オフロードのモデル化パースペクティブを実行して、コードをオフロード/実行する影響の大きな可能性を検出し、ターゲットのグラフィックス処理ユニット (GPU) 上での潜在的なパフォーマンス・ボトルネックを特定します。
オフロードのモデル化パースペクティブを使用すると、次のことが可能になります。
- CPU で実行されるコードでは、実際のハードウェアで実行する前に、コードをターゲットデバイスにオフロードの価値があるかを判断し、潜在的なスピードアップの可能性を予測できます。
- GPU で実行されるコードでは、実際のハードウェアで実行する前に、異なるターゲットデバイスでコードを実行する際の潜在的なスピードアップの可能性を予測できます。
- ベースライン CPU からターゲット GPU へのオフロードに氏y相されるループを特定できます。
- ターゲットデバイス上の潜在的なパフォーマンスのボトルネックを検出して、最適化の方針を決定できます。
- ホストとターゲットデバイス間でデータがどの程度効率良く転送できるか確認できます。
オフロードのモデル化パースペクティブでは、次のワークフローが利用できます。
- CPU - GPU 間のオフロードのモデル化:
- C/C++ と Fortran アプリケーション: アプリケーションを解析し、ターゲット GPU デバイス上でそのパフォーマンスをモデル化します。このワークフローを使用して、オフロードの可能性を検出し、GPU へ効率良くオフロードするコードを準備します。
- SYCL*、OpenMP* target、および OpenCL* アプリケーション: CPU にオフロードされたアプリケーションを解析し、ターゲット GPU デバイス上でパフォーマンスをモデル化します。このワークフローでは、ターゲット GPU でアプリケーションのパフォーマンスを向上する方法を理解し、さらにオフロード可能なコードがあるかどうか確認します。これはホスト上で実行され、CPU にオフロードされたアプリケーション領域を解析します。
- SYCL*、OpenMP*target、OpenCL* アプリケーションの GPU - GPU 間のオフロードのモデル化: GPU で実行されるアプリケーションを解析し、異なる GPU デバイス上でのパフォーマンスをモデル化します。このワークフローでは、パフォーマンスを向上する方法を理解し、アプリケーションを別の GPU デバイスにオフロードすることでスピードアップできるか確認します。
注
アプリケーションのパフォーマンスはインテル® GPU でのみモデル化できます。どのように動作するか
オフロードのモデル化パースペクティブには次の手順で実行します。
- サーベイ解析を実行して、アプリケーションのベースラインとなるパフォーマンス・データを取得します。
- 特性化解析を実行して、カーネルが呼び出され実行される回数と、浮動小数点および整数操作の数を特定します。
- 依存関係解析 (CPU - GPU モデル化のみ) を実行して、注目するループをマークし、並列実行をブロックするループの依存関係を特定します。
