を生成します。
- インテル® Advisor CLI の収集ワークフローのコマンド
- 選択した精度レベルのコマンド: 事前定義された精度レベル、またはカスタム・プロジェクト構成のコマンドを実行する場合、追加の解析オプションを有効/無効にする場合
- インテル® MPI ライブラリーを使用して MPI アプリケーション向けに設定されたコマンド。MPI アプリケーション構文のコマンドを手動で変更する必要はありません。
手順の詳細については、事前定義されたコマンドラインを生成を参照してください。
手法 1: 事前定義された収集を使用
オフロードのモデル化パースペクティブには、インテル® Advisor の特別な収集モード --collect=offload があり、単一のインテル® Advisor CLI コマンドで複数の解析を実行できます。収集を実行すると、データ収集とパフォーマンスのモデル化のステップが順番に実行されます。特定の解析とオプションは、収集に指定した精度レベルによって異なります。
注: 次のコマンドでは、コマンドを実行する前にmyApplicationをアプリケーションの実行可能ファイルのパスと名前に置き換えてください。アプリケーションが引数を必要とする場合、実行可能ファイル名の後にそれらを指定します。
例えば、オフロードのモデル化パースペクティブをデフォルト (中) 精度レベルで実行するには、次のコマンドを使用します。
- Linux* :
advisor --collect=offload --project-dir=./advi_results -- ./myApplication - Windows* :
advisor --collect=offload --project-dir=.\advi_results -- .\myApplication.exe
収集の進行状況と、実行された解析のコマンドがターミナル/コマンドプロンプトに出力されます。デフォルトでは、パフォーマンスはインテル® Arc™ グラフィックス (コード名 Alchemist (xehpg_512xve設定) 向けにモデル化されています。収集が完了すると、結果のサマリーが表示されます。
解析の詳細
実行する解析をそのオプションを変更するには、--accuracy=<level> オプションと同時に使用してください。デフォルトの精度レベルは medium (中) です。
次の精度レベルが利用できます。
- low (低)精度には、サーベイ、トリップカウント & FLOP 収集による特性化、およびパフォーマンスのモデル化解析が含まれます。
- Medium (中)(デフォルト) 精度には、サーベイ、トリップカウント & FLOP 収集による特性化、キャッシュとデータ転送シミュレーション、およびパフォーマンスのモデル化解析が含まれます。
- High (高)精度には、サーベイ、トリップカウント & FLOP 収集による特性化、キャッシュ、データ転送、メモリー・オブジェクト属性シミュレーション、およびパフォーマンスのモデル化解析が含まれます。CPU アプリケーションでは依存関係解析も含まれます。
CPU アプリケーションでは、精度レベルに依存関係解析が含まれるため、収集のオーバーヘッドが高くなります。アプリケーションが CPU 上で高度に並列化またはベクトル化されている場合、またはアプリケーションの主なホットスポットにループ伝搬依存がないことが判明している場合は、この解析を行う必要はありません。それ以外では、依存関係が GPU アプリケーションのパフォーマンスにどのような影響を与えるか確認するには、想定される依存関係がモデル化に影響するか確認を参照してください。
例: low (低) 精度レベルの解析を実行します。
advisor --collect=offload --accuracy=low --project-dir=./advi_results -- ./myApplicationhigh (高) 精度レベルの解析を実行します。
advisor --collect=offload --accuracy=high --project-dir=./advi_results -- ./myApplicationそれぞれの精度レベルで実行されるコマンドを確認する場合、--dry-run オプションを指定して収集を実行します。コマンドはターミナルまたはコマンドプロンプトに出力されます。
それぞれの精度レベルについては、コマンドラインでのオフロードのモデル化精度レベルを参照してください。
収集をカスタマイズ
カスタム構成でオフロードのモデル化を実行する場合、追加オプションを指定することもできます。ここでは、パフォーマンスのモデル化解析のほとんどのオプション (--collect=projection) と、オフロードのモデル化に有用なサーベイ、トリップカウント、および依存関係解析の一部のオプションを受け入れます。
重要
--accuracy オプションの後に追加するオプションを指定して、精度レベルの設定よりも優先されるようにします。次のオプションを検討してください。
オプション |
説明 |
|---|---|
--accuracy=<level> |
事前定義された収集の精度レベルを設定します。利用可能な精度レベル:
詳細は、コマンドラインでのオフロードのモデル化精度レベルを参照してください。 |
--config |
パフォーマンスをモデル化するターゲット GPU 構成を選択します。例:xehpg_512xve (デフォルト)、gen12_dg1、gen12_tgl、gen9_gt3。 利用可能な値のすべてのリストとデバイス名へのマッピングについては、config を参照してください。 |
--gpu |