- パフォーマンスのモデル化を実行して最も収益性の高い領域からスピードアップに取り組みます。アムダールの法則に従い、ターゲットデバイス上のプログラムのスピードアップとその他のパフォーマンス・メトリックを推測します。ターゲットでの実行時間がホストでの実行時間よりも短い場合、その領域は利益をもたらします。
CPU - GPU、および GPU - GPU 間のモデル化のワークフローは、各種ハードウェア構成、コンパイラーのコード生成原理、およびソフトウェア実装の観点から、アプリケーションのベースライン・デバイス固有の正確なモデル化を行います。ワークフローの次の機能を確認します。
CPU - GPU 間のモデル化 |
GPU - GPU 間のモデル化 |
|---|---|
CPU で実行、またはオフロードされるループ/関数のみを解析します。 |
GPU 計算カーネルのみが解析されます。 |
ループ/関数の特性は、CPU プロファイル機能を使用して測定されます。 |
計算カーネルの特性は、GPU プロファイル機能を使用して測定されます。 |
ターゲット GPU へのオフロードには、収益性の高いループ/関数のみが推奨されます。収益性は推測されるスピードアップに基づいています。 |
GPU で実行されるすべてのカーネルは、スピードアップの期待値が低い場合でも、1 対 1 でモデル化されます。 |
コールスタック処理、キャッシュおよびデータ転送シミュレーション、依存関係解析など、オーバーヘッドの高い機能を有効にできます。依存関係解析を使用して、ループ伝搬依存が CPU パフォーマンスに影響を与えるか確認する必要があります。 |
コールスタック処理、キャッシュおよびデータ転送シミュレーション、依存関係解析など、オーバーヘッドの高い機能を無効にできます。依存関係解析を行う必要はありません。 |
ベースライン・デバイスとターゲットデバイス間のデータ転送は、容量ベースとメモリー・オブジェクト・ベースの 2 つの異なるモードでシミュレートできます。 |
ホストとデバイスのメモリー間で転送されるメモリー・オブジェクトがトレースされます。 |
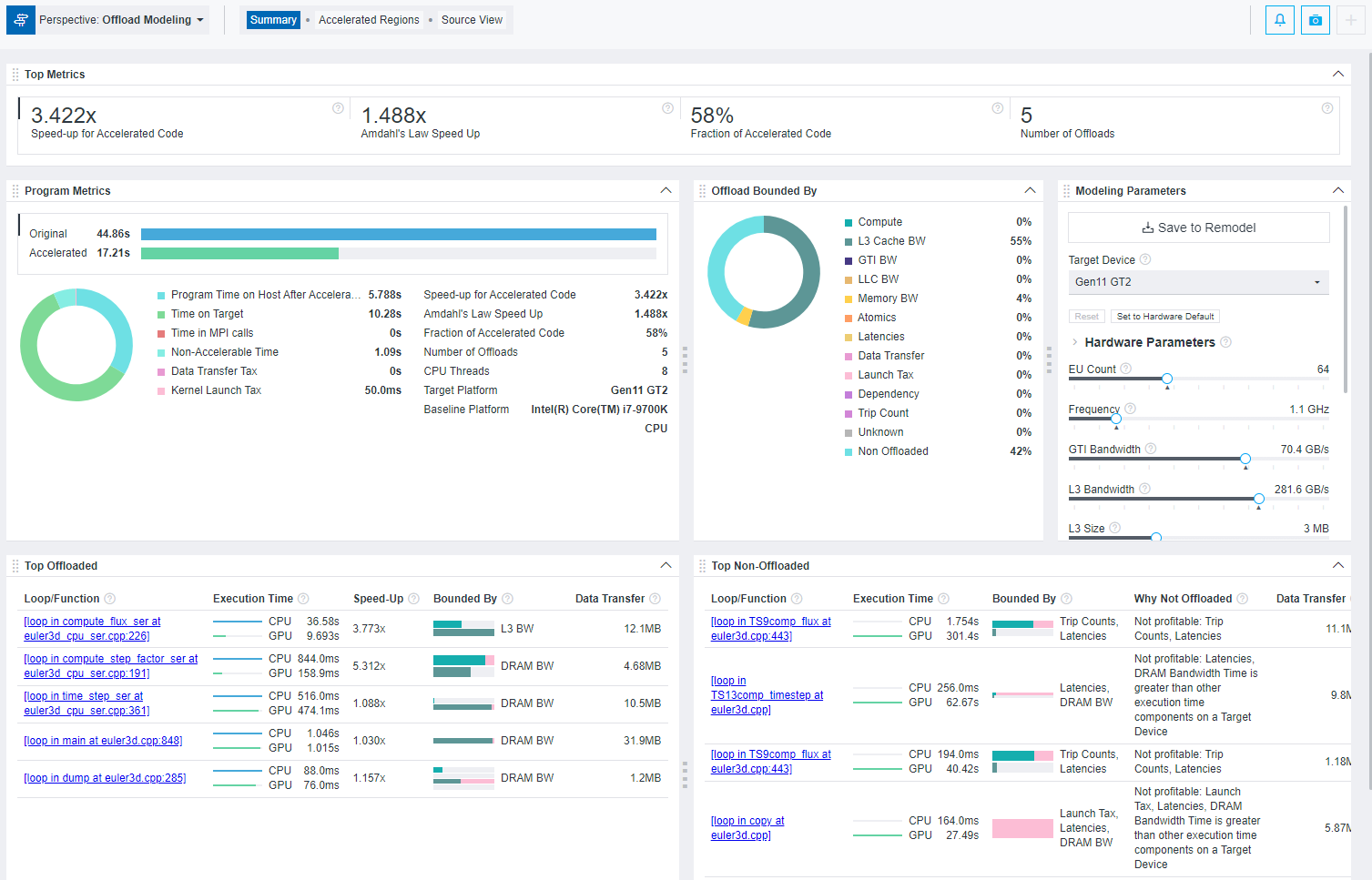
オフロードのモデル化サマリー
オフロードのモデル化パースペクティブでは、アプリケーションのパフォーマンスを測定して、選択したターゲット GPU でモデル化されたパフォーマンスと比較を行います。これにより、アプリケーションのどの領域が GPU で実行可能であるか、またオフロード後にパフォーマンスを向上するにはどのように最適化を行うか決定できます。
- アプリケーションのホットスポットをターゲットデバイスにオフロードする価値があるかを示す、プログラムのモデル化されたパフォーマンス・メトリック。
- ターゲットデバイスで実行したコードのパフォーマンス向上を妨げる特定の要因を示します (コードが制限される要因)。
- 最大限の利点を得られる上位 5 つのオフロードされたループ/関数。
- CPU から GPU へのモデル化: オフロードされない上位のループ/関数 (最大 5 つ) と、ループがオフロードされない理由。