GPU デバイス上の SYCL*、OpenCL*、または OpenMP* target アプリケーションを解析します。このオプションは、事前定義に含まれるそれぞれの解析で、関連するすべてのオプションを自動的に追加します。 このオプションを使用すると、高精度に依存関係解析が含まれまくなります。 このワークフローの詳細については、コマンドラインから GPU - GPU 間のパフォーマンスのモデル化を実行を参照してください。 |
--data-reuse-analysis |
コード領域間での潜在的なデータ再利用を解析します。このオプションは、事前定義に含まれるそれぞれの解析で、関連するすべてのオプションを自動的に追加します。 |
--enforce-fallback |
スタック収集が無効である場合、スタック全体のデータ分散をエミュレートします。このオプションは、事前定義に含まれるそれぞれの解析で、関連するすべてのオプションを自動的に追加します。 |
利用可能なその他のオプションの詳細は、collect を参照してください。
手法 2: 事前定義の収集を使用
インテル® Advisor CLI を使用して、個別のコマンドでそれぞれのオフロードのモデル化解析を実行し、アプリケーションのデータを収集してパフォーマンスをモデル化できます。このオプションは次を可能にしまします。
- アプリケーションのプロファイルで実行する解析と収集するデータを制御します。
- 多彩なオプションセットを使用して、実行する解析の動作を変更します。
- パフォーマンス・データを再収集することなく、パフォーマンスを再モデル化します。これにより、ベースラインと同じパフォーマンス・データを使用して、各種モデル化パラメーターでアプリケーションのパフォーマンスがどのように変化するか容易に確認できます。
- MPI アプリケーションのプロファイルとパフォーマンスのモデル化
次のワークフローの例について考えてみます。この例では、サーベイ、トリップカウント、および FLOP 解析を実行してアプリケーションをプロファイルし、パフォーマンスのモデル化を実行して、選択したターゲットデバイスでパフォーマンスをモデル化します。
注: 次のコマンドでは、コマンドを実行する前にmyApplicationをアプリケーションの実行可能ファイルのパスと名前に置き換えてください。アプリケーションが引数を必要とする場合、実行可能ファイル名の後にそれらを指定します。
Linux*:
- サーベイ解析を実行します。
advisor --collect=survey --static-instruction-mix --project-dir=./advi_results -- ./myApplication - デフォルトのインテル® Arc™ グラフィックス (コード名 Alchemist (xehpg_512xve設定) 向けにモデル化されています。
advisor --collect=tripcounts --flop --stacks --cache-simulation=single --target-device=xehpg_512xve --data-transfer=light --project-dir=./advi_results -- ./myApplication - オプション: 依存関係解析を実行して、ループ伝搬依存を確認します。
advisor -collect=dependencies --loop-call-count-limit=16 --select markup=gpu_generic --filter-reductions --project-dir=./advi_results -- ./myApplication依存関係解析には高い収集のオーバーヘッドが課せられます。アプリケーションが CPU 上で高度に並列化またはベクトル化されている場合、またはアプリケーションの主なホットスポットにループ伝搬依存がないことが判明している場合は、この手順を行う必要はありません。よく理解できない場合、想定される依存関係がモデル化に影響するか確認を参照して、依存関係が GPU 上のアプリケーションのパフォーマンスに与える影響を確認してください。
- デフォルトのインテル Arc™ グラフィックス (コード名 Alchemist (xehpg_512xve設定) 向けにモデル化されています。
advisor --collect=projection --project-dir=./advi_results結果のサマリーがコマンドプロンプトに出力されます。
ヒント解析結果がスナップショットまたは MPI ランクの結果として保存されている場合、 project-dir の代わりにexp-dirオプションを使用して、結果のパフォーマンスをモデル化できます。
Windows*:
- サーベイ解析を実行します。
advisor --collect=survey --static-instruction-mix --project-dir=.\advi_results -- .\myApplication.exe - デフォルトのインテル® Arc™ グラフィックス (コード名 Alchemist (xehpg_512xve設定) 向けにモデル化されています。
advisor --collect=tripcounts --flop --stacks --cache-simulation=single --target-device=xehpg_512xve --data-transfer=light --project-dir=.\advi_results -- .\myApplication.exe - オプション: 依存関係解析を実行して、ループ伝搬依存を確認します。
advisor -collect=dependencies --loop-call-count-limit=16 --select markup=gpu_generic --filter-reductions --project-dir=.\advi_results -- myApplication.exe依存関係解析には高い収集のオーバーヘッドが課せられます。アプリケーションが CPU 上で高度に並列化またはベクトル化されている場合、またはアプリケーションの主なホットスポットにループ伝搬依存がないことが判明している場合は、この手順を行う必要はありません。よく理解できない場合、想定される依存関係がモデル化に影響するか確認を参照して、依存関係が GPU 上のアプリケーションのパフォーマンスに与える影響を確認してください。
- デフォルトのインテル® Arc™ グラフィックス (コード名 Alchemist (xehpg_512xve設定) 向けにモデル化されています。
advisor --collect=projection --project-dir=.\advi_results結果のサマリーがコマンドプロンプトに出力されます。
ヒント収集された解析結果が MPI ランクのスナップショットまたは結果として保存されている場合、 project-dir の代わりにexp-dirオプションを使用して、結果のパフォーマンスをモデル化できます。
さらに有用なオプションについては、以下の解析の詳細を参照してください。
解析の詳細
オフロードのモデル化ワークフローには、次の解析が含まれます。
- 初期パフォーマンス・データを収集するための調査。
- 詳細なパフォーマンスを収集するため、トリップカウント & FLOP による特性化を行います。
- 依存関係 (オプション) は、オフロードを制限する可能性があるループ伝搬依存を特定します。
- パフォーマンスのモデル化は、選択したターゲットデバイスのパフォーマンスをモデル化します。
各解析には、その動作を変更して、追加のパフォーマンス・データを収集する一連の追加オプションがあります。実行する解析と使用するオプションが増えるほどモデル化の精度は高くなります。
次のオプションを検討してください。
サーベイオプション
次のコマンドラインのアクションを使用してサーベイ解析を実行します: --collect=survey。
推奨されるアクションのオプション:
オプション |
説明 |
|---|---|
--static-instruction-mix |
静的な命令ミックスデータを収集します。このオプションは、オフロードのモデル化パースペクティブに推奨されます。 |
--profile-gpu |
GPU デバイス上の SYCL*、OpenCL*、または OpenMP* target アプリケーションを解析します。 このオプションを使用すると、依存関係解析をスキップします。 このワークフローの詳細については、コマンドラインから GPU - GPU 間のパフォーマンスのモデル化を実行を参照してください。 |
特性化オプション
コマンドラインから特性化解析を実行するには、次のコマンドラインのアクションを使用します: --collect=tripcounts.
推奨されるアクションのオプション:
オプション |
説明 |
|---|---|
--flop |
AVX-512 プラットフォームの浮動小数点演算と整数演算、メモリー・トラフィック、およびマスク利用率メトリックに関連するデータを収集します。 |
--stacks |
コール・スタック・データの高度な収集を有効にします。 |
--cache-simulation=<mode> |
ターゲットデバイスのキャッシュ動作をシミュレートします。利用可能なモード:
|
--target-device=<target> |
キャッシュをモデル化するターゲットのグラフィックス処理ユニット (GPU) を指定します。例:xehpg_512xve (デフォルト)、gen12_dg1、または gen9_gt3。利用可能な値のすべてのリストとデバイス名へのマッピングについては、target-device を参照してください。 --cache-simulation=single オプションとともに使用します。 重要--collect=projection --config=<config> と同じターゲットデバイスを指定してください。 |
--data-transfer=<mode> |
ホストとターゲットデバイス間のデータ転送のモデル化を有効にします。次のモードを利用できます。
|
--profile-gpu |
GPU デバイス上の SYCL*、OpenCL*、または OpenMP* target アプリケーションを解析します。 このオプションを使用すると、依存関係解析をスキップします。 このワークフローの詳細については、コマンドラインから GPU - GPU 間のパフォーマンスのモデル化を実行を参照してください。 |
依存関係オプション
依存関係解析はオーバーヘッドが高いためオプションですが、アプリケーションにスカラーループ/関数がある場合、または主要なホットスポットにループ伝搬依存があるか不明な場合に必要となります。依存関係解析を行うべき状況の詳細については、想定される依存関係がモデル化に影響するか確認を参照してください。
コマンドラインから依存関係解析を実行するには、次のコマンドラインのアクションを使用します: --collect=dependencies。
推奨されるアクションのオプション:
オプション |
説明 |
|---|---|
--select=<string> |
解析するループを選択します。 オフロードのモデル化で推奨される値は、--select markup=gpu_generic です。これは、解析のオーバーヘッドを軽減するため、ターゲットデバイスへのオフロードに有益なループ/関数のみを選択します。 詳細については、解析のオーバーヘッドを最小化するループのマークアップを参照してください。 注SYCL*、OpenMP* target、または OpenCL* を使用しないアプリケーションの依存関係を解析する場合、generic (汎用) マークアップを推奨します。 |
--loop-call-count-limit=<num> |
異なる呼び出しインスタンスで同様の実行プロパティーを想定し、解析する呼び出しインスタンスの最大数を設定します。 推奨値は 16 です。 |
--filter-reductions |
すべての潜在的なリダクションと診断をマークします 。 |
パフォーマンスのモデル化オプション
パフォーマンスのモデル化解析を実行するには、次のコマンドラインのアクションを使用します: --collect=projection。
推奨されるアクションのオプション:
オプション |
説明 |
|---|---|
--exp-dir=<path> |
モデルのパフォーマンスを生成する場合、展開された結果スナップショットまたは MPI ランク結果へのパスを指定します。すでに解析結果が存在する場合、project-dir の代わりにこのオプションを使用します。 |
--config=<config> |
パフォーマンスをモデル化するターゲット GPU 構成を選択します。例:xehpg_512xve (デフォルト)、gen12_dg1、または gen9_gt3。 重要--collect=tripcounts --target-device=<target> と同じターゲットデバイスを指定してください。設定ファイルの詳細については、設定を参照してください。 |
--no-assume-dependencies |
ループの依存関係タイプが不明 (unknown) である場合、ループには依存関係がないと想定します。 アプリケーションに安全な並列ループやベクトル化されたループが含まれ、依存関係解析を実行しない場合はこのオプションを使用します。 |
--data-reuse-analysis |
ターゲット GPU にオフロードされた場合に、コード領域間でデータが再利用される可能性を解析します。 重要このオプションが正しく機能するには、--data-transfer=full を --collect=tripcounts とともに使用する必要があります。 |
--assume-hide-taxes |
呼び出しコストは、カーネルが最初に起動されるときにのみ発生すると仮定します。 |
--set-parameter |
変更する構成パラメーターを "<group>.<parameter>=<new-value>" 形式で指定します。例:"min_required_speed_up=0"。 オプションの詳細については、set-parameter を参照してください。変更可能な部分の詳細は、高度なモデル化設定を参照してください。 |
--profile-gpu |
GPU デバイス上の SYCL*、OpenCL*、または OpenMP* target アプリケーションを解析します。 このオプションを使用すると、依存関係解析をスキップします。 このワークフローの詳細については、コマンドラインから GPU - GPU 間のパフォーマンスのモデル化を実行を参照してください。 |
オプションについては、advisor コマンドオプションのリファレンスをご覧ください。
手法 3: Python* スクリプトを使用
インテル® Advisor には、インテル® Advisor Python* API を使用してオフロードのモデル化を行う 3 つのスクリプトが用意されています。スクリプトは、advisor-pythonコマンドライン・ツールまたはローカルの Python 3.6 または 3.7 で実行できます。
スクリプトの機能が異なり、異なるインテル® Advisor の解析を実行します。実行する内容に応じて、次のスクリプトを 1 度または複数回使用します。
- run_oa.pyは、変更の柔軟性が限定された最も単純なスクリプトです。このスクリプトを使用すると、収集とモデル化のステップを 1 つのコマンドで実行できます。このスクリプトは、インテル® Advisor 事前定義されたコマンドラインと同等です。
- collect.pyは、収集ステップのみを実行する適度に柔軟性のあるスクリプトです。
- Analyze.py は、パフォーマンスのモデル化ステップのみを実行する適度に柔軟性のあるスクリプトです。
注
このスクリプトは MPI アプリケーションの解析をサポートしません。MPI アプリケーションでは、インテル® Advisor CLI で解析ごとに収集を行います。スクリプトとインテル® Advisor CLI を組み合わせてオフロードのモデル化を実行することもできます。例:
- run_oa.py を実行してアプリケーションをプロファイルし、パフォーマンスをモデル化します。
- collect.py を実行してアプリケーションをプロファイルし、analyze.py を実行してパフォーマンスをモデル化します。analyze.py を再実行して異なる設定で再モデル化します。
- インテル® Advisor CLI を実行してパフォーマンス・データを収集し、analyze.py でパフォーマンスをモデル化します。analyze.py を再実行して異なる設定で再モデル化します。
- run_oa.py を実行して初期データを収集し、パフォーマンスをモデル化し、analyze.py を実行して異なる構成で再モデル化します。
次の例に示す、Python スクリプトを使用するいくつかの典型的なシナリオを検討してください。
注: 次のコマンドでは、コマンドを実行する前に myApplication をアプリケーションの実行可能ファイルのパスと名前に置き換えてください。アプリケーションが引数を必要とする場合、実行可能ファイル名の後にそれらを指定します。
例 1run_oa.py スクリプトを実行してアプリケーションをプロファイルし、インテル® Arc™ グラフィックス (コード名 Alchemist (xehpg_512xve 構成)) のパフォーマンスをモデル化します。
- Linux*:
advisor-python $APM/run_oa.py ./advi_results --collect=basic --config=xehpg_512xve -- ./myApplication - Windows*:
advisor-python %APM%\run_oa.py .\advi_results --collect=basic --config=xehpg_512xve -- .\myApplication.exe
結果のサマリーがコマンドプロンプトに出力されます。
さらに有用なオプションについては、以下の解析の詳細を参照してください。
例 2collect.py スクリプトを実行してアプリケーションをプロファイルし、analyze.py を実行してインテル® Arc™ グラフィックス (コード名 Alchemist (xehpg_512xve 構成)) のパフォーマンスをモデル化します。
- Linux*:
- パフォーマンス・データを収集します。
advisor-python $APM/collect.py ./advi_results --collect=basic --config=xehpg_512xve -- ./myApplication - アプリケーション・パフォーマンスのモデル化。
advisor-python $APM/analyze.py ./advi_results --config=xehpg_512xve
結果のサマリーがコマンドプロンプトに出力されます。
- パフォーマンス・データを収集します。
- Windows*:
- パフォーマンス・データを収集します。
advisor-python %APM%\collect.py .\advi_results --collect=basic --config=xehpg_512xve -- .\myApplication.exe - アプリケーション・パフォーマンスのモデル化。
advisor-python %APM%\analyze.py .\advi_results --config=xehpg_512xve
- パフォーマンス・データを収集します。
さらに有用なオプションについては、以下の解析の詳細を参照してください。
解析の詳細
各スクリプトには、その動作を変更して追加のパフォーマンス・データを収集する一連の追加オプションがあります。実行する解析と使用するオプションが増えるほどモデル化の精度は高くなります。
収集オプション
次のオプションは、run_oa.pyとcollect.pyスクリプトに適用できます。
オプション |
説明 |
|---|---|
--collect=<mode> |
アプリケーションで収集するデータを指定します。
依存関係データを収集する必要がある場合、想定される依存関係がモデル化に影響するか確認 を参照してください。 |
--config=<config> |
パフォーマンスをモデル化するターゲット GPU 構成を選択します。例:xehpg_512xve (デフォルト)、gen12_dg1、または gen9_gt3。 重要collect.py では、analyze.py の --config オプションと同じ値を指定します。設定ファイルの詳細については、設定を参照してください。 |
--markup=<markup-mode> |
事前定義されたマークアップ・アルゴリズムを使用して、トリップカウント & FLOP、および依存関係データを収集するループを選択します。このオプションは、収集のオーバーヘッドを軽減します。 デフォルトは、genericに設定されています。 |
--gpu |
GPU デバイス上の SYCL*、OpenCL*、または OpenMP* target アプリケーションを解析します。 このワークフローの詳細については、コマンドラインから GPU - GPU 間のパフォーマンスのモデル化を実行を参照してください。 |
利用可能なオプションについては、以下を参照してください。
パフォーマンスのモデル化オプション
次のオプションは、run_oa.pyとanalyze.pyスクリプトに適用できます。
オプション |
説明 |
|---|---|
--config=<config> |
パフォーマンスをモデル化するターゲット GPU 構成を選択します。例:xehpg_512xve (デフォルト)、gen12_dg1、または gen9_gt3。 重要analyze.py では、collect.py の --config オプションと同じ値を指定します。設定ファイルの詳細については、設定を参照してください。 |
--assume-parallel |
ループの依存関係タイプに関する情報がなく、依存関係解析を実行しなかった場合、ループには依存関係がないと想定されます。 |
--data-reuse-analysis |
ターゲット GPU にオフロードされた場合に、コード領域間でデータが再利用される可能性を解析します。 重要collect.py で解析を実行するには --collect=full を使用し、collect.pyインテル® Advisor CLI でトリップカウント解析を実行する場合、--data-transfer=full を使用します。 |
--gpu |
GPU デバイス上の SYCL*、OpenCL*、または OpenMP* target アプリケーションを解析します。 このワークフローの詳細については、コマンドラインから GPU - GPU 間のパフォーマンスのモデル化を実行を参照してください。 |
利用可能なオプションについては、以下を参照してください。
次のステップ
オフロードのモデル化の結果の調査を続行します。メトリックのレポートに関する詳細は、アクセラレーターのメトリックをご覧ください。